Author: Denis Avetisyan
A new framework leverages the combined power of spectral and spatial information to improve regression tasks in hyperspectral imagery analysis.
This work introduces a spectral-spatial contrastive learning approach utilizing 3D convolutional networks and data augmentation to enhance regression performance on hyperspectral data.
While contrastive learning excels in representation learning for image classification, its application to regression tasks, particularly with hyperspectral data, remains underexplored. This limitation motivates the work presented in ‘Spectral-Spatial Contrastive Learning Framework for Regression on Hyperspectral Data’, which introduces a novel framework designed to enhance regression performance by effectively fusing spectral and spatial information. The proposed approach leverages tailored data augmentation strategies alongside model-agnostic integration with both 3D convolutional and transformer-based networks. Could this spectral-spatial contrastive learning paradigm unlock new capabilities in diverse hyperspectral data analysis applications, moving beyond classification to more nuanced predictive modeling?
Decoding Hyperspectral Complexity: Addressing the Challenges of Rich Data
Hyperspectral imagery, while capable of discerning remarkably detailed spectral signatures, faces inherent challenges in data acquisition and interpretation. Unlike conventional imagery which captures light in broad bands, HSI records hundreds of narrow, contiguous spectral bands, revealing a wealth of information about an object’s material composition. However, this sensitivity also means the data is highly susceptible to noise originating from atmospheric scattering, absorption, and variations in illumination. Furthermore, even subtle differences in material properties – surface roughness, moisture content, or minor compositional shifts – can significantly alter the recorded spectral response. Consequently, robust pre-processing and advanced analytical techniques are crucial to disentangle genuine spectral information from these confounding factors and accurately interpret the data, limiting the direct application of many conventional image processing methods.
The inherent complexity of hyperspectral imagery often hinders the reliable extraction of actionable data, despite its potential for detailed analysis. Traditional spectral analysis techniques, designed for simpler datasets, frequently falter when confronted with the subtle variations in spectral signatures caused by atmospheric interference, illumination changes, and the heterogeneous composition of materials. This limitation significantly impacts practical applications; for instance, accurate pollution monitoring requires differentiating between similar chemical compounds, a task made difficult by noisy data, while reliable material identification-crucial in fields like agriculture and defense-becomes compromised by the inability to consistently resolve nuanced spectral differences. Consequently, the full promise of hyperspectral data remains largely unrealized without advancements in analytical methodologies capable of overcoming these challenges.
Hyperspectral imagery, while incredibly detailed, generates datasets with hundreds of spectral bands for each pixel – a phenomenon known as the ‘curse of dimensionality’. This presents substantial computational hurdles; standard analytical techniques quickly become overwhelmed, requiring excessive processing time and memory. Consequently, researchers are actively developing innovative approaches – including dimensionality reduction algorithms like principal component analysis and machine learning methods – to efficiently manage and interpret these complex datasets. These techniques not only reduce computational load but also improve the signal-to-noise ratio, enabling more accurate material identification and environmental monitoring. Successfully tackling this dimensionality challenge is crucial for unlocking the full potential of hyperspectral data across diverse applications, from precision agriculture to geological surveying.
