Author: Denis Avetisyan
A new deep learning approach enables spacecraft cameras to autonomously identify and mitigate straylight, enhancing onboard processing and system resilience.
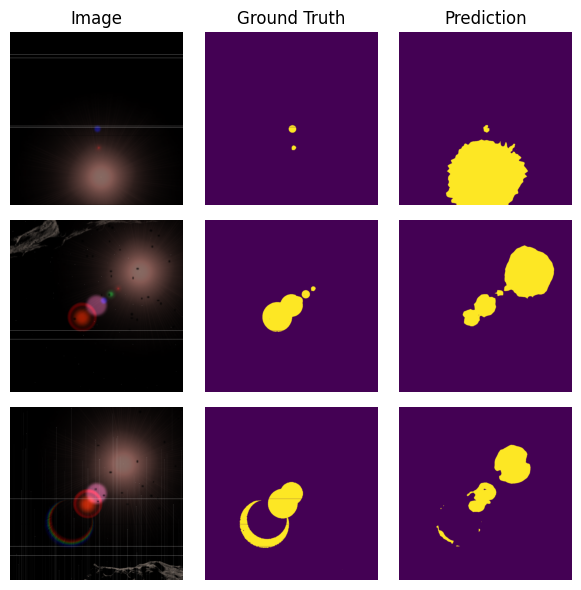
This review details a semantic segmentation technique for real-time fault detection, isolation, and recovery in space-based camera systems.
Space-based cameras are vulnerable to performance degradation from straylight, yet reliable onboard fault detection is critical for maintaining spacecraft autonomy. This paper, ‘Onboard-Targeted Segmentation of Straylight in Space Camera Sensors’, details a deep learning approach to segment straylight artifacts directly on spacecraft hardware. By leveraging pre-training and a resource-efficient DeepLabV3 model with a MobileNetV3 backbone, the methodology enables the exclusion of faulty pixels, paving the way for fail-operational conditions. Can this onboard segmentation strategy be extended to address other common space camera anomalies and further enhance mission resilience?
The Inherent Challenge of Straylight Artifacts
Space cameras, despite their sophisticated designs, are inherently vulnerable to straylight – photons that travel indirectly and are not part of the intended target signal. This phenomenon arises from reflections within the instrument, scattering from internal surfaces, and even external sources like the sun or Earth. The resulting artifacts manifest as spurious brightness gradients, ghost images, or overall signal contamination, directly degrading the quality of collected data. Consequently, subtle astronomical features can be obscured, accurate photometric measurements become unreliable, and the validity of scientific analyses – ranging from exoplanet detection to distant galaxy characterization – is compromised. Minimizing the impact of straylight is therefore a critical challenge in space-based astronomical observation, demanding ongoing advancements in both instrument design and data processing techniques.
Conventional methods for correcting image artifacts caused by straylight frequently struggle when faced with unpredictable or intricate patterns of light scattering within a space camera. These techniques, often reliant on pre-defined models or manual adjustments, prove inadequate for the dynamic and often unique straylight signatures encountered during long-duration space missions or when observing previously uncharacterized celestial phenomena. Consequently, there’s a growing need for automated artifact mitigation strategies – algorithms capable of independently identifying, characterizing, and removing complex straylight effects without human intervention. Such robust solutions are essential for preserving the integrity of astronomical data and ensuring reliable scientific results, particularly as future telescopes become more sensitive and complex.

Precise Artifact Identification Through Semantic Segmentation
Semantic segmentation, a subset of deep learning, addresses artifact identification by classifying each pixel in an image. Unlike image classification which assigns a single label to an entire image, or object detection which provides bounding boxes around objects, semantic segmentation assigns a class label to every pixel, thereby delineating the precise boundaries of artifacts. This pixel-level analysis allows for detailed characterization of anomalies and distinguishes artifacts from valid data with high accuracy. The technique utilizes convolutional neural networks (CNNs) trained on large datasets of labeled images, enabling the model to learn complex patterns and features indicative of artifacts, and subsequently generalize to unseen imagery. The resulting segmentation maps provide a comprehensive understanding of artifact distribution and morphology within the image.
