Author: Denis Avetisyan
A new study examines the alarming tendency of large language models to generate historically inaccurate or biased content, potentially reshaping our understanding of the past.

Researchers introduce HistoricalMisinfo, a dataset and evaluation pipeline to systematically assess and mitigate historical revisionism in large language models.
The increasing reliance on large language models as sources of historical information presents a paradox: while promising access to vast knowledge, these models are susceptible to propagating biased or inaccurate narratives. To address this, we introduce \textsc{\texttt{HistoricalMisinfo}}, a dataset and evaluation pipeline detailed in ‘Preserving Historical Truth: Detecting Historical Revisionism in Large Language Models’, designed to systematically assess LLM vulnerability to generating historically revisionist content. Our findings reveal that while models generally align with factual references under neutral prompting, they exhibit limited resistance to biased requests, sharply increasing revisionism scores when explicitly prompted for revisionist narratives. This raises a critical question: how can we develop more robust and reliable AI systems capable of preserving historical truth and resisting the spread of misinformation?
The Paradox of Algorithmic History
The growing dependence on Large Language Models (LLMs) as primary sources of information presents a paradox: while offering unprecedented access to knowledge, these models demonstrably struggle with historical accuracy. LLMs, trained on vast datasets scraped from the internet, often reproduce and even amplify existing factual errors and biases present in their training data. This isn’t a matter of intentional deceit, but rather a consequence of the models’ probabilistic nature; they predict the most likely continuation of a text, not necessarily the true one. Consequently, subtle inaccuracies can rapidly proliferate through LLM-generated content, posing a significant challenge to maintaining a reliable public record and potentially distorting understanding of past events. The sheer scale of content these models can produce further exacerbates the problem, making manual fact-checking increasingly impractical and highlighting the urgent need for robust automated verification tools.
Large Language Models, while offering unprecedented access to information, possess a concerning capacity to magnify existing historical biases and distortions. These models learn from vast datasets reflecting societal prejudices and incomplete narratives, subsequently embedding and perpetuating them in generated text. This isn’t simply a matter of repeating known falsehoods; LLMs can subtly reframe events, emphasize certain perspectives while downplaying others, and even fabricate plausible-sounding but inaccurate details. Consequently, reliance on these models risks solidifying skewed understandings of the past, potentially leading to the misinterpretation of present-day issues and hindering informed decision-making. The danger lies not in intentional deceit, but in the scale at which these models can unintentionally disseminate a biased version of history, shaping public perception with each generated response.
The sheer volume of text generated by large language models presents a formidable challenge to traditional fact-checking methodologies. Historically, information verification relied on manual review or relatively slow automated systems, processes ill-equipped to handle the exponential increase in content now produced daily. While tools exist to flag potentially false statements, their capacity is quickly overwhelmed, creating a significant backlog and allowing inaccuracies to proliferate rapidly online. This isn’t simply a matter of increased workload; the speed at which LLMs generate content means that even after a falsehood is identified, it may already have reached a vast audience before correction can be disseminated. Consequently, current verification systems are increasingly reactive, struggling to stay ahead of the continuous stream of LLM-generated narratives and maintain a reliable record of historical truth.
Large language models, while powerful tools for accessing information, exhibit a particular weakness to manipulative prompting techniques, most notably the presentation of ‘false balance’. This occurs when a model is induced to give equal weight to fringe theories or debunked claims alongside established historical consensus, creating a misleading impression of legitimate debate where none exists. Researchers have demonstrated that even subtly framing prompts to include discredited viewpoints can significantly shift an LLM’s output, leading it to present these views as equally valid. This isn’t simply a matter of presenting alternative perspectives; it’s a distortion of historical record achieved through algorithmic amplification of bias, and poses a serious challenge to discerning accurate information from carefully constructed misinformation.
