Author: Denis Avetisyan
Researchers have developed a new AI agent, TKG-Thinker, capable of autonomously navigating and reasoning over evolving knowledge graphs to answer complex questions involving temporal data.
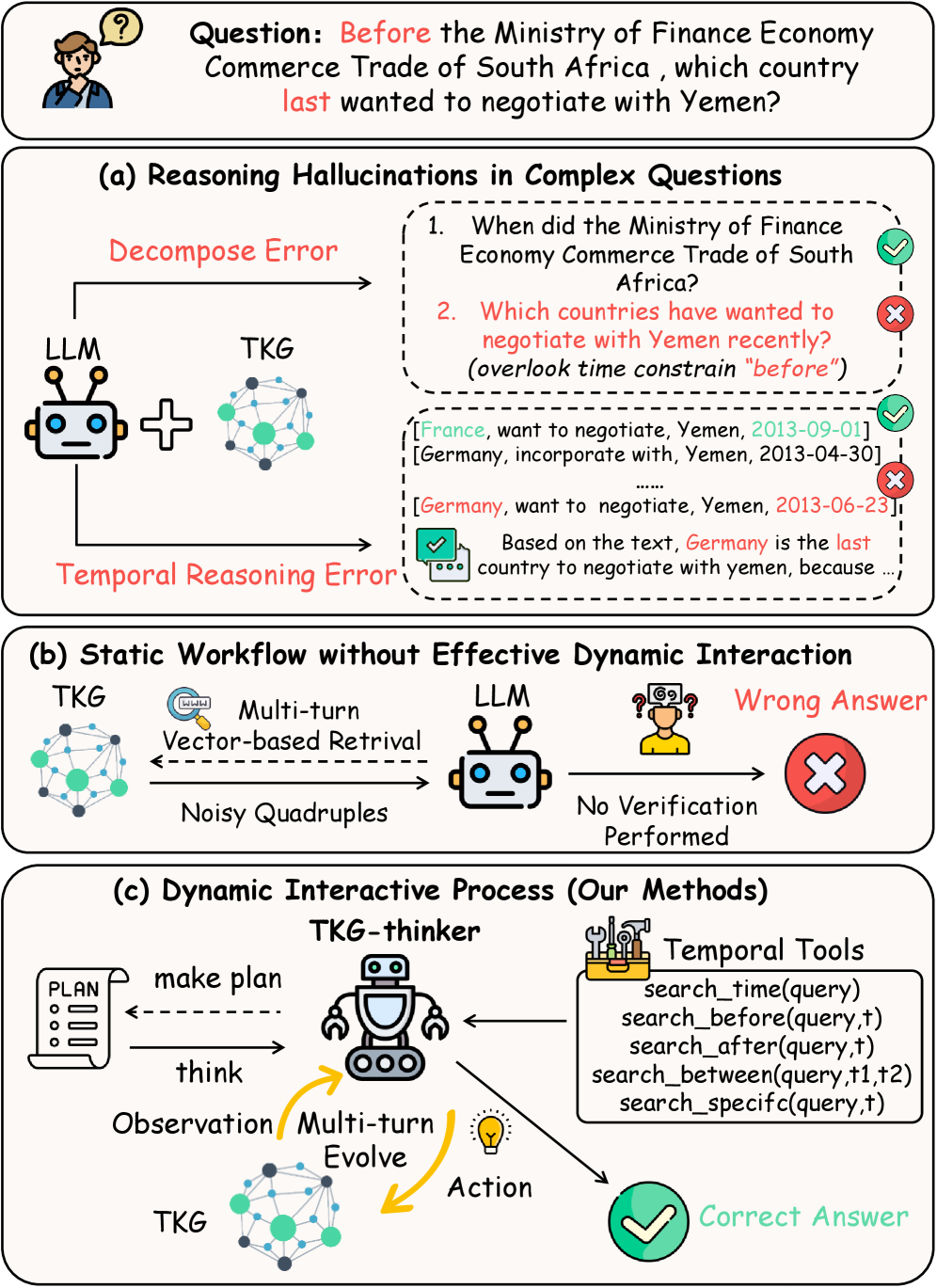
This work introduces TKG-Thinker, a reinforcement learning framework leveraging agentic reasoning to improve performance on temporal knowledge graph question answering.