Expanding Data Horizons: Augmenting Reality Through Transformation
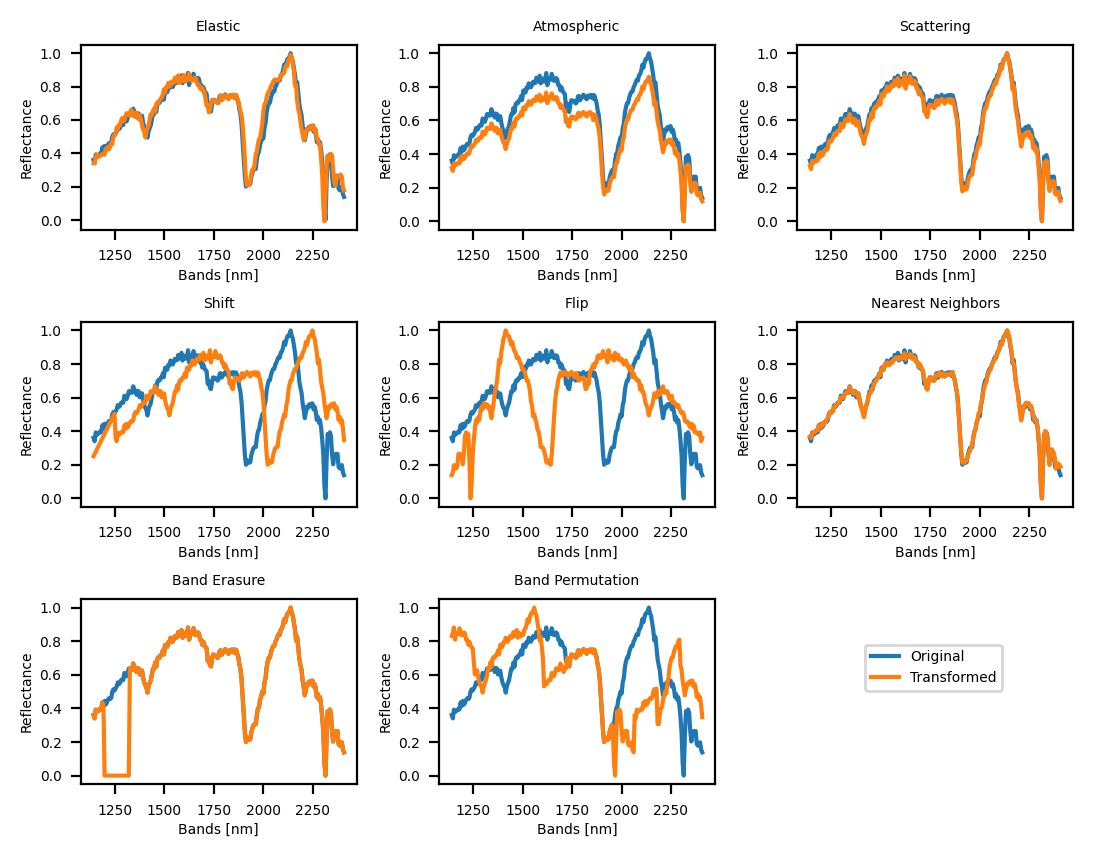
Data augmentation via spatial transformations artificially increases the size of a training dataset by creating modified versions of existing samples. Common techniques include flipping images horizontally or vertically, rotating them by specified angles, and translating them – shifting their position within the frame. These transformations do not add new information but expose the model to variations it might encounter in real-world scenarios. By training on this expanded, albeit synthetic, dataset, the model becomes more robust and generalizes better to unseen data, reducing overfitting and improving performance on tasks such as object detection and image classification.
Spectral augmentations mitigate the impact of spectral variability – minor fluctuations in the wavelengths of light reflected from a material – on model performance. Techniques such as Spectral Shift introduce controlled alterations to the spectral signature, while Band Erasure randomly masks specific frequency bands within the spectrum. Band Permutation reshuffles the order of these bands. These methods simulate realistic variations in material composition or illumination conditions, forcing the model to focus on core material properties rather than superficial spectral differences and thereby improving its robustness and generalization capabilities across diverse datasets.
Combining spatial and spectral data augmentation techniques offers a synergistic approach to enhancing model robustness. Spatial augmentations, which alter image geometry, address variations in object pose and viewpoint. Simultaneously, spectral augmentations mitigate the impact of subtle material differences and sensor noise by modifying the spectral characteristics of the data. This combined methodology is demonstrably more effective than applying either technique in isolation, as it addresses a broader range of potential real-world variations. The resulting models exhibit improved generalization capabilities and maintain higher performance levels when deployed in diverse and unpredictable environmental conditions, leading to more reliable and accurate predictions.
Unveiling Inherent Data Structure: A Contrastive Learning Approach
Contrastive Learning (CL) operates on the principle of bringing similar data points closer together in a feature space while pushing dissimilar points further apart. This is achieved by creating multiple “views” of each data instance – for example, different augmentations or transformations of the same image – and training the model to recognize these as representing the same underlying data. The resulting feature representations are designed to be invariant to these transformations, leading to more robust and generalizable models. By focusing on learning similarities and differences, CL avoids the need for explicit labels in many cases, enabling the use of unlabeled data for representation learning and improved performance on downstream tasks.
Spatial Contrastive Learning (SCL) leverages the inherent spatial context present in Hyperspectral Imagery (HSI) data to improve feature representation. Unlike methods treating each pixel independently, SCL considers the relationships between neighboring pixels during the training process. This is achieved by constructing positive pairs from spatially adjacent pixels within HSI data, and negative pairs from distant or unrelated pixels. By minimizing the distance between feature vectors of positive pairs and maximizing the distance between feature vectors of negative pairs, the model learns to recognize and encode spatial patterns and boundaries effectively. Consequently, SCL enhances the model’s ability to differentiate between regions with varying characteristics and improves performance in tasks requiring spatial understanding, such as target detection and scene classification.
