Author: Denis Avetisyan
New research establishes a standardized benchmark for evaluating how well object detection systems hold up against adversarial attacks, revealing critical insights into effective defense strategies.
This review analyzes existing adversarial attacks and training methods for object detection, highlighting the importance of perceptual metrics and mixed adversarial training for building robust detectors.
Despite the increasing reliance on object detection in critical systems, evaluating the robustness of these models against adversarial attacks remains a significant challenge. This paper, ‘Benchmarking Adversarial Robustness and Adversarial Training Strategies for Object Detection’, addresses the lack of standardized evaluation by proposing a unified benchmark for assessing attack transferability and defense strategies. Our findings reveal a substantial lack of transferability for current adversarial attacks when moving from convolutional neural networks to vision transformers, and demonstrate that mixing high-perturbation attacks during adversarial training yields the most robust detectors. Ultimately, this work asks: how can we design truly resilient object detection systems prepared for the evolving landscape of adversarial threats?
The Illusion of Perception: Fragility in Modern Object Detection
Object detection, a critical component enabling machines to “see” and interpret images, has witnessed remarkable progress in recent years. Algorithms like YOLOv3, FasterRCNN, DETR, and DINO represent significant leaps forward, powering applications from self-driving cars to medical image analysis. Despite these advancements, these systems exhibit a surprising fragility. While achieving impressive accuracy on standard datasets, object detection models are demonstrably susceptible to even minor alterations in input images. This vulnerability isn’t a matter of simply increasing dataset size or computational power; it reveals a fundamental limitation in how these algorithms perceive and categorize visual information, raising concerns about their reliability in real-world deployments where malicious or naturally occurring distortions are common.
Modern object detection systems, despite achieving remarkable performance on benchmark datasets like COCODataset and VOCDataset, exhibit a surprising vulnerability to adversarial attacks. These attacks involve the introduction of carefully designed, often imperceptible, perturbations to input images, effectively “fooling” the detector. The consequences can be severe; studies demonstrate that even minimal alterations can lead to a dramatic reduction in detection accuracy, with some attacks causing a staggering 90% drop in mean Average Precision (mAP). This fragility isn’t due to a lack of learning, but rather the systems’ reliance on subtle statistical correlations within the training data, which adversarial perturbations exploit to create misclassifications or missed detections. Consequently, a seemingly flawless detection system can be rendered unreliable with changes undetectable to the human eye, raising critical concerns for real-world applications where safety and reliability are paramount.
Modern object detection systems, despite achieving remarkable accuracy on standard benchmarks, exhibit a fundamental fragility stemming from a lack of robustness to input perturbations. Research demonstrates that even alterations imperceptible to the human eye – carefully crafted noise or subtle pixel manipulations – can cause these systems to fail, leading to misclassifications or complete failure to detect objects. This vulnerability isn’t a matter of the system ‘seeing’ something incorrect, but rather a consequence of the high-dimensional decision boundaries learned during training; these boundaries can be easily crossed by carefully designed, minimal input changes. The implications extend beyond academic curiosity, raising serious concerns for applications in safety-critical areas such as autonomous driving and surveillance, where even momentary failures can have significant consequences. Addressing this fragility requires a shift towards developing detection models that are inherently more stable and less sensitive to minor input variations.
