Author: Denis Avetisyan
Researchers have unveiled a challenging benchmark to assess how well artificial intelligence can detect increasingly sophisticated audio-video forgeries.
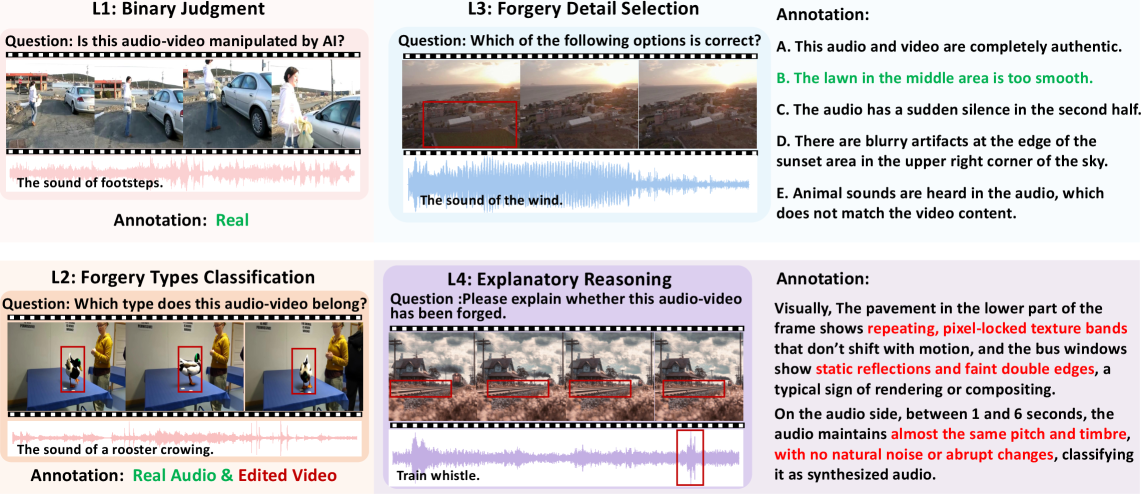
AVFakeBench, a comprehensive dataset, reveals limitations in current large multimodal models regarding fine-grained perception, cross-modal alignment, and explainability in forgery detection.
While increasingly sophisticated audio-video (AV) forgeries extend beyond simple deepfakes, current detection benchmarks remain limited in scope and granularity. To address this gap, we introduce AVFakeBench: A Comprehensive Audio-Video Forgery Detection Benchmark for AV-LMMs, a large-scale dataset encompassing diverse forgery types and annotation levels for robust AV manipulation analysis. Our evaluation of eleven Audio-Video Large Language Models reveals their potential as forgery detectors, yet highlights notable weaknesses in fine-grained perception and explainable reasoning. Can these emerging models be further refined to reliably identify and contextualize increasingly subtle AV manipulations in real-world scenarios?
The Rising Tide of Synthetic Media: A Challenge to Authenticity
The rapid advancement of generative models, particularly those leveraging deep learning, is fueling a surge in highly realistic audio-video forgeries that pose an unprecedented challenge to conventional detection techniques. These models, capable of synthesizing convincing visual and auditory content, are no longer limited to simple manipulations; they can create entirely fabricated events and convincingly impersonate individuals. Traditional forgery detection methods, often reliant on identifying inconsistencies in compression artifacts or physical impossibilities, are increasingly ineffective against such sophisticated creations. The sheer volume of generated content, combined with the nuanced realism achievable by these models, overwhelms existing automated systems and demands the development of novel approaches focused on subtle biometric cues, semantic inconsistencies, and the inherent statistical properties of genuine media, creating a continuous arms race between forgery creation and detection.
The potential for convincingly fabricated audio and video presents a significant threat to societal stability, as widespread dissemination of forgeries can rapidly erode public trust in media sources. Beyond simple misinformation, these manipulations can be leveraged to damage reputations, incite unrest, or even influence political outcomes. The ease with which generative models now create realistic content means that verifying the authenticity of digital media is becoming increasingly difficult, demanding a proactive approach to detection and verification. This isn’t merely a technical challenge; it’s a crucial step in safeguarding democratic processes and maintaining a shared understanding of reality, as the line between genuine and fabricated content blurs with each technological advancement. Without effective countermeasures, the proliferation of convincing forgeries risks creating a climate of pervasive distrust, where objective truth becomes increasingly elusive.
