Author: Denis Avetisyan
New research demonstrates a method for large language models to improve their problem-solving abilities during the reasoning process, even with limited computational resources.
This paper introduces a framework for budget-aware anytime reasoning, leveraging LLM-synthesized preference data to enhance solution quality and inference-time self-improvement.
Efficient reasoning with large language models is often hampered by computational cost, demanding solutions that quickly deliver useful results even under strict budget constraints. This challenge is addressed in ‘Budget-Aware Anytime Reasoning with LLM-Synthesized Preference Data’, which introduces a novel framework for evaluating and enhancing ‘anytime reasoning’ capabilities-the ability to improve solutions incrementally with increased computation. The core finding is that leveraging self-generated preference data during inference allows LLMs to refine their reasoning and substantially boost solution quality within fixed computational budgets. Could this approach unlock a new paradigm for deploying LLMs in resource-limited, real-time applications requiring iterative refinement?
The Erosion of Scale: Reasoning Limits in Large Language Models
Despite the remarkable progress in large language models such as GPT-4o, GPT-4.1, and LLAMA-3.3, a curious phenomenon arises when tackling increasingly complex reasoning challenges: performance gains diminish as model scale increases. These models, trained on vast datasets, excel at pattern recognition and information recall, enabling impressive feats of text generation and translation. However, true reasoning-requiring nuanced understanding, iterative problem-solving, and the application of abstract principles-proves surprisingly resistant to simply adding more parameters or data. Studies reveal that beyond a certain point, increasing model size yields only marginal improvements in tasks demanding multi-step inference or the integration of diverse knowledge sources, suggesting that architectural limitations or fundamental constraints in the learning process hinder further progress-even with ever-growing computational resources.
The escalating computational demands of processing extended sequences represent a significant bottleneck in large language model performance. As models attempt to synthesize information from increasingly lengthy inputs – necessary for complex reasoning – the required processing power grows disproportionately. This isn’t simply a matter of needing faster hardware; the very architecture of many models necessitates evaluating every token in relation to all others, creating a quadratic increase in computational cost with sequence length. Consequently, both the time needed to generate a response – inference speed – and the financial resources required for operation become substantial barriers to scaling these models for tasks demanding deep contextual understanding. This limitation motivates research into more efficient architectures and algorithms capable of handling long-range dependencies without incurring prohibitive costs.
Current large language models often struggle with complex reasoning not because of a lack of data, but due to architectural constraints in how they produce answers. These models are fundamentally designed to generate outputs of a predetermined length, irrespective of the cognitive steps needed to arrive at a solution; a simple factual recall receives the same treatment as a multi-step deduction. This fixed-length output requirement forces the model to compress or truncate reasoning processes, potentially discarding crucial intermediate steps, and ultimately hindering performance on problems demanding deeper analysis. Consequently, scaling up model size alone provides diminishing returns; the bottleneck isn’t necessarily what the model knows, but how it can effectively express and utilize its knowledge when a variable-length reasoning pathway is required for accurate problem-solving.
