Author: Denis Avetisyan
A new framework tackles the challenging problem of forecasting the movements of partially hidden agents, crucial for safe and reliable autonomous driving.

MatchInformer leverages Hungarian matching within a transformer network to improve occupancy prediction and trajectory forecasting for occluded agents.
Accurate prediction of occluded agents remains a critical challenge for autonomous vehicle safety, yet current methods often produce redundant detections of the same hidden entity. This work, titled ‘Don’t double it: Efficient Agent Prediction in Occlusions’, introduces MatchInformer, a novel transformer-based framework that leverages Hungarian Matching to enforce one-to-one correspondence between predicted and ground truth agents. By decoupling heading from motion and utilizing the Matthews Correlation Coefficient for robust evaluation, MatchInformer demonstrably improves both occupancy prediction and trajectory forecasting in sparse, imbalanced scenarios. Could this approach unlock more reliable reasoning about dynamic environments and ultimately enhance the safety of self-driving systems?
The Illusion of Prediction: Why We Chase Trajectories
The reliable operation of autonomous systems-from self-driving vehicles to collaborative robots-hinges on the ability to accurately forecast the future positions and spatial extent of other agents in the environment. However, this predictive capability is significantly hampered by the inherent complexities of real-world scenarios. Occlusion-where agents are temporarily hidden from view by obstacles-creates gaps in observational data, forcing systems to extrapolate motion based on incomplete information. Simultaneously, complex interactions between multiple agents-such as pedestrian negotiations or vehicular merging-introduce non-linear dynamics that defy simple modeling. Consequently, even minor inaccuracies in trajectory or occupancy prediction can lead to critical safety concerns, demanding robust algorithms capable of navigating these persistent challenges and effectively reasoning under uncertainty.
Existing approaches to predicting the movement of agents – be they pedestrians, vehicles, or robots – often falter when faced with the inherent unpredictability of real-world scenarios. These methods frequently treat prediction as a deterministic problem, struggling to quantify the uncertainty arising from occluded views, ambiguous intentions, and the complex interplay between multiple agents. Consequently, extrapolating motion becomes unreliable, particularly in dynamic environments where rapid changes are common. This limitation poses significant safety concerns for autonomous systems relying on these predictions; a miscalculation could lead to collisions, near misses, or inefficient navigation. Improving the capacity to reason about uncertainty isn’t merely about refining accuracy, but about building robustness and ensuring safe operation in the face of the unexpected.
Successfully navigating real-world environments requires more than simply tracking an agent’s current position; it demands a sophisticated understanding of behavioral subtleties. Current predictive models often fall short because they struggle to interpret the myriad of factors influencing decision-making – from subtle shifts in body language indicating intent, to the unspoken “rules of the road” governing pedestrian interactions. Capturing these nuances necessitates models capable of learning complex, high-dimensional relationships within observational data, and extrapolating plausible future actions even amidst uncertainty. The pursuit of high fidelity prediction isn’t merely about improving accuracy; it’s about building autonomous systems that can reason about the world with a level of social intelligence comparable to that of a human, enabling safe and effective navigation within genuinely dynamic and unpredictable scenarios.

SceneInformer: A Transformer-Based Foundation (And Its Limits)
SceneInformer employs the Transformer architecture, a neural network design originally developed for natural language processing, to process and predict dynamic scene data. This implementation utilizes the Transformer’s self-attention mechanism to model relationships between different elements within a scene, enabling the simultaneous prediction of both occupancy – the spatial volume occupied by objects – and trajectories – the future paths of those objects. Encoding involves transforming raw sensor data into a latent representation, while decoding reconstructs future scene states based on this representation. The model’s ability to effectively capture long-range temporal dependencies through attention allows for more accurate forecasting compared to recurrent neural networks traditionally used in this domain.
SceneInformer employs a sequence-to-sequence (seq2seq) architecture to explicitly model temporal relationships within scene data. This approach treats observed scene states as an input sequence and predicts future states as an output sequence. The model encodes the historical data into a fixed-length vector representation, capturing the relevant temporal context, and then decodes this representation to generate forecasts of future occupancy and trajectories. By processing data as a sequence, SceneInformer can leverage the dependencies between consecutive time steps, enabling it to anticipate future states based on past observations and effectively perform multi-step prediction.
SceneInformer’s initial implementation utilized pointwise convolutions for feature extraction and processing of scene data; however, these operations exhibited significant computational cost, particularly with increasing scene complexity and sequence lengths. The pointwise nature of these convolutions, while effective at capturing local features, required a substantial number of parameters and floating-point operations. This computational burden limited scalability and real-time performance, motivating research into alternative convolution strategies and architectural optimizations to reduce the model’s resource demands without compromising predictive accuracy. Subsequent development focused on exploring sparse convolutions and alternative attention mechanisms to alleviate this computational bottleneck.