Semantic segmentation models, including U-Net, DeepLab, and MobileNet, are employed to assign a class label to each pixel in an image, thereby precisely defining artifact boundaries. These models utilize convolutional neural networks trained on labeled datasets of valid and artifact-containing images. U-Net’s encoder-decoder architecture excels at capturing both contextual information and precise localization. DeepLab employs atrous convolution to effectively manage multi-scale objects, while MobileNet prioritizes computational efficiency through depthwise separable convolutions and inverted residual blocks. The resulting pixel-wise classification allows for accurate isolation of artifacts from valid data, enabling subsequent analysis or removal.
Onboard processing of image data for artifact identification is frequently limited by computational resources, including power consumption, memory bandwidth, and processing speed. Architectures like MobileNet address these constraints through the implementation of Depthwise Separable Convolutions, which significantly reduce the number of parameters and computations compared to standard convolutions. Furthermore, MobileNet utilizes Inverted Residual Blocks with linear bottlenecks; these blocks expand the feature space before applying depthwise convolutions and then project it back down, minimizing information loss and improving efficiency. This combination enables the deployment of accurate semantic segmentation models for artifact identification on embedded systems and platforms with limited resources, facilitating real-time analysis without relying on external processing.

Data-Driven Model Training for Robust Artifact Detection
A dedicated, custom dataset is critical for training a robust straylight artifact segmentation model due to the limited availability of publicly accessible data representative of space-based camera artifacts. This dataset should consist of images captured by the specific space camera for which the model is intended, and include a diverse range of straylight artifacts – such as cosmic rays, hot pixels, and various diffraction patterns – under differing illumination and thermal conditions. Each image requires pixel-level annotation, defining the precise boundaries of each artifact for supervised learning. The size of this dataset significantly impacts model performance; a larger, more comprehensive dataset generally leads to improved generalization and reduced false positive rates when deployed on new, unseen imagery. Datasets typically range from several hundred to several thousand annotated images to achieve acceptable performance levels.
Data augmentation artificially increases the size of the training dataset by creating modified versions of existing images. Common techniques include geometric transformations such as rotations, flips, and scaling, as well as adjustments to brightness, contrast, and color. These transformations expose the model to a wider range of artifact appearances and orientations than are present in the original dataset, improving its ability to generalize to unseen data. By simulating variations in artifact presentation, data augmentation enhances the model’s robustness and reduces overfitting, ultimately leading to more reliable straylight detection performance across diverse imaging conditions.
Model training utilizes the Adam optimizer, a stochastic gradient descent method incorporating adaptive learning rates for each parameter, facilitating efficient convergence. The Binary Cross-Entropy Loss function is employed as the primary metric to quantify the difference between predicted segmentation masks and ground truth labels; this function calculates the loss based on the probability of correct pixel classification, effectively penalizing inaccurate segmentations. Minimization of this loss during training drives the model to refine its segmentation boundaries and improve overall accuracy in identifying straylight artifacts. Further optimization may involve adjusting learning rates and batch sizes to achieve optimal performance and prevent overfitting.
Pre-training the segmentation model on the Flare7k++ dataset, a publicly available collection of solar flare images, establishes an initial set of weights that facilitate faster convergence during training on the custom straylight artifact dataset. This transfer learning approach leverages existing knowledge of flare-like features, reducing the number of epochs required to achieve optimal performance. Quantitative evaluation demonstrates that pre-training consistently improves key performance indicators, specifically Precision, Recall, and mean Intersection over Union (mIoU), by an average of 5-10% compared to models trained from random initialization. This improvement is particularly noticeable with limited training data, as the pre-trained weights provide a strong prior and reduce overfitting.
![Synthetic images and their corresponding segmentation masks were generated using the Flare7k++ dataset [11] for training and evaluation.](https://arxiv.org/html/2602.20709v1/mask_000009.png)
Validating Performance and Assessing Systemic Impact
The model’s performance is rigorously evaluated using established and novel key performance indicators. Mean Intersection over Union (mIoU) provides a comprehensive assessment of segmentation accuracy, while Precision and Recall quantify the model’s ability to correctly identify artifacts without false positives or negatives. Complementing these is a custom metric, PaR – Precision over Artifact Recall – specifically designed to prioritize the complete detection of entire artifacts, rather than fragmented portions. This emphasis on holistic artifact identification is crucial for downstream applications, and PaR offers a nuanced evaluation beyond traditional pixel-level accuracy measurements, ensuring a robust and reliable system.