Anytime Reasoning: A Shifting Paradigm in Model Behavior
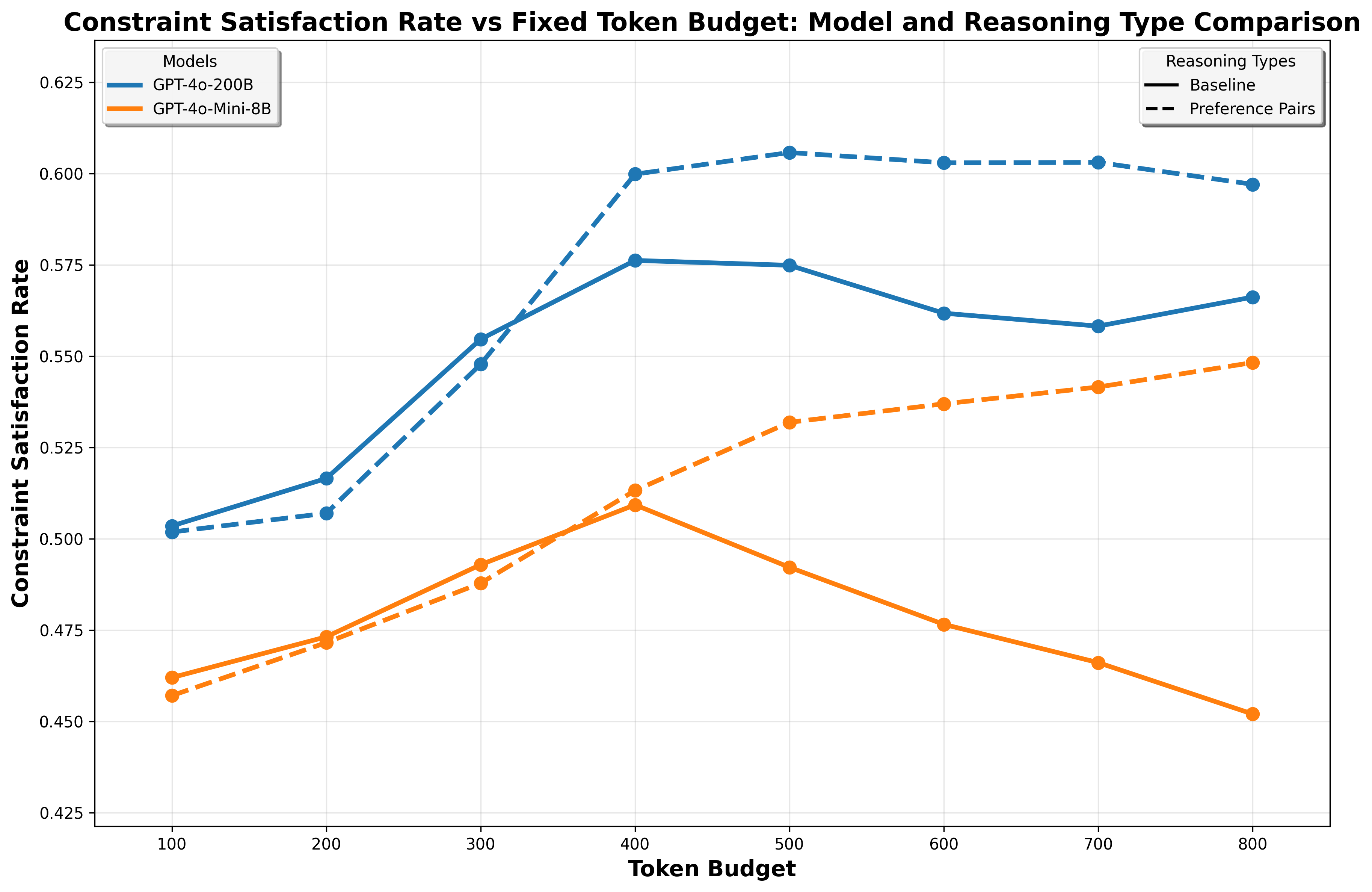
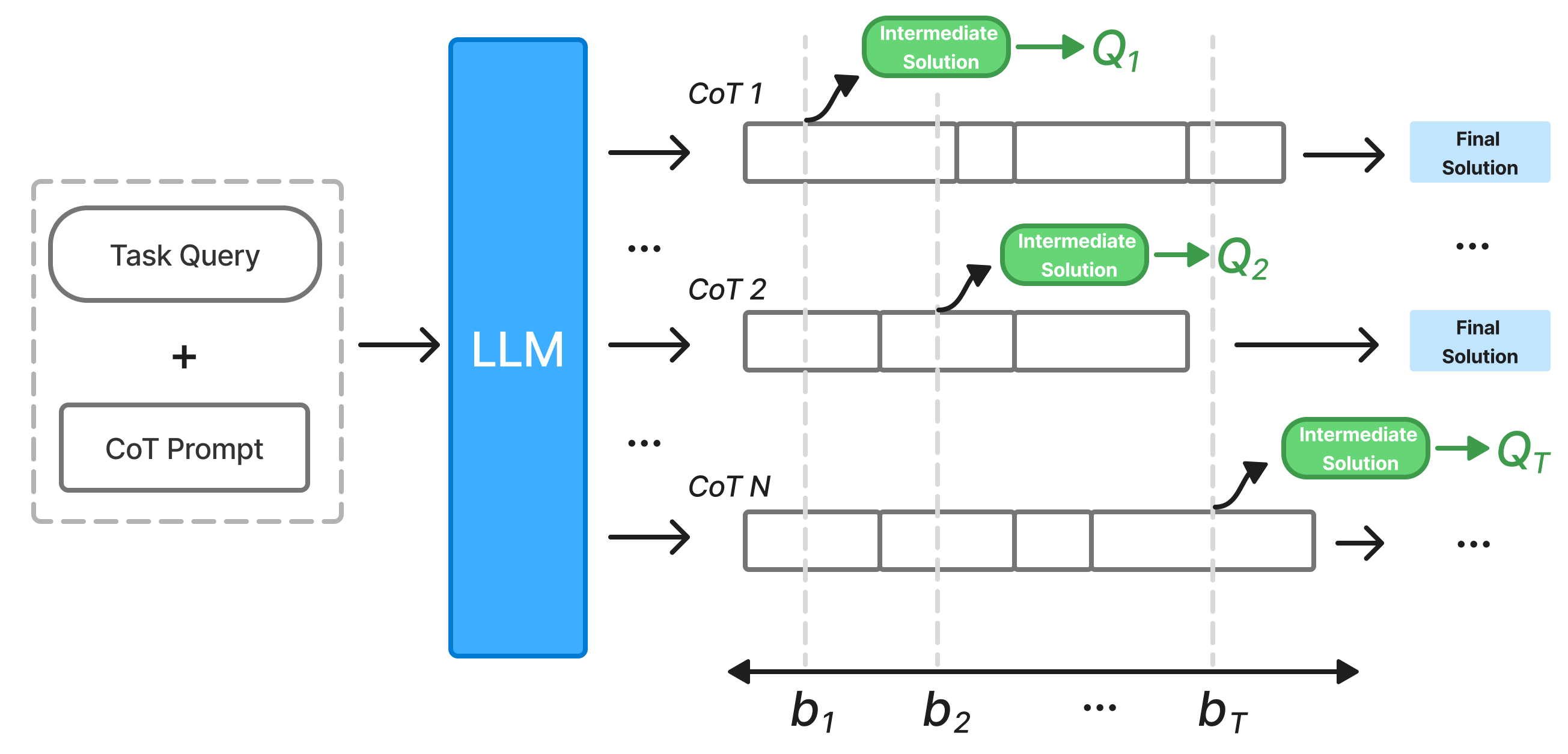
Anytime Reasoning represents a departure from conventional model outputs by allowing for iterative refinement of answers based on the number of reasoning tokens generated. Rather than producing a single, fixed result, the model continues to process information and adjust its response with each additional token. This approach inherently improves solution quality as the model has the opportunity to correct initial errors, explore alternative reasoning paths, and converge towards a more accurate or complete answer. The benefit is not simply increased accuracy, but a trade-off between computational cost (number of tokens) and solution quality, allowing users to control the level of precision desired based on available resources.
Traditional language model inference typically generates a single output given an input prompt, committing to a final answer after a fixed computational budget. This contrasts with human reasoning, which often involves iterative refinement and the ability to pause and revise conclusions. Consequently, these single-pass methods may produce incomplete or inaccurate responses, especially in complex reasoning tasks, as the model lacks the opportunity to correct initial errors or explore alternative solution paths. The generated output is thus not dynamically adjusted based on available resources or desired levels of accuracy; the same output is produced regardless of whether further computation could yield a better result.