SceneInformer employs a Grid-based Occupancy approach to represent the spatial extent and configuration of objects within a scene. This method discretizes the environment into a three-dimensional grid, with each cell indicating the presence or absence of an occupied space. Occupancy is typically represented as a binary value – 1 for occupied and 0 for free space – although probabilistic representations assigning a confidence level to each cell are also possible. This grid-based representation facilitates efficient processing and allows the model to reason about spatial relationships and potential collisions, forming a foundational component for trajectory prediction and scene understanding. The resolution of the grid directly impacts both computational cost and the fidelity of the occupancy representation.
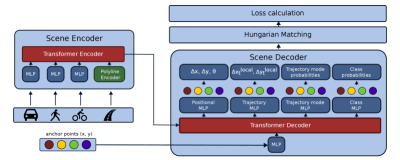
MatchInformer: A Clever Patch, Not a Revolution
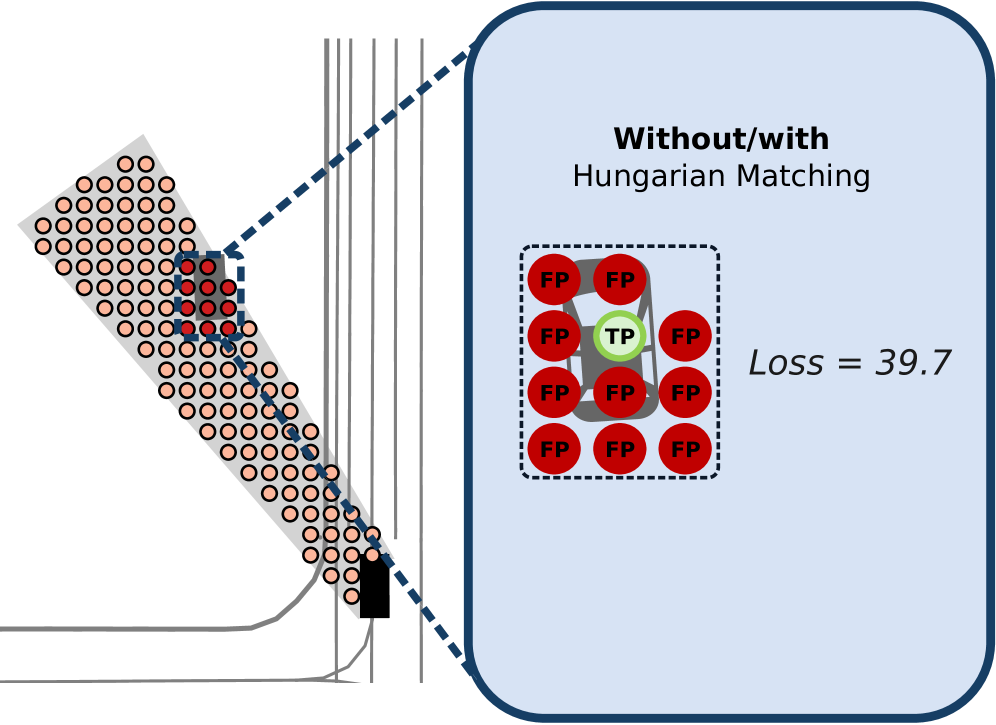
MatchInformer builds upon the SceneInformer architecture by incorporating Hungarian Matching as a post-processing step to improve the alignment between predicted agent trajectories and their corresponding ground truth observations. This matching algorithm addresses the challenge of correctly associating predictions with actual agent movements, particularly in scenarios with complex interactions and multiple agents. Specifically, Hungarian Matching seeks to minimize a cost matrix representing the discrepancy between predicted and observed states, effectively assigning each predicted trajectory to the most likely ground truth trajectory based on a defined distance metric. This refined association improves the accuracy of evaluation metrics and enhances the overall performance of trajectory prediction by ensuring a correct one-to-one correspondence between predictions and observations.
The optimization step within MatchInformer utilizes Hungarian Matching to directly address the assignment problem between predicted agent trajectories and their corresponding ground truth observations. This process minimizes the overall loss function by iteratively refining the association matrix, ensuring that each predicted trajectory is aligned with its most probable observed counterpart. Specifically, the algorithm seeks to minimize the cumulative cost – calculated from metrics like Final Displacement Error (FDE) and Average Displacement Error (ADE) – associated with mismatched predictions and ground truth, thereby reducing prediction error and improving the accuracy of trajectory forecasting. This direct optimization of assignment contributes to a more robust and reliable prediction framework.