Current methods for detecting audio-visual forgeries face significant hurdles as manipulation techniques become increasingly subtle and generative models gain in power. Traditional approaches, often reliant on identifying obvious inconsistencies or artifacts, are easily bypassed by forgeries that incorporate nuanced alterations – slight shifts in facial expressions, barely perceptible audio distortions, or realistic yet fabricated backgrounds. The rapid evolution of generative adversarial networks (GANs) and other AI-driven tools allows the creation of increasingly convincing deepfakes, pushing the boundaries of what is detectable with existing forensic analysis. These advanced techniques can synthesize entirely new content, seamlessly blend manipulated elements, and even mimic the unique characteristics of individuals, rendering conventional detection methods largely ineffective and demanding the development of more robust, AI-powered solutions capable of discerning authenticity at a granular level.
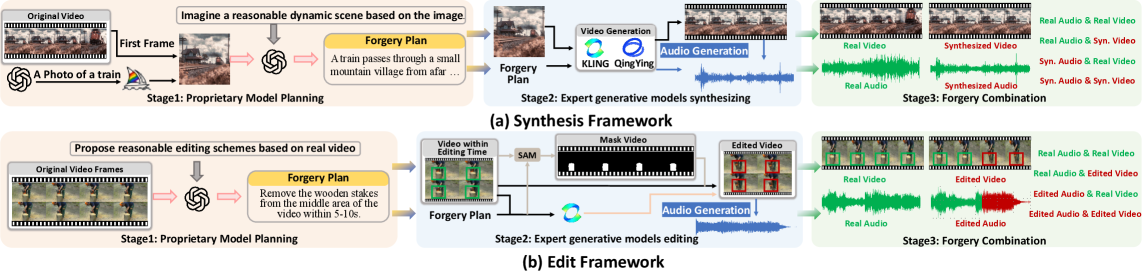
AVFakeBench: Establishing a Rigorous Standard for Forgery Evaluation
AVFakeBench is a newly developed benchmark intended to provide a standardized and comprehensive evaluation of audio-video forgery detection models. Existing benchmarks often lack the diversity and realism necessary to thoroughly test current state-of-the-art techniques; AVFakeBench addresses this limitation through the implementation of a controlled, yet highly variable, forgery generation process. The benchmark is designed to move beyond simple “real or fake” classification and assess a model’s ability to handle complex manipulations in both the visual and auditory domains, providing a more robust and reliable measure of performance than previously available tools.
The AVFakeBench benchmark employs a Hybrid Forgery Framework consisting of both physically-based rendering and Generative Adversarial Networks (GANs) to create a diverse range of audio-visual forgeries. This framework allows for the synthesis of manipulations including face swapping, lip syncing, expression editing, and splicing, as well as the generation of realistic background noise and environmental effects. By combining these techniques, AVFakeBench generates high-fidelity forgeries that are designed to challenge existing detection methods, moving beyond simple, easily-detectable manipulations and necessitating robust evaluation criteria. The framework’s parameterization also allows for controlled variation in forgery realism and complexity, enabling systematic analysis of model performance across different manipulation types and levels of subtlety.
AVFakeBench’s evaluation methodology comprises four distinct tasks designed to comprehensively assess audio-video forgery detection capabilities. Binary Authenticity Judgment requires models to classify content as either authentic or forged. Multiple-Choice Forgery Classification challenges models to identify the specific type of forgery present, such as splicing or cloning. The Forgery Detail Selection task evaluates a model’s ability to pinpoint the exact location and extent of manipulated regions within the content. Finally, Explanatory Reasoning demands that models provide justifications for their decisions, requiring a deeper understanding of the forgery’s characteristics and the reasoning behind its detection.