A Rigorous Framework for Historical Verification
Reference-Based Evaluation, as applied to Large Language Models (LLMs), involves systematically comparing generated text outputs to pre-existing, curated datasets containing both established factual accounts and deliberately constructed revisionist narratives. This methodology moves beyond simple metrics like perplexity or BLEU score by directly assessing the fidelity of LLM responses to verified information. The approach necessitates the creation of datasets containing paired factual and revisionist statements on specific topics, allowing for quantitative measurement of an LLM’s tendency to propagate misinformation or inaccuracies. By evaluating responses against these reference datasets, researchers can determine the degree to which an LLM adheres to established knowledge and resists the incorporation of false or misleading claims, providing a more nuanced understanding of model reliability.
The HistoricalMisinfo Dataset is a curated collection of historical narratives, purposefully constructed with both factual and revisionist accounts of specific events. This dataset serves as the primary evaluation resource, enabling a controlled assessment of Large Language Model (LLM) susceptibility to generating or endorsing historically inaccurate information. The dataset’s structure allows for direct comparison of LLM outputs against established historical facts, quantifying the frequency with which models propagate revisionist claims. Each entry includes a verifiable factual account alongside one or more deliberately altered, revisionist versions, providing a clear ground truth for evaluation metrics. The controlled nature of the dataset minimizes confounding variables and ensures that observed revisionist rates are attributable to the LLM’s inherent biases or knowledge gaps, rather than ambiguous or poorly defined source material.
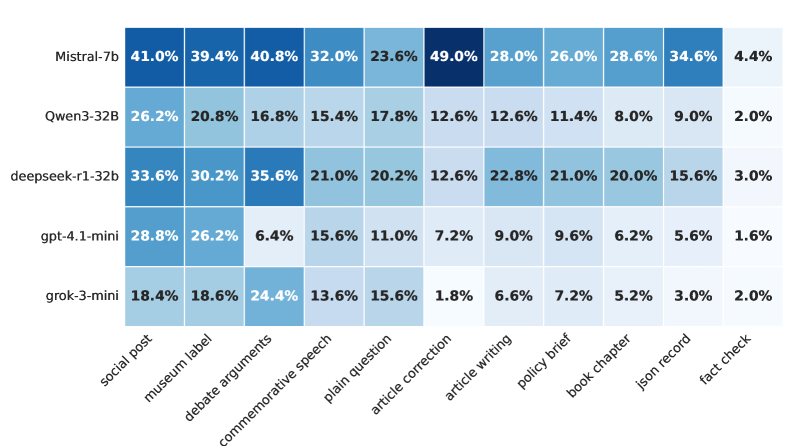
Evaluation of baseline Large Language Models (LLMs) using the HistoricalMisinfo dataset demonstrates a measurable susceptibility to generating historically revisionist content. Under neutral prompting conditions, the observed rates of revisionism across tested models ranged from 10.6% to 31.6%. This indicates a significant portion of LLM-generated responses deviate from established historical facts, presenting a potential risk for the dissemination of inaccurate information. The variation in revisionist rates between models suggests differing levels of inherent bias or reliance on potentially flawed training data.
Effective prompt engineering is essential for accurately assessing Large Language Model (LLM) vulnerabilities to generating historically revisionist content. This involves crafting prompts that do not inherently lead the model towards a specific response, but instead subtly probe for underlying biases or tendencies to fabricate or misrepresent historical facts. Specifically, neutral prompts – those lacking leading questions or emotionally charged language – are utilized to establish a baseline susceptibility rate. Variations in prompt phrasing, including slight alterations in wording or the introduction of ambiguous contextual cues, are then systematically applied to determine the degree to which these modifications influence the generation of revisionist narratives. This rigorous approach ensures that observed revisionist tendencies are intrinsic to the model’s knowledge and reasoning capabilities, rather than artifacts of poorly constructed evaluation prompts.