MatchInformer improves computational efficiency by substituting pointwise convolutional layers with fully connected layers within its architecture. Pointwise convolutions, while effective, introduce a substantial number of parameters and associated computational cost. Fully connected layers, in this implementation, offer a comparable level of representational capacity with a reduced parameter count and streamlined processing. This modification results in significant speed improvements during both training and inference without incurring a measurable decrease in prediction accuracy, as demonstrated by maintained or improved minFDE and minADE scores compared to SceneInformer.
Evaluations demonstrate that MatchInformer yields substantial improvements in trajectory prediction accuracy when contrasted with SceneInformer. Specifically, the model achieves up to an 18% reduction in minimum Final Displacement Error (minFDE), a metric representing the shortest distance between the predicted and ground truth trajectories at the final time step. Furthermore, MatchInformer exhibits up to a 12% decrease in minimum Average Displacement Error (minADE), which quantifies the average displacement between predicted and observed trajectories across all time steps and agents. These gains indicate a more precise and reliable prediction of agent movements within complex scenes.
MatchInformer is designed to perform multiclass classification of agents within complex scenes, enabling differentiation between various agent types such as pedestrians, vehicles, and cyclists. This classification is a foundational component of the model, informing trajectory prediction by allowing it to account for the differing behavioral patterns associated with each agent class. The model achieves this through a classification head integrated with the scene encoding, allowing for simultaneous prediction of both agent class and future trajectory. Accurate multiclass classification is critical for effective trajectory prediction in diverse and crowded environments, and is a key differentiator for MatchInformer’s performance.
The Devil is in the Imbalance: Why Metrics Matter
Many real-world datasets, particularly those used in fields like robotics and autonomous navigation, suffer from a phenomenon known as class imbalance. This occurs when the distribution of classes within the data is highly skewed, meaning some categories or agent types are far more prevalent than others. For instance, a dataset tracking pedestrian and cyclist movement might contain a vast number of pedestrian instances but comparatively few cyclists. This disparity poses a significant challenge for machine learning algorithms, as they tend to be biased towards the majority class, leading to poor performance in identifying and predicting the rarer, yet potentially critical, classes. Consequently, algorithms may struggle to accurately detect less frequent agent types, hindering the reliability and safety of systems relying on this data for decision-making.
The inherent difficulty in accurately predicting infrequent categories within a dataset presents a significant challenge for machine learning models. When one or more classes are represented by a small fraction of the total data, standard classification algorithms tend to favor the majority classes, often leading to poor performance on the rare classes. This bias arises because the model optimizes for overall accuracy, and misclassifying a few instances of a rare class has a minimal impact on the overall score. Consequently, models may consistently predict the more frequent classes, effectively ignoring the less common ones – a problematic outcome when accurate identification of these rare classes is critical, such as in anomaly detection or identifying specific, vulnerable populations.
Traditional classification metrics like accuracy can be misleading when datasets suffer from class imbalance, often favoring the majority class. MatchInformer addresses this challenge by employing the Matthew Correlation Coefficient (MCC) as its primary evaluation metric. Unlike accuracy, MCC considers true and false positives and negatives, providing a balanced measure of predictive performance even when classes are disproportionately represented. This is particularly crucial in scenarios like robotic navigation, where correctly identifying rare but critical agent types – such as pedestrians or vulnerable road users – is paramount. The use of MCC allows for a more nuanced assessment of the model’s ability to generalize and avoid biased predictions, ultimately enhancing the reliability of its classifications in real-world applications where data imbalances are common.
The MatchInformer model demonstrably enhances classification accuracy when confronted with imbalanced datasets, achieving improvements of up to 74% as quantified by the Matthew Correlation Coefficient (MCC). This substantial gain signifies a marked advancement over traditional methods often hampered by their inability to effectively discern infrequent, yet critical, agent types. The MCC, a balanced metric sensitive to both true and false positives and negatives, provides a more reliable evaluation than standard accuracy measures in scenarios where classes are disproportionately represented. Consequently, MatchInformer’s performance underscores its potential for applications demanding precise identification of rare events or entities, such as anomaly detection or the reliable prediction of infrequently occurring environmental factors.
A key strength of the model lies in its ability to drastically reduce false positive predictions when determining occupancy – a crucial factor for ensuring safe navigation in dynamic environments. Erroneously identifying an area as occupied when it is, in fact, clear presents a significant hazard, potentially leading to unnecessary stops or even collisions. By prioritizing the minimization of these false positives, the model enhances the reliability of its predictions, fostering greater trust in its assessments of traversable space. This improved accuracy translates directly into safer and more efficient path planning for autonomous systems, as the model provides a more truthful representation of the surrounding environment and avoids reacting to nonexistent obstacles.