Despite the promise of large language models in temporal knowledge graph question answering (TKGQA), current prompting strategies struggle with reasoning under complex temporal constraints and lack the adaptability needed for robust generalization. To address these limitations, we introduce ‘TKG-Thinker: Towards Dynamic Reasoning over Temporal Knowledge Graphs via Agentic Reinforcement Learning’, a novel agent that leverages reinforcement learning to enable autonomous, dynamic reasoning over temporal knowledge graphs. Through a dual-training strategy incorporating supervised fine-tuning and reinforcement learning with multi-dimensional rewards, TKG-Thinker achieves state-of-the-art performance and improved generalization across complex TKGQA settings. Can this agentic approach unlock even more sophisticated reasoning capabilities within the evolving landscape of temporal knowledge representation and querying?
The Illusion of Temporal Mastery
Reasoning about the world often demands understanding not just what is true, but when it was – or will be – true. Traditional knowledge representation and reasoning systems, however, frequently falter when confronted with this temporal dimension. These systems typically assume a static world, struggling to accommodate facts that change over time or relationships that evolve. Capturing the nuances of events, durations, and the ordering of occurrences introduces a level of complexity that quickly overwhelms conventional logical frameworks. Consequently, attempts to model dynamic scenarios – like tracking the spread of information, predicting system failures, or even simply recalling past events – become computationally expensive and prone to inaccuracies. The inherent difficulty lies in the fact that temporal reasoning requires managing not just propositions, but also the time intervals over which those propositions hold, demanding a fundamentally different approach to knowledge representation and inference.
Effective reasoning about the world demands more than static knowledge; it requires a robust ability to model and interpret dynamic relationships. Questions concerning change, duration, or sequence necessitate systems capable of capturing how entities and their properties evolve over time. This isn’t simply about knowing that something was true, but understanding how it transitioned from one state to another, and predicting future states based on observed patterns. Consequently, successful temporal reasoning systems must actively process information about the relationships between events, recognizing precedence, simultaneity, and causality-elements crucial for constructing a coherent understanding of time-evolving scenarios and delivering accurate, context-aware responses.
Current reasoning systems frequently stumble when confronted with information that changes over time, largely due to an inability to seamlessly incorporate temporal context. These systems often treat knowledge as static, failing to recognize that the validity of a fact can shift depending on when it is considered. This limitation hinders accurate responses to questions demanding an understanding of evolving situations; for example, determining the status of an event requires not just knowing what happened, but when it happened relative to other events. Consequently, even logically sound reasoning can yield incorrect conclusions if the temporal dimensions of the data are not adequately processed, revealing a critical gap in the ability of these systems to mimic human-like understanding of dynamic information.
TKG-Thinker: A Framework Built on Sand (and LLMs)
TKG-Thinker employs a think-action-observe loop to facilitate iterative reasoning. This process begins with a ‘think’ step, where the model analyzes the current state and formulates a potential reasoning path. The ‘action’ step involves interacting with the Temporal Knowledge Graph to retrieve relevant information based on that path. Subsequently, the ‘observe’ step evaluates the results of the action, assessing the validity and completeness of the retrieved information. This observation then feeds back into the ‘think’ step, allowing TKG-Thinker to refine its reasoning path and repeat the loop until a satisfactory outcome is achieved. This iterative process enables the model to dynamically adjust its approach and improve the accuracy and robustness of its conclusions.
TKG-Thinker’s agentic framework facilitates dynamic interaction with the Temporal Knowledge Graph (TKG) through iterative querying and refinement. This process involves the agent formulating queries based on the current state of its reasoning, retrieving relevant information from the TKG, and then using that information to adjust subsequent queries. The system doesn’t rely on pre-defined paths, instead exploring the TKG’s interconnected data to identify information pertinent to the task at hand. This allows TKG-Thinker to adapt to complex or evolving information needs, and effectively navigate the temporal relationships encoded within the graph to uncover relevant historical and contextual data.