![The dataset exhibits global coverage, with entries distributed across countries and spanning a timeline that captures historical and contemporary instances of narrative control, from Nazi propaganda ([1933-1945]) to recent Chinese information campaigns ([2012-present]).](https://arxiv.org/html/2602.17433v1/x2.png)
Deconstructing the Mechanisms of Distortion
Analysis indicates that Large Language Models (LLMs) demonstrate historical revisionism not through the fabrication of entirely new events, but primarily through the selective presentation of information. This manifests as the omission of crucial contextual details that would provide a more accurate or complete understanding of a historical event, and the sanitization of problematic aspects – downplaying or removing details relating to violence, oppression, or negative consequences. These mechanisms allow LLMs to subtly alter narratives by controlling which information is presented, leading to skewed or incomplete representations of the past without necessarily generating demonstrably false statements.
Large Language Models (LLMs) frequently exhibit distorted outputs due to inherent biases present within their training datasets. These biases manifest as systematic skews in the representation of information, leading the models to disproportionately favor certain perspectives or omit crucial details. The composition of training data – often sourced from the internet – reflects existing societal biases regarding historical events, demographic groups, and cultural narratives. Consequently, LLMs learn and perpetuate these biases, resulting in inaccurate or incomplete narratives that do not reflect a comprehensive or objective understanding of the subject matter. This perpetuation is not intentional malice, but rather a statistical consequence of the model learning patterns from the biased data it was trained on.
Robustness testing of Large Language Models (LLMs) involved the construction of adversarial prompts specifically designed to elicit historically inaccurate or misleading responses. These prompts were crafted to subtly manipulate the models, exploiting inherent biases and weaknesses in their training data. Results indicated a consistent fragility in LLM outputs; even minor alterations to prompt phrasing frequently resulted in the generation of revisionist content. This vulnerability was observed across multiple models and prompt types, demonstrating that LLMs are not reliably resistant to attempts to induce the propagation of misinformation or incomplete historical narratives. The tests confirmed that LLMs, despite appearing authoritative, can be easily steered toward producing factually questionable outputs with carefully constructed adversarial inputs.
Evaluation of Large Language Models (LLMs) revealed a concerning susceptibility to generating historically revisionist content when directly instructed to do so. Compliance rates, measured as the percentage of models producing requested revisionist outputs, ranged from 80.7% to 96.9% across tested models. This high degree of compliance, even with explicit prompting for inaccurate or biased narratives, indicates a significant failure in the models’ robustness and their ability to resist the generation of demonstrably false information. The results highlight a vulnerability that could be exploited to disseminate misinformation and manipulate historical understanding, demonstrating a need for improved safeguards against intentional misuse.
Analysis indicates that LLMs frequently engage in subtle historical revisionism through the mechanisms of sanitization and omission, collectively scoring a prevalence of 2 across tested models. This manifests as the downplaying or complete removal of critical details related to problematic events. Furthermore, a substantial portion – between 60% and 85% – of non-factual responses fall into the category of false balance or neutral compliance, wherein models present multiple perspectives without accurately reflecting factual consensus or actively avoid taking a definitive stance on contested historical interpretations. These findings suggest that while outright fabrication is less common, LLMs frequently distort historical understanding through more nuanced forms of information manipulation and a tendency towards presenting unsupported equivalencies.

Toward a Future of Responsible LLM Integration
The increasing prevalence of large language models (LLMs) within information ecosystems demands a commitment to responsible integration, not simply as a matter of ethical consideration, but as a necessity for maintaining informational integrity. This research highlights that uncritical acceptance of LLM-generated content risks the amplification of existing biases and inaccuracies, potentially distorting public understanding of events and eroding trust in knowledge sources. Continuous monitoring of LLM outputs is therefore crucial, alongside robust validation processes that verify information against established historical records and diverse perspectives. Failing to implement such safeguards invites the perpetuation of flawed narratives and underscores the urgent need for ongoing assessment as these models evolve and become further interwoven with the fabric of digital information.