The Future Isn’t About Position, It’s About Intent
Accurate prediction of an agent’s future path hinges not only on where it’s going, but also on how it’s turning, making yaw rate – the rate of rotation around a vertical axis – a critical, yet often overlooked, component of trajectory forecasting. Incorporating yaw rate prediction allows the system to anticipate subtle changes in direction, particularly valuable in dynamic environments where rapid maneuvers are common. By modeling this rotational velocity, the system gains a more nuanced understanding of the agent’s intended motion, leading to more precise and reliable predictions of its future position. This is especially impactful in scenarios involving vehicles or pedestrians, where even small deviations in heading can drastically alter the predicted trajectory and potentially avert collisions. Effectively capturing and predicting yaw rate therefore represents a significant step towards more robust and safety-critical autonomous systems.
Accurate prediction of an agent’s future path hinges significantly on discerning its intended heading. This orientation, representing the direction the agent is facing, provides crucial insight into its likely maneuvers and destinations; a vehicle pointing towards an intersection, for example, signals a potential turn. Failing to account for heading drastically increases the risk of misinterpreting an agent’s intentions, potentially leading to collisions. Research indicates that incorporating heading information into trajectory forecasting models allows for more nuanced predictions, particularly in complex scenarios with multiple interacting agents. By effectively estimating where an agent intends to go, rather than simply where it could go, systems can proactively adjust their own behavior, ensuring safer and more efficient navigation in dynamic environments.
Modeling agent trajectories within a relative coordinate frame-one centered on the agent itself rather than a fixed global map-significantly enhances a system’s ability to generalize across varied and unpredictable environments. This approach decouples motion prediction from absolute positioning, allowing the system to focus on the relative changes in an agent’s state – its speed, direction, and turning radius – rather than needing to learn distinct behaviors for every location. Consequently, a system trained to predict movement in one scenario can readily adapt to new environments, differing viewpoints, and even interactions with previously unseen agents. This is because the fundamental principles of motion – acceleration, deceleration, and turning – remain consistent regardless of the absolute location within a space, offering a powerful mechanism for robust and scalable trajectory forecasting.
The pursuit of increasingly sophisticated trajectory forecasting holds the key to unlocking the full potential of autonomous systems. Ongoing research, building upon advancements in areas like yaw rate prediction, heading understanding, and relative coordinate modeling, isn’t simply about incremental improvements – it’s about establishing a foundation for truly reliable and adaptable robots. Future development will likely focus on combining these predictive capabilities with robust uncertainty estimation, allowing autonomous agents to not only anticipate the actions of others, but also to reason about the likelihood of those actions and plan accordingly. This holistic approach promises systems capable of navigating complex, dynamic environments with a level of safety and efficiency previously unattainable, ultimately paving the way for wider adoption across industries like transportation, logistics, and human-robot collaboration.

The pursuit of elegant solutions in trajectory prediction invariably collides with the messy reality of production. MatchInformer, with its Hungarian Matching and transformer networks, attempts to address occlusion reasoning-a noble goal. However, this framework, like all others, will inevitably accrue technical debt. The bug tracker will fill with edge cases missed during training, and unforeseen interactions will emerge. As Bertrand Russell observed, “The point of the universe is to perplex us.” This perplexity extends to autonomous driving; the system doesn’t predict perfectly-it makes informed guesses, constantly refined by the relentless feedback of real-world failures. It doesn’t solve occlusion; it manages the uncertainty.
The Road Ahead
MatchInformer, like all elegant constructions, solves a carefully defined problem. The performance gains regarding occluded agents are… predictable. Occupancy prediction, framed as a matching exercise, sidesteps the fundamental issue: real-world sensor data is rarely neat enough for Hungarian algorithms to remain pristine. Any system relying on ‘stable’ matching hasn’t encountered sufficient adversarial examples yet. It’s a temporary reprieve, not a resolution.
The inevitable next step isn’t further refinement of transformer architectures-those are merely moving parts. The true bottleneck will be data. Specifically, data representing not just ‘normal’ occlusions, but the edge cases: the deliberately deceptive maneuvers, the sensor failures disguised as obstructions, the sheer chaos of mixed traffic. If a bug is reproducible, it confirms the system works-but also reveals the boundaries of its operation.
Future work will undoubtedly explore ‘self-healing’ mechanisms and end-to-end learning. Anything self-healing just hasn’t broken yet. The field will chase increasingly complex representations of uncertainty, conveniently forgetting that documentation is collective self-delusion. The pursuit of robust trajectory forecasting will continue, driven by the simple fact that production environments always find new and inventive ways to invalidate theoretical guarantees.
Original article: https://arxiv.org/pdf/2601.21504.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Trading Smarter: AI-Powered Execution Schedules
- Smarter Order Execution: How AI is Outperforming Wall Street’s Playbook
2026-02-01 08:17