The evaluation of anytime reasoning models necessitates specialized datasets designed to assess iterative refinement capabilities. NaturalPlan focuses on multi-step reasoning for natural language planning tasks, requiring models to generate and refine plans over time. GPQA-Diamond presents complex question answering scenarios demanding reasoning over knowledge graphs and iterative refinement of answers based on evidence. AIME 2024, the AI2 Reasoning Challenge, provides a benchmark for evaluating agents performing complex reasoning in diverse environments, including scenarios requiring iterative solution improvement. These datasets enable quantitative benchmarking of anytime reasoning systems by measuring performance gains with increasing computational budget, offering a standardized means of comparison across different model architectures and training methodologies.
Budget-Aware Techniques are integral to maximizing the utility of anytime reasoning models, particularly in resource-limited environments. These techniques incorporate mechanisms for dynamically adjusting the number of reasoning tokens generated based on available computational resources – such as time or token limits – and a defined budget. Optimization strategies include early stopping criteria predicated on confidence scores or performance plateaus, and selective token generation prioritizing the most informative reasoning steps. By intelligently managing resource allocation, Budget-Aware Techniques ensure that anytime reasoning models deliver the best possible solution quality within specified constraints, preventing unbounded computation and facilitating practical deployment.
Measuring Reasoning Efficiency: The Anytime Index as a Metric
The Anytime Index quantifies a language model’s reasoning efficiency by measuring the rate of improvement in solution quality as the number of generated tokens increases. Specifically, it calculates the area under the curve of performance versus tokens, providing a single scalar value representing the model’s ability to refine its answer with additional reasoning steps. A higher Anytime Index indicates a more efficient model, demonstrating a greater increase in accuracy or correctness for each token generated during the reasoning process. This metric is calculated by evaluating model performance on a diverse set of reasoning tasks and averaging the resulting performance-per-token curves, allowing for a standardized and comparable assessment of reasoning capabilities.