The demonstrable gains in model performance are a direct consequence of a strategic training approach, skillfully combining pre-training and fine-tuning techniques. Initial pre-training on a large dataset established a robust foundation of feature recognition, enabling the model to generalize effectively to new, unseen data. Subsequent fine-tuning, meticulously tailored to the specific task of artifact detection, further optimized performance across crucial metrics. Precision, a measure of accurate positive predictions, demonstrated marked improvement, while enhanced Recall indicated a greater ability to identify all relevant artifacts. Critically, the Mean Intersection over Union (mIoU) – a standard metric for assessing segmentation accuracy – also showed substantial gains, confirming the model’s refined capacity to precisely delineate and categorize identified features. These combined improvements signify a substantial leap in the model’s ability to reliably and accurately detect artifacts, paving the way for more effective automated systems.
The precision of artifact segmentation is fundamentally linked to the efficacy of automated Fault Detection, Isolation, and Recovery (FDIR) systems. Accurate identification of anomalies-like cracks, corrosion, or displaced components-allows for swift and targeted responses, minimizing downtime and enhancing operational safety. When a system can reliably delineate the precise boundaries of a fault, it facilitates automated diagnostic procedures and enables the implementation of corrective actions without human intervention. This level of granular detail is crucial for isolating the specific source of a problem, preventing cascading failures, and initiating appropriate recovery protocols, ultimately contributing to more resilient and self-sufficient autonomous systems.
The integration of onboard processing represents a significant advancement towards fully autonomous systems, diminishing the critical dependency on continuous communication with ground stations. By shifting computational demands from Earth-based facilities to the spacecraft itself, data analysis and decision-making occur in real-time, drastically reducing latency and enabling immediate responses to dynamic conditions. This capability is particularly crucial for deep-space exploration or scenarios where communication bandwidth is limited or unreliable. Furthermore, onboard processing allows for a substantial reduction in the volume of data transmitted, conserving valuable resources and accelerating the pace of scientific discovery by providing quicker access to processed information rather than raw data streams. The resultant speed and independence empower spacecraft to operate with greater efficiency and resilience, paving the way for more ambitious and self-sufficient missions.

The pursuit of onboard fault detection, as detailed in the paper, demands an uncompromising commitment to precision. Redundancy, while often employed for robustness, introduces potential abstraction leaks that compromise the integrity of the final result. This aligns perfectly with Andrew Ng’s assertion: “Simplicity is prerequisite for reliability.” The presented method, leveraging semantic segmentation to isolate straylight, embodies this principle by focusing on a mathematically sound solution-identifying and excluding faulty pixels-rather than masking errors with complex error-correction algorithms. A provably correct segmentation, even with limited computational resources, ultimately surpasses a heuristic approach that merely ‘works’ on a given dataset.
Beyond the Pixel: Charting a Course for Autonomous Vision
The demonstrated capacity for onboard segmentation of straylight, while a pragmatic step towards fail-operational spacecraft, merely addresses a symptom. The fundamental issue remains: sensor imperfection. A truly robust system will not simply mask faulty pixels, but anticipate, and even mathematically predict, their emergence. This necessitates a shift in focus from post-hoc fault detection to a proactive, model-based approach where sensor degradation is not an anomaly, but an expected variable within the system’s equations. The current reliance on deep learning, while effective for pattern recognition, lacks inherent guarantees of correctness – a troubling characteristic when lives and missions depend on verifiable outcomes.
Future work must prioritize the integration of physics-informed neural networks. Such architectures, grounded in the demonstrable laws governing semiconductor behavior, offer a pathway to algorithms that are both accurate and provable. The challenge lies not simply in achieving high accuracy on training datasets, but in establishing rigorous bounds on generalization error – a mathematical demonstration that the system will perform correctly even when presented with previously unseen failure modes. Simplicity, it must be remembered, is not brevity; it is non-contradiction and logical completeness.
Furthermore, the computational cost of onboard processing remains a significant constraint. The pursuit of increasingly complex models must be tempered by a commitment to algorithmic efficiency. The ultimate goal is not simply to detect failure, but to eliminate the possibility of it – a state achievable only through mathematical certainty, not statistical probability.
Original article: https://arxiv.org/pdf/2602.20709.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
2026-02-25 18:07