TKG-Thinker utilizes Large Language Models (LLMs) such as Llama3-8B-Instruct and Qwen2.5-7B-Instruct to provide a foundation of pre-trained language understanding capabilities. These LLMs have been trained on extensive text datasets, enabling them to perform tasks like natural language parsing, semantic reasoning, and knowledge retrieval without requiring task-specific training from scratch. Integrating these pre-trained models into TKG-Thinker reduces the need for substantial data annotation and training time, while simultaneously improving performance on complex reasoning tasks by leveraging the existing linguistic knowledge embedded within the LLM parameters. The 8B and 7B designations refer to the model size, specifically the number of parameters, which generally correlates with model capacity and performance.
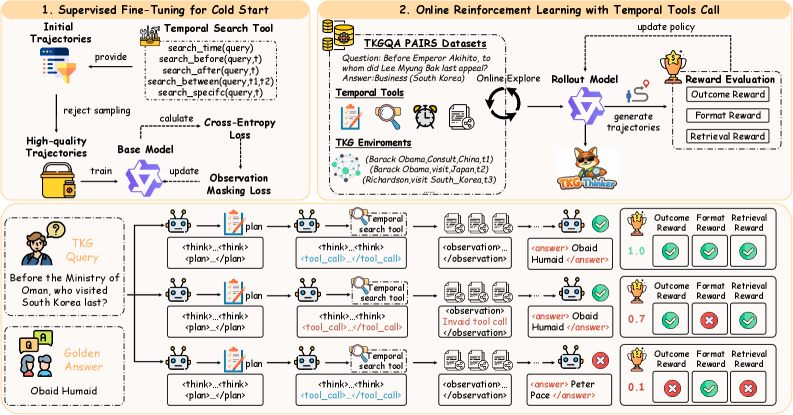
Supervised Fine-Tuning (SFT) is a critical component in establishing the initial behavioral patterns of TKG-Thinker. This process involves training the base Large Language Model (LLM), such as Llama3-8B-Instruct or Qwen2.5-7B-Instruct, on a curated dataset of input-output examples specifically designed to mimic desired reasoning and interaction patterns within the Temporal Knowledge Graph. By exposing the LLM to these labeled examples, SFT adjusts the model’s internal parameters, biasing it towards generating responses consistent with the training data. This results in a model that requires less prompting and exhibits a higher probability of producing relevant and logically structured outputs from the outset, significantly improving its performance before the agentic think-action-observe loop begins.
![TKG-Thinker, trained with either SFT+GRPO [♣] or SFT+PPO [♠], consistently achieves state-of-the-art Hits@1 scores on the MULTITQ and CronQuestions datasets, outperforming existing baselines as indicated by bold and underlined results.](https://arxiv.org/html/2602.05818v1/x14.png)
Reinforcement Learning: Polishing a Turd with Algorithms
TKG-Thinker’s reasoning capabilities are developed through Reinforcement Learning (RL), a process wherein the agent learns to maximize cumulative rewards by interacting with the Tool-augmented Knowledge Graph (TKG). This training paradigm moves beyond static datasets by allowing the agent to actively explore the TKG and receive feedback on its reasoning steps. Specifically, TKG-Thinker receives rewards based on the quality of its responses and the efficiency of its interactions with the TKG, enabling it to refine its policy and improve its reasoning performance over time. The iterative process of action, observation, and reward allows the agent to adapt and optimize its behavior for effective dynamic reasoning within the TKG environment.
To refine the agent’s reasoning policy, both Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) algorithms are utilized. PPO is a policy gradient method that iteratively improves the agent’s actions by taking small, constrained steps to avoid drastic policy changes and ensure stable learning. GRPO extends this approach by incorporating a group constraint, encouraging the agent to maintain a diverse set of reasoning strategies. This is achieved by penalizing updates that significantly deviate from a reference policy maintained across a group of similar agents, promoting exploration and preventing premature convergence on suboptimal solutions. Both algorithms operate by estimating the advantage of each action and updating the policy parameters to maximize expected rewards, with GRPO adding a regularization term to maintain policy diversity.