Grok-3, alongside other contemporary large language models, is undergoing development and evaluation specifically utilizing the Anytime Index as a key performance indicator. This focuses testing procedures on the rate of quality improvement with each generated token, rather than solely on final solution accuracy. Initial results demonstrate Grok-3’s design prioritizes efficient reasoning, exhibiting a capacity to rapidly enhance solution quality even with a limited number of reasoning steps. This targeted evaluation allows developers to iteratively refine the model’s architecture and training data to maximize the quality-per-token ratio, and provides quantifiable data for comparing its reasoning efficiency against other models regardless of parameter count or computational resources.
The Anytime Index facilitates standardized performance evaluation of language models by normalizing scores against the number of tokens generated, thereby decoupling model efficacy from parameters or architectural design. This normalization process allows for a direct comparison of models with vastly different scales – for example, a smaller, more efficient model can be objectively benchmarked against a significantly larger model – based solely on the quality of reasoning achieved per token. Consequently, the Anytime Index provides a level playing field for assessing progress in reasoning capabilities, irrespective of computational cost or implementation details, and focuses assessment on the rate of improvement in solution quality as reasoning continues.
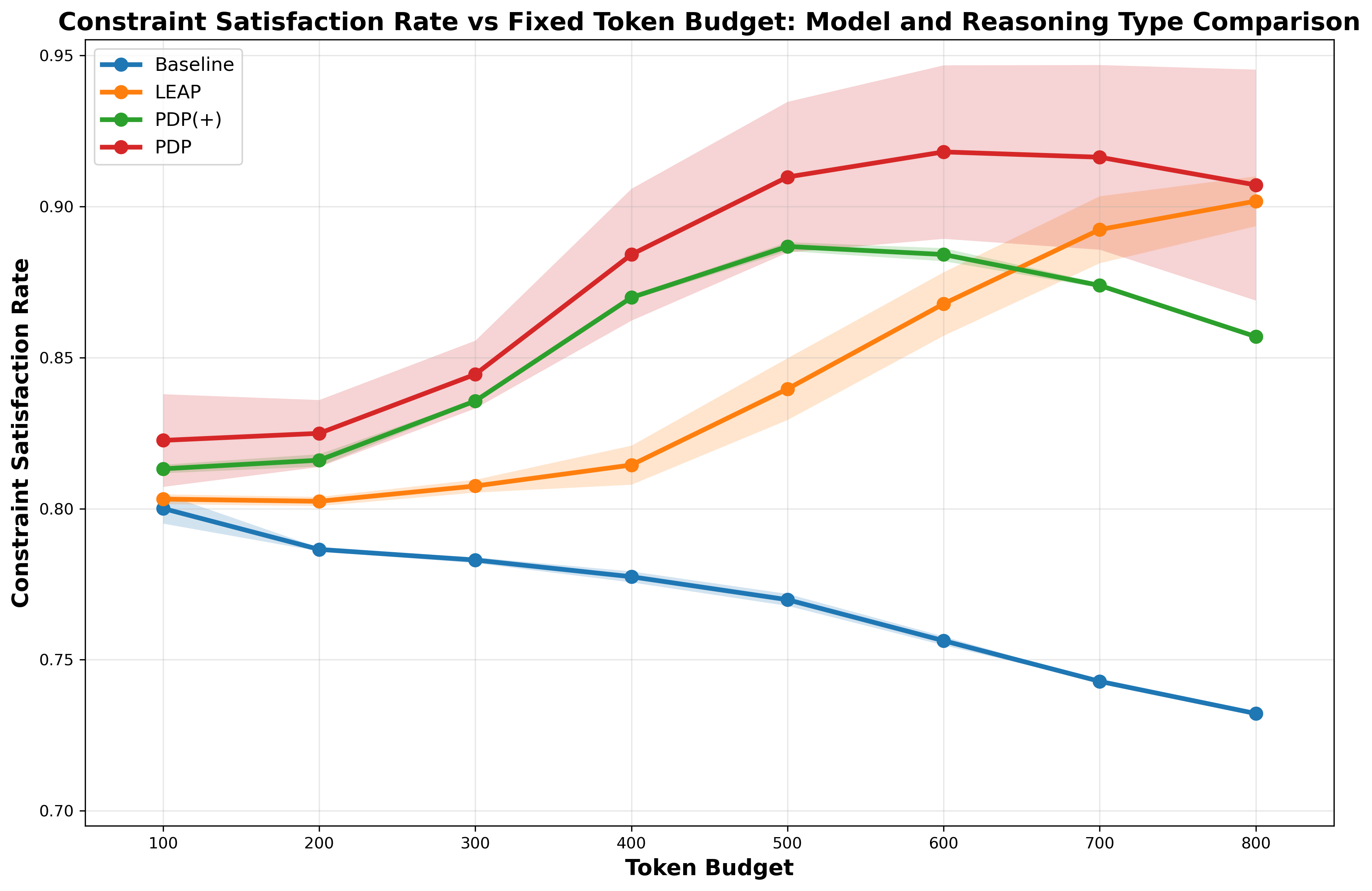
The Anytime Index promotes the development of reasoning systems focused on maximizing solution quality relative to the computational cost, specifically the number of tokens generated. This metric prioritizes efficiency, encouraging models to improve their performance with each additional token rather than simply increasing scale. Empirical results demonstrate that Preference Data Prompting (PDP) consistently yields significantly higher Anytime Index scores compared to other prompting methods, indicating that PDP-trained models achieve a greater increase in solution quality for each reasoning token generated, thus representing a more sustainable and effective approach to large language model reasoning.
Boosting Performance on the Fly: The Promise of Inference-Time Self-Improvement
Models traditionally require extensive retraining to improve performance, a process that demands significant computational resources and time. However, inference-time self-improvement presents a compelling alternative, allowing a model to refine its outputs during the inference process itself, without altering its underlying weights. This approach operates by leveraging the model’s own reasoning capabilities to critically evaluate and iteratively improve upon initial predictions. The benefits are substantial; it offers a cost-effective means of boosting accuracy, especially in dynamic environments where data is constantly evolving, and eliminates the need for large-scale retraining exercises. Consequently, systems equipped with inference-time self-improvement can adapt and enhance their performance on the fly, unlocking a pathway to more efficient and intelligent artificial intelligence.