Spectral Contrastive Learning (SCL) leverages the inherent spectral characteristics of Hyperspectral Imagery (HSI) to enhance material identification capabilities. This technique trains models to recognize similarities and differences in the electromagnetic spectrum reflected by various materials. By contrasting spectral signatures, the model learns to create robust feature representations that are less sensitive to variations in illumination or sensor noise. This focus on spectral information allows the model to effectively discriminate between materials with distinct spectral properties, ultimately improving the accuracy of material classification and regression tasks performed on HSI data.
Spectral-Spatial Contrastive Learning represents the most effective approach to representation learning in hyperspectral image (HSI) analysis by integrating both spectral and spatial domains. This method leverages the complementary information present in each domain; spectral data characterizes material composition, while spatial data defines contextual relationships and boundaries. Our experimental results consistently demonstrate that incorporating both spectral and spatial contrasts during training yields superior regression performance compared to methods focusing solely on spectral or spatial information. This improvement is attributed to the model’s enhanced ability to create robust feature representations that capture the complex interplay between material properties and their spatial arrangement within the HSI data.
Refining the Approach: Loss Functions and Validation Protocols
Contrastive learning model performance is directly dependent on the selection of an appropriate loss function. Contrastive Loss minimizes the distance between embeddings of similar data points while maximizing the distance between dissimilar points, requiring the definition of a margin parameter to control the separation. Mean Squared Error (MSE) Loss, conversely, calculates the average squared difference between predicted and actual values, and is often employed when the goal is to reconstruct input data or predict continuous values. The choice between these, or other loss functions, is dictated by the specific task and data characteristics; for instance, Contrastive Loss is prevalent in tasks focusing on representation learning and similarity measurement, while MSE Loss is common in regression and reconstruction problems. Effective optimization requires careful consideration of the loss function’s properties and its impact on the learned feature space.
Hyperspectral image (HSI) data benefits from processing techniques capable of exploiting both spectral and spatial dimensions. 3D Convolutional Neural Networks (3D CNNs) directly operate on the three-dimensional HSI cube – two spatial dimensions and one spectral dimension – enabling feature extraction that considers spatial context alongside spectral signatures. Alternatively, Transformer architectures, originally developed for natural language processing, are increasingly applied to HSI. These models utilize self-attention mechanisms to weigh the importance of different spectral bands and spatial locations, capturing long-range dependencies within the data and effectively modeling relationships between pixels and their spectral characteristics. Both 3D CNNs and Transformers allow for simultaneous analysis of spatial and spectral information, improving performance in tasks like land cover classification and object detection compared to methods that treat these dimensions separately.
Rigorous validation of hyperspectral image (HSI) analysis models necessitates the use of established datasets such as the Samson Dataset. This dataset, comprising a collection of annotated HSI data, allows for quantitative assessment of model performance across a standardized benchmark. Evaluation metrics, including R^2 scores and Mean Absolute Errors, are calculated on the Samson Dataset to determine the model’s ability to generalize to unseen data. Consistent performance across multiple folds of cross-validation, and comparison against existing state-of-the-art methods using the Samson Dataset, provides a statistically significant measure of model reliability and ensures the findings are reproducible and applicable to real-world scenarios.
To improve model robustness and performance in challenging real-world hyperspectral image (HSI) analysis, several data augmentation and pre-processing techniques are employed. Elastic Distortion introduces localized deformations to training samples, increasing invariance to spatial variations. Nearest Neighbor Mixing creates new training examples by combining spectral features from similar pixels, effectively expanding the dataset and improving generalization. Atmospheric Compensation corrects for atmospheric effects that distort spectral signatures, leading to more accurate results. These enhancements consistently yield improved R^2 scores and reduced Mean Absolute Errors across validation datasets, demonstrating their effectiveness in addressing complexities present in real-world HSI data.
Expanding Horizons: Impact and Future Directions
The newly proposed analytical framework represents a substantial advancement in hyperspectral data processing, yielding markedly improved accuracy and reliability compared to existing methods. This enhanced performance directly translates to more effective outcomes across diverse scientific disciplines; in environmental monitoring, it facilitates more precise identification of vegetation stress and pollution sources. Precision agriculture benefits from improved crop health assessment and targeted resource allocation, while material science gains the ability to characterize subtle compositional variations with unprecedented detail. By minimizing errors and maximizing information extraction, this framework empowers researchers and practitioners to address complex challenges and unlock deeper insights from hyperspectral data, ultimately driving innovation in these critical fields.