AVFakeBench’s evaluation extends beyond simple forgery detection to encompass a detailed understanding of the manipulations present in audio-visual content. The benchmark’s four tasks-Binary Authenticity Judgment, Multiple-Choice Forgery Classification, Forgery Detail Selection, and Explanatory Reasoning-collectively assess a model’s capacity to identify whether a forgery exists, what type of forgery was applied, where specific manipulations occurred within the content, and how those manipulations were implemented. This granular approach allows for a comprehensive performance profile, moving beyond a single accuracy score to reveal strengths and weaknesses in a model’s ability to analyze and interpret complex audio-visual forgeries.

Harnessing Multi-Modal Intelligence: AV-LMMs for Robust Detection
Audio-Visual Large Multimodal Models (AV-LMMs) represent a novel approach to forgery detection by integrating data from both audio and video streams during processing. Unlike unimodal systems that analyze only one data type, AV-LMMs leverage the complementary information present in visual and auditory signals. This joint processing allows the models to learn correlations and dependencies between the modalities, potentially revealing manipulations that might be undetectable when analyzing audio or video in isolation. The architecture typically involves encoders to extract features from each modality, followed by a fusion mechanism to combine these representations for subsequent analysis and classification. This capability is particularly relevant as sophisticated forgeries often attempt to maintain surface-level consistency in both visual and auditory components, requiring a holistic analysis for effective detection.
AV-LMMs achieve forgery detection by establishing correlations between visual and auditory data streams. These models are trained to recognize expected relationships – for example, the synchronization between lip movements and corresponding speech – and identify deviations from these norms. The capacity to learn these inter-modal relationships allows AV-LMMs to detect manipulations that might not be apparent when analyzing either modality in isolation. Subtle inconsistencies, such as asynchronous lip movements or mismatches between vocal tone and facial expressions, are flagged as potential indicators of tampering, leveraging the model’s understanding of cross-modal coherence. This approach differs from unimodal detection methods, which are susceptible to forgeries that maintain internal consistency within a single modality.
Audio-Visual Large Multimodal Models (AV-LMMs) exhibit notable capability in analyzing lip synchronization, or LipSync, as a key indicator of video authenticity. These models process both visual lip movements and corresponding audio to determine consistency; discrepancies between the visual articulation and the spoken content strongly suggest manipulation. This capability stems from the AV-LMM’s ability to learn the complex relationship between visual and auditory features, enabling it to detect even subtle asynchronies that might be imperceptible to human observers. Consequently, LipSync analysis represents a core strength of AV-LMMs in forgery detection, although performance varies depending on the complexity of the manipulation and the dataset used for training.
Current AV-LMM performance demonstrates a notable disparity between task complexity. Gemini-2.5-Pro achieves 54.3% accuracy in binary authenticity judgment – determining if a sample is real or forged. However, when challenged with multiple-choice forgery classification, requiring discernment between different types of forgeries, AV-LMM accuracy declines sharply to 19.2%. This substantial drop indicates that while these models can detect the presence of manipulation, they struggle to identify the specific method used, highlighting a limitation in their ability to generalize to more nuanced forgery detection scenarios.
The Dual-Edged Sword: Generative Models and the Future of Authenticity
Despite the growing sophistication of audiovisual large multimodal models (AV-LMMs) in detecting synthetic content, generative models like Sora and KLING pose a formidable counter-challenge. These models are rapidly advancing in their ability to create remarkably realistic audio and video, effectively narrowing the gap between genuine and fabricated media. The increasing fidelity of synthesized content, coupled with the speed of generative processes, presents a moving target for detection systems. As generative models become more adept at mimicking the nuances of reality, AV-LMMs face an escalating demand for enhanced perceptual capabilities and more robust reasoning to maintain effective forgery detection. This creates a continuous arms race where advancements in generation necessitate parallel improvements in detection technology to avoid widespread deception.
The rapid advancement of generative models is now capable of producing synthesized audio and video content with unprecedented realism, fundamentally challenging the perception of digital authenticity. No longer limited to simple manipulations, these models can fabricate entirely new scenes and performances, complete with nuanced expressions and synchronized sound, making it increasingly difficult to distinguish between genuine recordings and cleverly constructed forgeries. This capability extends beyond visual media, with synthesized speech achieving comparable levels of believability, further complicating the landscape of digital verification. The resulting ambiguity poses a significant threat, as convincingly fabricated content can be used to spread misinformation, damage reputations, or even incite conflict, eroding trust in all forms of digital media.