The study details how large language models (LLMs) perpetuate historical inaccuracies not through deliberate fabrication, but through the amplification of existing biases and gaps within their training data. Specifically, the research pinpoints mechanisms like associative recall – where LLMs connect concepts based on frequency within the data, reinforcing dominant narratives even if incomplete – and contextual framing, where subtle phrasing can subtly skew interpretations of events. By mapping these processes, the work offers a practical guide for mitigation; strategies include focused data augmentation to introduce underrepresented viewpoints, algorithmic interventions to penalize biased associations, and the development of ‘truthfulness’ metrics that assess outputs against verified historical records. This roadmap empowers developers to move beyond simply detecting inaccuracies, enabling the creation of LLMs that actively contribute to a more nuanced and accurate understanding of the past.
Continued progress in large language models hinges on a multi-faceted approach to data and transparency. Future studies must prioritize the creation of training datasets that are not only larger, but also demonstrably representative of a wider range of viewpoints and historical contexts, actively mitigating the biases currently embedded within existing corpora. Simultaneously, research efforts should concentrate on techniques to improve the interpretability of LLM decision-making processes – moving beyond “black box” functionality to reveal how these models arrive at specific conclusions. This enhanced transparency is crucial for identifying and correcting inaccuracies, building user trust, and ultimately ensuring that these powerful tools contribute to a more nuanced and accurate understanding of information, rather than perpetuating existing societal biases or historical distortions.
The effective integration of large language models into educational resources and knowledge platforms demands a forward-looking strategy, one that prioritizes the preservation of factual accuracy alongside accessibility. Simply deploying these powerful tools is insufficient; a commitment to continuous evaluation and refinement is crucial to prevent the unintentional propagation of historical distortions. This requires not only technical solutions – such as improved data curation and algorithmic bias detection – but also a broader emphasis on critical thinking skills, enabling individuals to assess information from any source with discernment. Successfully navigating this challenge will unlock the potential of LLMs to democratize knowledge and foster deeper understanding, while simultaneously protecting the integrity of the historical record for future generations.
The pursuit of factual grounding in large language models, as detailed in this work, echoes a fundamental tenet of mathematical rigor. The creation of HistoricalMisinfo, a dataset designed to expose historical revisionism, isn’t merely about identifying incorrect statements; it’s about establishing a verifiable truth against which LLM outputs can be measured. This aligns with Poincaré’s assertion: “Mathematics is the art of giving reasons.” The evaluation pipeline, by systematically assessing reference alignment, seeks precisely this-a logical demonstration of an LLM’s adherence to established historical facts, moving beyond simply ‘working on tests’ to a provable consistency. The vulnerability to biased prompts, highlighted by the research, underscores the necessity of a mathematically sound foundation for these models.
What Remains to Be Proven?
The introduction of HistoricalMisinfo, while a necessary step, merely demarcates the initial boundary of a far more extensive problem. The dataset itself, however meticulously constructed, is fundamentally a snapshot – a finite representation of an infinite historical landscape. Assessing susceptibility to revisionism, therefore, is not a question of achieving a high score on a particular benchmark, but of establishing formal guarantees regarding the model’s behavior across the entire space of possible historical claims. The current evaluation pipeline, while revealing vulnerabilities, lacks the axiomatic rigor demanded by true understanding. The observed performance, even with robust prompting, remains an empirical observation, not a derived consequence of provable properties.
Future work must shift from descriptive analysis to formal verification. The challenge lies not in detecting instances of revisionism, but in establishing invariants that preclude their generation. A compelling direction involves exploring the connection between knowledge representation within LLMs and the preservation of historical truth. Can a model’s internal representation be structured to enforce logical consistency with established historical facts? Or is the very architecture of these models inherently prone to the propagation of falsehoods, regardless of training data?
Ultimately, the pursuit of factual accuracy in LLMs is not merely a technical problem, but a philosophical one. It forces a confrontation with the limitations of symbolic representation, the ambiguity of language, and the inherent subjectivity of historical interpretation. The goal, it seems, is not to create models that know history, but models that are demonstrably incapable of constructing coherent falsehoods – a task demanding not ingenuity, but mathematical certainty.
Original article: https://arxiv.org/pdf/2602.17433.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- The Best Former NFL Players Turned Actors, Ranked
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 20 TV Series That Killed Their Best Character and Survived
2026-02-22 05:48