Continued advancement in hyperspectral data analysis necessitates a shift toward augmentation strategies that dynamically adapt to the unique characteristics of each dataset. Current data augmentation techniques often employ generalized transformations, potentially introducing unrealistic variations or failing to address the specific noise profiles inherent in hyperspectral imagery. Future research should therefore prioritize the development of algorithms capable of intelligently tailoring augmentation parameters-such as spectral band selection, spatial deformation, and noise injection-based on an assessment of the data itself. Simultaneously, exploration of novel contrastive learning architectures-designed to maximize the separability of relevant features while minimizing the impact of irrelevant variations-holds significant promise. These architectures, when combined with adaptive augmentation, could dramatically improve the robustness and generalization ability of models trained on hyperspectral data, paving the way for more accurate and reliable insights across diverse applications.
The true potential of this framework lies in its synergy with established machine learning methodologies, particularly Hyperspectral Unmixing. This technique decomposes mixed pixel signatures into constituent endmember spectra, revealing the proportional abundance of each material within the observed area. By integrating the refined data provided by this approach with unmixing algorithms, researchers can achieve significantly more accurate and detailed material identification and quantification. This combination not only enhances the precision of current analyses but also opens avenues for detecting subtle spectral variations previously obscured by noise or complexity, ultimately providing a more nuanced understanding of the observed scene and unlocking deeper insights across diverse applications, from detailed geological surveys to sophisticated crop health monitoring.
The framework’s resilience in challenging environments stems from its sophisticated approach to data simulation and augmentation. By incorporating Elastic Deformation – a technique that realistically distorts spatial data – and the Scattering Hapke’s Model, which mimics how light interacts with surfaces, the system effectively prepares for the complexities of real-world hyperspectral imaging. This preparation isn’t merely theoretical; the framework is rigorously tested by simulating conditions with a Signal-to-Noise Ratio of 20 dB, a level commonly encountered in practical applications. This deliberate exposure to noise and distortion ensures that the analysis remains stable and accurate, even when dealing with imperfect or ambiguous data, ultimately broadening the scope of environments and applications where reliable hyperspectral analysis is possible.
![The proposed framework integrates <span class="katex-eq" data-katex-display="false">\mathcal{F}[x]</span> and <span class="katex-eq" data-katex-display="false">\mathcal{G}[x]</span> to achieve a cohesive system architecture.](https://arxiv.org/html/2602.10745v1/images/diagram-spatial.png)
The pursuit of effective hyperspectral data analysis, as detailed in this framework, demands a considered approach to feature extraction and integration. This research elegantly addresses the challenge of fusing spectral and spatial information, recognizing that simply increasing model complexity isn’t sufficient. It’s about harmonious design-achieving optimal performance through tailored data augmentation and carefully chosen 3D convolutional architectures. As Fei-Fei Li once stated, “AI is not about replacing humans; it’s about augmenting human capabilities.” This framework embodies that sentiment; it doesn’t aim to merely process data, but to refine understanding by drawing out the subtle relationships within the spectral-spatial domain, ultimately enhancing the reliability of regression tasks.
Beyond the Horizon
The presented framework, while demonstrating a marked improvement in spectral-spatial feature fusion for regression on hyperspectral data, merely sketches the edges of a much larger, and stubbornly complex, problem. The reliance on carefully constructed data augmentation techniques, though effective, hints at a deeper need for representations intrinsically robust to variations in illumination, sensor noise, and the inevitable imperfections of real-world data acquisition. A truly elegant solution will not require such crutches, but will instead distill invariances directly from the signal itself.
Future work should cautiously consider the computational cost of these increasingly complex 3D convolutional and transformer architectures. There is a certain irony in pursuing higher accuracy at the expense of deployability; a model that cannot operate efficiently on resource-constrained platforms is, in a practical sense, incomplete. The pursuit of parsimony – of finding the simplest model that adequately explains the data – remains a virtue, even in an age of abundant computing power.
Ultimately, the true test of this, and similar, approaches will lie not in benchmark datasets, but in their ability to generalize to novel scenarios and unexpected data distributions. Consistency, in this context, is a form of empathy for future users, a tacit acknowledgement that the landscape of hyperspectral analysis is ever-shifting. The most enduring contributions will be those that prioritize adaptability and resilience over fleeting gains in performance.
Original article: https://arxiv.org/pdf/2602.10745.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Securing the Agent Ecosystem: Detecting Malicious Workflow Patterns
- DOT PREDICTION. DOT cryptocurrency
- Silver Rate Forecast
- 4 Reasons to Buy Interactive Brokers Stock Like There’s No Tomorrow
- EUR UAH PREDICTION
- NEAR PREDICTION. NEAR cryptocurrency
- Did Alan Cumming Reveal Comic-Accurate Costume for AVENGERS: DOOMSDAY?
- Top 15 Insanely Popular Android Games
- USD COP PREDICTION
2026-02-12 22:06