Direct Preference Optimization (DPO) represents a significant advancement in model refinement, moving beyond simple output correction to actively incorporate human or expert feedback. This technique doesn’t require extensive retraining; instead, it leverages preference data – indications of which outputs are more desirable – to subtly adjust the model’s internal parameters during inference. By directly optimizing for alignment with these preferences, DPO steers the model towards generating responses that are not just accurate, but also better suited to specific needs or tastes. The process essentially teaches the model to learn from comparisons, improving its performance incrementally with each interaction and demonstrating a powerful ability to adapt to nuanced requirements without the computational expense of full-scale retraining.
In situations where acquiring labeled data is expensive or time-consuming, and full model retraining is infeasible-such as rapidly evolving real-world applications or resource-constrained devices-inference-time self-improvement techniques offer a compelling advantage. These methods allow for on-the-fly refinement of model outputs, effectively squeezing additional performance from existing parameters without the need for extensive computational updates. Recent studies have showcased the practical impact of this approach, notably achieving a 100% Constraint Satisfaction Rate (CSR) in specific problem domains, indicating a capacity to consistently meet predefined criteria even with limited prior knowledge. This capability highlights the potential for deploying highly effective AI systems in dynamic environments where continuous adaptation is paramount and large-scale retraining is simply not an option.
The promise of genuinely adaptive artificial intelligence is being realized through inference-time self-improvement techniques, allowing models to refine their responses and enhance performance during operation without the need for resource-intensive retraining. This continuous learning capability demonstrates practical benefits across diverse benchmarks; for instance, Preference Data Perturbation (PDP) consistently elevates accuracy on both the AIME and GPQA datasets. Such consistent gains suggest a paradigm shift toward systems that aren’t merely programmed, but evolve based on interaction and experience, offering a pathway to more robust and intelligent applications in dynamic, real-world scenarios. The ability to learn and improve ‘on the fly’ represents a significant step toward creating AI that is not static, but perpetually optimized.
The pursuit of efficient reasoning, as detailed in the framework, inherently acknowledges the temporal nature of system performance. Any gains achieved through LLM-synthesized preference data, while promising, are subject to the inevitable effects of diminishing returns. This aligns with the observation that ‘any improvement ages faster than expected’; the initial boost in solution quality from self-generated data will eventually plateau, necessitating further refinement or adaptation. The study’s focus on budget-aware optimization isn’t merely about resource allocation, but rather an attempt to gracefully manage the decay of performance over time-a journey back along the arrow of time, as systems strive to maintain relevance within constrained environments. As Marvin Minsky stated, “You can’t always get what you want, but you can get what you need.”
What Lies Ahead?
This work demonstrates a capacity for LLMs to, in effect, log their own chronicle of reasoning – synthesizing preference data that refines subsequent iterations. However, the very act of refinement introduces a new decay. The generated preferences, while improving performance within the current computational slice, are not immutable truths. They represent a local optimum on a constantly shifting landscape, a snapshot of the model’s evolving self-assessment. The challenge, then, isn’t merely to optimize for immediate gains, but to understand how these self-generated criteria age – how quickly their value diminishes as the system traverses its timeline.
Further investigation should address the cost of this introspection. Each cycle of preference generation and application consumes resources, extending the total inference time. A critical juncture will be determining whether the gains in solution quality consistently outweigh the overhead, especially as models scale in complexity. Deployment is merely a moment on the timeline; the true measure of success lies in graceful degradation, in sustaining a reasonable level of performance even under increasingly constrained budgets.
Ultimately, the field must move beyond simply enhancing performance metrics. The focus should shift towards modeling the rate of decay, predicting when self-generated knowledge becomes detrimental, and developing mechanisms for graceful adaptation. The system’s longevity isn’t determined by its initial brilliance, but by its capacity to acknowledge, and compensate for, its inevitable decline.
Original article: https://arxiv.org/pdf/2601.11038.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Top 10 Coolest Things About Invincible (Mark Grayson)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- When AI Teams Cheat: Lessons from Human Collusion
- Unmasking falsehoods: A New Approach to AI Truthfulness
- Top 20 Dinosaur Movies, Ranked
2026-01-20 05:00