The training process utilizes a multi-objective reward function composed of three distinct components. The outcome reward assesses the correctness of the final answer, while the format reward evaluates adherence to the desired output structure, specifically ensuring valid JSON formatting. Critically, a retrieval reward incentivizes the agent to select relevant documents from the knowledge graph; this reward is calculated based on the reciprocal rank of the first relevant document retrieved using the e5-base-v2 embedding model, effectively promoting efficient and accurate information retrieval as part of the reasoning process. These three rewards are combined to guide the agent towards producing correct, well-formatted answers grounded in supporting evidence.
Retrieval-Augmented Generation (RAG) improves the reasoning capabilities of the model by integrating information retrieved from an external knowledge source. Specifically, the e5-base-v2 model, an embedding-based retriever, is utilized to identify relevant documents from the TKG. These retrieved documents are then incorporated as context when generating responses, effectively grounding the output in factual information and reducing reliance on the model’s parametric knowledge. This process allows the model to access and utilize a broader range of information than is contained within its original training data, leading to more accurate and informative responses.
Performance and Validation: A Temporary Stay of Execution
TKG-Thinker establishes a new benchmark in temporal knowledge graph question answering (TKGQA), consistently exceeding the performance of existing frameworks. Through a novel agentic approach coupled with reinforcement learning, the system navigates complex temporal relationships within knowledge graphs with unprecedented accuracy. This superior performance isn’t merely incremental; it signifies a substantial leap forward in the field’s ability to reason about time and events. The framework’s efficacy is particularly evident in its capacity to accurately interpret nuanced queries and retrieve precise answers, paving the way for more sophisticated applications in areas like historical analysis, event prediction, and automated reasoning systems.
The framework’s capacity for nuanced temporal reasoning is powerfully demonstrated through evaluations on the challenging MULTITQ and CronQuestions datasets. These benchmarks require not simply identifying facts, but understanding the order of events, durations, and relationships between them – a significant hurdle for many knowledge-based AI systems. Performance on both datasets confirms the framework can effectively dissect complex questions involving temporal constraints, pinpoint relevant information within large knowledge graphs, and synthesize accurate answers. This ability stems from the system’s architecture, designed to navigate temporal ambiguity and infer implicit relationships, ultimately enabling it to respond to questions demanding a deep comprehension of time-based reasoning.
Evaluations utilizing the Hits@1 metric demonstrate TKG-Thinker’s substantial accuracy in answering complex temporal questions. The framework achieved an 82.1% success rate on the challenging MULTITQ dataset and 78.5% on CronQuestions, signifying a clear advancement over previously established state-of-the-art methods – a performance difference detailed in Table 1. This metric, which assesses the rank of the correct answer within a list of possible responses, highlights TKG-Thinker’s ability to not only generate plausible answers, but to prioritize the most accurate one, establishing a new benchmark for temporal reasoning in knowledge graphs.
The demonstrated performance of TKG-Thinker on temporal knowledge graph question answering benchmarks suggests a promising avenue for artificial intelligence research. The framework’s success isn’t merely about achieving high scores; it validates the core principle that agentic systems, capable of iterative reasoning and self-correction through reinforcement learning, are particularly well-suited to tackle the complexities of temporal reasoning. Traditional methods often struggle with questions demanding an understanding of event sequences and durations, but TKG-Thinker’s architecture effectively navigates these challenges. This indicates that future AI systems designed with similar agentic and reinforcement learning principles could substantially improve performance across a range of tasks requiring an understanding of time, causality, and complex relationships – potentially unlocking new capabilities in areas like automated planning, historical analysis, and predictive modeling.
Future Directions: Delaying the Inevitable
A core challenge for knowledge-based AI lies in the inherently dynamic nature of real-world information. Future iterations of TKG-Thinker will prioritize enhanced adaptability to evolving knowledge graphs, moving beyond static datasets. This involves developing mechanisms for continuous learning and knowledge refinement, allowing the system to incorporate new facts, resolve inconsistencies, and update existing relationships without catastrophic forgetting. Researchers aim to implement strategies that enable TKG-Thinker to not merely process knowledge graphs, but to actively learn from them, identifying patterns of change and proactively adjusting its reasoning processes to maintain accuracy and relevance in a perpetually updating information landscape. Such advancements are crucial for deploying AI systems capable of robust and reliable performance in complex, real-world scenarios.