The creation of convincing forgeries is increasingly facilitated by tools specializing in synchronized audio-video generation, such as FoleyCrafter. These applications move beyond simple video manipulation by allowing for the precise crafting of accompanying soundscapes, meticulously aligning auditory elements with visual actions. This synchronization is crucial; subtle discrepancies between sound and vision often betray a fabrication, but these tools minimize such inconsistencies, producing remarkably realistic outputs. The ability to generate not just what is seen, but also what is heard, and to seamlessly integrate the two, dramatically lowers the barrier to creating compelling, yet entirely false, audio-visual content, posing a significant challenge to detection efforts and reinforcing the dual-use nature of these powerful technologies.
Despite recent progress in multimodal AI, discerning subtle manipulations within audio and video remains a significant challenge for even the most advanced models. Evaluation of GPT-4o demonstrates a clear limitation in fine-grained forgery detection; the model achieved a Macro-F1 score of only 27.5% when tasked with identifying specific forged details. Furthermore, its reasoning capabilities, assessed through explanation generation, yielded a score of just 29.0 out of 100, indicating a struggle to articulate how a forgery was identified. This suggests that current systems, while capable of flagging manipulated content, often lack the perceptual acuity and analytical depth necessary to pinpoint the specific alterations and provide a justifiable rationale, hindering trust and effective counter-measures.
The rapid advancement of generative artificial intelligence presents a significant paradox: technologies designed to unlock unprecedented creative potential also introduce powerful new tools for deception. These models, capable of producing remarkably realistic audio and video content, are not inherently malicious, yet their very strengths can be readily exploited to create convincing forgeries and spread disinformation. This duality-the capacity for both beneficial creation and harmful manipulation-poses a critical challenge for researchers and policymakers alike. Addressing this requires not only developing robust detection methods, but also considering the ethical implications and potential societal harms associated with increasingly sophisticated generative capabilities, demanding a proactive approach to mitigate risks without stifling innovation.

The pursuit of robust audio-visual forgery detection, as detailed in AVFakeBench, demands more than simply achieving high accuracy; it necessitates a harmonious interplay between perception and reasoning. A model’s ability to discern subtle manipulations – the fine-grained perception the benchmark tests – echoes the importance of elegant design. As Andrew Ng once stated, “AI is the new electricity.” This sentiment resonates with the need for foundational benchmarks like AVFakeBench, providing the essential current to power further innovation in multimodal models and pushing them beyond superficial understanding toward genuine, explainable intelligence. The benchmark’s focus on audio-visual alignment isn’t merely a technical challenge; it’s a quest for coherence, mirroring the beauty found in systems where every component works in concert.
What’s Next?
The emergence of AVFakeBench highlights a curious paradox. Large multimodal models, possessing impressive scale, demonstrate a disconcerting fragility when confronted with even subtle manipulations of audio-visual data. It is not merely a question of detecting the forgery, but of understanding what has been altered, and why that alteration matters. The current models offer glimpses of competence, but lack the robust, principled reasoning one might expect from a system aiming to discern truth from fabrication.
Future work must move beyond superficial pattern matching. A focus on disentangled representations – isolating the underlying factors of variation in audio and visual signals – seems crucial. This pursuit demands a deeper integration of perceptual modeling, acknowledging that human perception is not merely a passive reception of stimuli, but an active process of inference. Interface consistency in explaining these detections is a form of respect for the user, and vital for building trust.
Ultimately, the field requires a shift in aesthetic. The goal isn’t simply to achieve high accuracy scores, but to construct systems that explain their reasoning with elegance and clarity. A system that whispers the truth, rather than shouts a probability, is a system worthy of trust. The localization of forgeries is not merely a technical challenge; it is an exercise in visual and auditory storytelling, demanding that models articulate how they arrived at a particular conclusion.
Original article: https://arxiv.org/pdf/2511.21251.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- 15 Films That Were Shot Entirely on Phones
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Black Actors Fans Say Hollywood Only Casts as Criminals
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Here are the Best Series to Binge on Paramount+ in January 2026
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2025-11-29 10:42