Peeking Under the Hood: Dissecting Adversarial Assaults
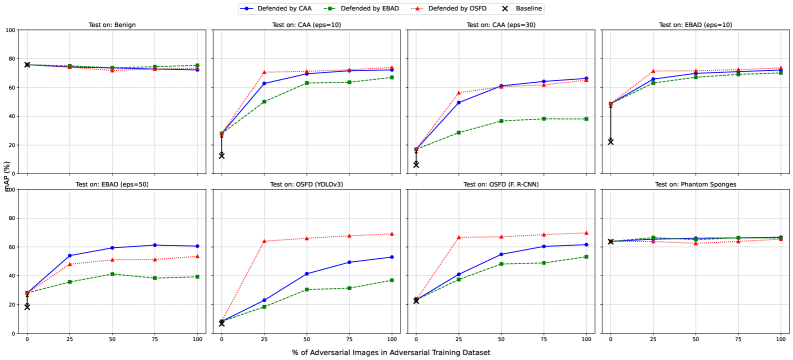
Adversarial attacks on object detection systems are implemented through a variety of distinct techniques, indicating a lack of a singular attack vector. Methods include Optimized Signed Gradient Descent (OSFD), Clean Adversarial Attacks (CAA), Evading Beam Attack with Data augmentation (EBAD), and the creation of “phantom sponges” which introduce misleading elements. The computational cost associated with these attacks varies considerably; for instance, OSFD requires approximately 44 seconds to generate an adversarial example for a single image, demonstrating that some attacks prioritize precision over speed. This diversity suggests that robust defenses must account for a broad spectrum of potential attack strategies, rather than focusing on mitigation of a single vulnerability.
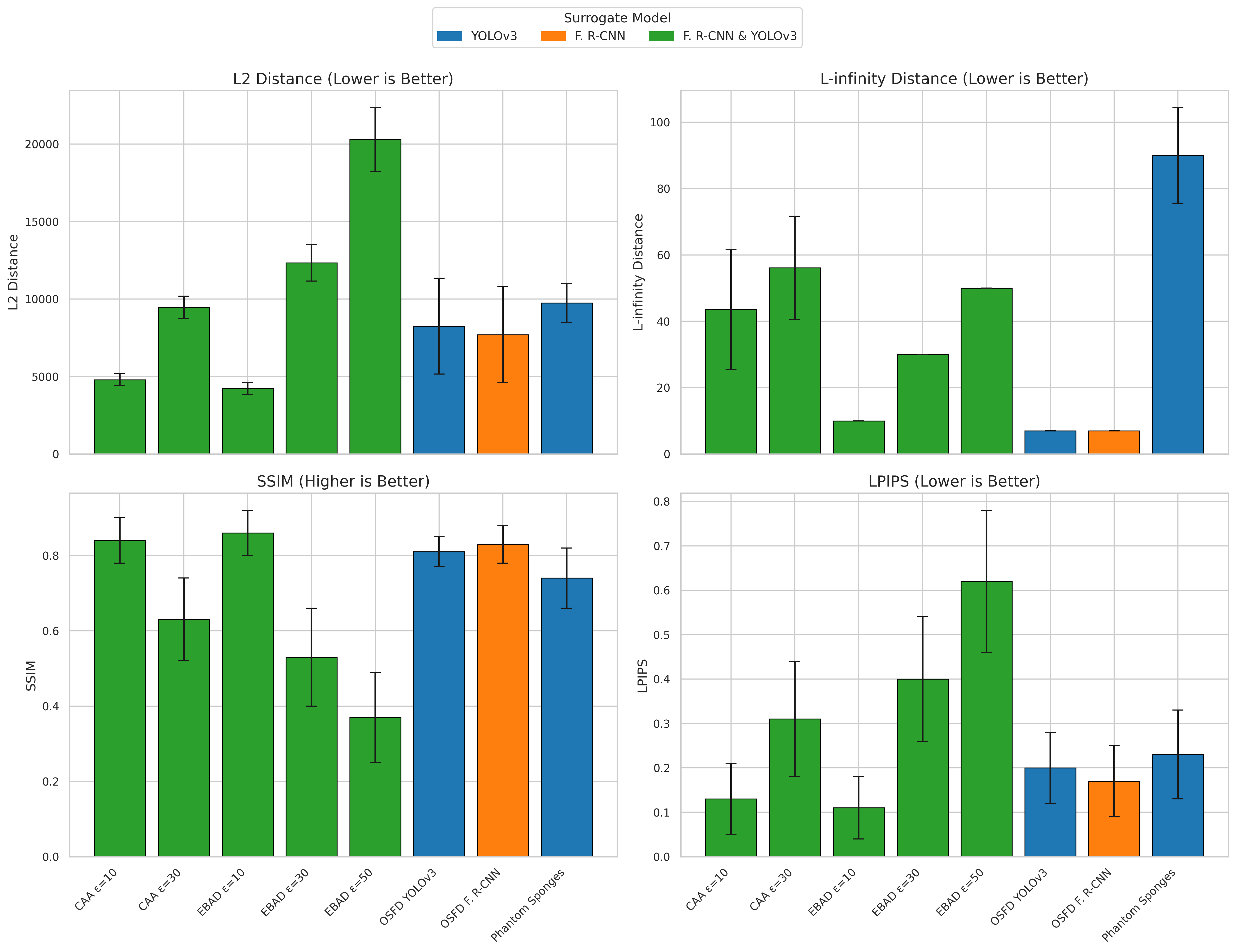
Adversarial attacks on object detection systems function by identifying and exploiting vulnerabilities within the model’s feature space. These attacks generate carefully crafted perturbations – subtle alterations to input data – designed to maximize the probability of misclassification. The magnitude of these perturbations is often constrained using mathematical norms such as L2Norm (Euclidean distance) and L\in fty Norm (maximum change in any single pixel). However, the L\in fty Norm, while computationally convenient, is a demonstrably poor indicator of perceptual similarity as measured by the Learned Perceptual Image Patch Similarity (LPIPS) metric; observed LPIPS scores range from 0.11 to 0.62, indicating that perturbations minimized by L\in fty Norm can still result in perceptually significant differences and successful adversarial attacks.
Object detection systems, while robust under normal conditions, exhibit a critical vulnerability stemming from their reliance on uncompromised input data. Adversarial attacks demonstrate that even imperceptible alterations to input images – crafted by exploiting the model’s feature space – can reliably induce misclassification or evasion of detection. This dependence necessitates detailed investigation into the mechanics of these attacks, including the specific perturbations applied and their impact on the model’s internal representations. Understanding these mechanisms is crucial for developing robust defense strategies and ensuring the reliable operation of object detection systems in potentially hostile environments.