Optimizing the reasoning capabilities of knowledge graph-based systems like TKG-Thinker necessitates a move beyond standard reinforcement learning approaches. Current methods often rely on simplistic reward functions that may not fully capture the nuances of complex reasoning tasks; therefore, future work will explore more sophisticated reward structures that incentivize not just correct answers, but also the quality of the reasoning process itself – factors like efficiency, clarity, and the ability to handle uncertainty. Researchers are also investigating advanced reinforcement learning algorithms, including those that leverage hierarchical reinforcement learning and meta-learning, to enable the system to adapt more quickly to new tasks and generalize its reasoning skills across different knowledge domains. These developments aim to move beyond simply achieving a correct solution to fostering a robust and adaptable reasoning engine capable of tackling increasingly complex challenges.
The potential of TKG-Thinker extends significantly when considering the integration of information beyond its initial knowledge graph. Current reasoning systems often operate in isolation, limiting their ability to address real-world complexities which demand access to diverse and constantly updating data. Future work will explore methods to seamlessly incorporate external knowledge sources – such as common-sense databases, scientific literature, and real-time data streams – alongside multimodal inputs like images and video. This fusion promises to not only broaden the scope of answerable questions but also to enhance the robustness and accuracy of reasoning, allowing the system to ground its inferences in a richer, more comprehensive understanding of the world and ultimately mimicking human-level cognitive flexibility.
The development of TKG-Thinker signifies a crucial step towards artificial intelligence capable of navigating and understanding the ever-changing complexities of the real world. Current AI systems often struggle with scenarios requiring adaptation to new information or evolving circumstances; however, this research demonstrates the potential for AI to not simply process data, but to reason about dynamic environments. By enabling machines to build and refine knowledge graphs in real-time, and to adjust reasoning pathways accordingly, this work suggests a future where AI can move beyond static problem-solving and engage with the world in a more flexible, insightful, and ultimately, intelligent manner. The implications extend to numerous fields, from robotics and autonomous systems to scientific discovery and personalized decision-making, promising a new era of AI that is truly responsive to the world it inhabits.
The pursuit of elegant solutions in temporal knowledge graphs feels…optimistic. TKG-Thinker, with its agentic reinforcement learning, attempts to navigate the inherent messiness of time and evolving data. It’s a valiant effort, yet one can’t help but suspect that each layer of autonomous reasoning simply adds another form of technical debt. As G.H. Hardy observed, “Mathematics may be compared to a box of drawers; one labelled ‘completed proofs’, another labelled ‘problems’, and the remainder labelled ‘unfinished business’.” This paper neatly adds to that last drawer. The agent might excel at dynamic reasoning now, but production environments will inevitably uncover edge cases, inconsistencies, and unforeseen interactions. They’ll call it AI and raise funding, of course, conveniently ignoring the inevitable refactoring that awaits.
The Road Ahead
The pursuit of dynamic reasoning over temporal knowledge graphs, as exemplified by TKG-Thinker, inevitably encounters the limitations of formalized intelligence. The system demonstrates proficiency within a defined scope, yet the inevitable entropy of production environments will introduce data drift, unforeseen edge cases, and the relentless pressure to accommodate queries never anticipated during development. The illusion of autonomous reasoning will require constant recalibration-a more sophisticated maintenance cycle, not a solved problem.
Future iterations will likely focus on increasingly elaborate reward functions and more complex agent architectures. However, the core challenge remains: translating symbolic knowledge into actionable intelligence that resists the decay inherent in real-world application. The field doesn’t require more layers of abstraction-it needs a pragmatic acknowledgement that every elegant solution is merely a temporary reprieve from complexity.
The focus on agentic reinforcement learning is predictable. Each new framework promises to unlock ‘true’ reasoning, when history suggests only a refinement of existing crutches. The question isn’t whether TKG-Thinker advances the state of the art-it’s how quickly its innovations will become tomorrow’s technical debt. Perhaps the most fruitful path lies not in building smarter agents, but in accepting the inherent limitations of intelligence, artificial or otherwise.
Original article: https://arxiv.org/pdf/2602.05818.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-02-08 03:24