Building Resilience: Towards Robust Object Detection
Adversarial training is a defense mechanism wherein object detectors are intentionally exposed to adversarial examples – inputs crafted to cause misclassification – during the training process. This technique aims to improve the detector’s resilience by forcing it to learn features less susceptible to subtle, malicious perturbations. By incorporating these challenging examples into the training dataset, the model learns to generalize better and maintain performance even when presented with intentionally deceptive inputs. The core principle is to minimize the loss function not only on clean data but also on these adversarial examples, effectively ‘inoculating’ the detector against future attacks.
The evolving nature of adversarial attacks requires continuous adaptation of object detection systems. While initial attacks proved effective against earlier architectures, research indicates limited transferability to modern transformer-based detectors, specifically DINO. This suggests that attack strategies must be refined to overcome inherent defenses in these newer models. Consequently, training strategies and defense mechanisms need ongoing updates to address newly developed attack methods and maintain robust performance against evolving threats. The lack of effective transfer observed in testing highlights a shifting landscape in adversarial robustness, necessitating a proactive and iterative approach to security.
Comprehensive evaluation of object detection robustness requires metrics beyond standard accuracy. Mean Average Precision (mAP) assesses overall detection performance, while Average Precision for Localization (APloc) specifically measures the accuracy of bounding box predictions, and Collision Score Rate (CSR) quantifies the frequency of false positives resulting from overlapping detections. Recent findings demonstrate that training detectors with a combination of adversarial examples generated by different attack strategies yields improved robustness; specifically, training on a mixed dataset comprised of OSFD and EBAD attacks resulted in a higher mAP compared to training on either attack dataset individually, indicating that complementary attacks expose the detector to a wider range of vulnerabilities and improve generalization.
Beyond Patches and Pixels: The Future of Robust Vision
Object detection systems frequently falter when confronted with adversarial attacks or novel environments, highlighting a critical need for improved generalization. Transfer learning presents a powerful solution by leveraging knowledge gained from training on one dataset and applying it to another, distinct scenario. This approach allows detectors to build a more comprehensive understanding of visual features, rather than memorizing specific training examples. Recent studies demonstrate that pre-training on large, diverse datasets – and then fine-tuning for a specific task – significantly enhances a detector’s ability to withstand both targeted attacks designed to fool the system and natural variations in lighting, viewpoint, or image quality. Consequently, transfer learning isn’t merely about improving accuracy; it’s about building systems that exhibit a more human-like capacity to recognize objects consistently, regardless of the circumstances, paving the way for more reliable and trustworthy computer vision applications.
Current object detection systems often fall prey to adversarial attacks – subtle image perturbations imperceptible to humans that cause misclassification. However, a growing body of research suggests that aligning machine perception with human perception is key to overcoming this vulnerability. Metrics like Learned Perceptual Image Patch Similarity (LPIPS) offer a quantifiable way to assess how closely a machine ‘sees’ an image compared to human judgment. LPIPS doesn’t simply measure pixel differences; instead, it leverages deep neural networks to extract features that correlate with human perceptual similarity, effectively gauging whether two images look alike. By incorporating LPIPS, or similar perceptual metrics, into the training process, developers can incentivize models to focus on semantically meaningful features rather than superficial details, resulting in detection systems that are not only more accurate but also demonstrably more robust against adversarial manipulation and more resilient to variations in lighting, viewpoint, and image quality.
Current object detection systems frequently fall prey to adversarial attacks and real-world perturbations because they heavily rely on identifying superficial visual features. A more resilient approach necessitates a fundamental shift towards models capable of genuine semantic understanding. Rather than simply recognizing patterns of pixels, these systems would need to grasp the underlying meaning and context of an image – discerning, for instance, that a slightly obscured stop sign is still a stop sign, even with altered texture or lighting. This requires moving beyond feature matching to incorporate higher-level reasoning and knowledge about the objects and scenes being analyzed, effectively mimicking human visual cognition which prioritizes ‘what’ an object is, over ‘how’ it looks at a specific moment. Such an approach promises detection systems that are not easily fooled by minor alterations and can generalize effectively across diverse and unpredictable environments.
The pursuit of adversarial robustness in object detection, as detailed in this benchmark, feels predictably Sisyphean. Researchers strive for detectors that withstand increasingly sophisticated attacks, yet the paper implicitly acknowledges that each ‘defense’ is merely a temporary reprieve. It’s a constant escalation, a relentless cycle of attack and counter-attack. As David Marr observed, “Representation is the key to intelligence.” This rings true; the more complex the representation-the detector’s attempt to ‘understand’ an image-the more avenues exist for subtle adversarial perturbations to exploit its vulnerabilities. The focus on perceptual metrics like LPIPS suggests an attempt to align machine perception with human perception, but even that’s a moving target. Better one rigorously tested, slightly flawed detector than a hundred theoretically robust ones that crumble under production’s unpredictable realities.
What Comes Next?
This exercise in standardized suffering – benchmarking adversarial robustness in object detection – predictably reveals that current defenses are, at best, temporary reprieves. The reported gains, while measurable, will inevitably succumb to a more inventive attack, or simply the scale of production deployments exposing edge cases never considered in controlled experiments. It’s a cycle, and the benchmark, useful as it is, merely provides a more precise measuring stick for the inevitable entropy.
The emphasis on perceptual metrics – LPIPS, in this instance – feels particularly… pragmatic. It acknowledges that perfect robustness is a fantasy. The goal isn’t to eliminate the adversarial noise, but to make it visually indistinguishable from natural variation. A statistically robust detector is, after all, a much easier problem than a semantically perfect one. The suggestion of mixed adversarial training is a familiar refrain: a little bit of everything to postpone the inevitable specialization of failure.
Future work will likely focus on automated defense generation – algorithms that endlessly chase the latest attack, perpetually patching the holes before production finds them. A Sisyphean task, naturally. But legacy is a memory of better times, and bugs are proof of life. The real question isn’t whether these detectors will fail, but how gracefully they’ll degrade.
Original article: https://arxiv.org/pdf/2602.16494.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The Best Directors of 2025
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Gold Rate Forecast
2026-02-19 12:20