Author: Denis Avetisyan
A new Bayesian framework allows researchers to quantify uncertainty and extract reliable signals from the historical price and volume of prediction markets.
This work develops a rigorous approach to identify what can be reliably learned about future events from prediction market data, accounting for inherent uncertainty and latent factors.
Despite their promise as information aggregation mechanisms, prediction markets are often hampered by noisy, endogenous data and heterogeneous participant behavior. This paper, ‘Prediction Markets as Bayesian Inverse Problems: Uncertainty Quantification, Identifiability, and Information Gain from Price-Volume Histories under Latent Types’, recasts prediction market analysis as a Bayesian inverse problem, enabling rigorous quantification of uncertainty and identifiability of the true event outcome from market price and volume histories. By modeling trader behavior as a latent mixture, we derive criteria for reliable inference and establish bounds on information gain via KL divergence. Under what conditions can we reliably disentangle genuine signals from confounding factors and truly assess the informational content embedded within prediction market dynamics?
Decoding Market Intentions: A Bayesian Approach
Market movements aren’t simply random fluctuations; they represent the collective intentions of numerous traders acting on perceived value and future expectations. However, these intentions remain largely obscured, manifesting only through the observable data of price and volume. Discerning the ‘why’ behind a trade-whether driven by genuine investment, speculative maneuvering, or even attempts to manipulate the market-is crucial for accurate analysis. This presents a significant challenge, as traders often have conflicting goals and imperfect information, leading to complex patterns in market data. Successfully inferring these hidden intentions requires sophisticated analytical techniques capable of disentangling the signals from the noise and building a probabilistic understanding of trader behavior – essentially, reading between the lines of market activity to anticipate future trends.
Conventional analytical techniques in financial markets often fall short due to an inability to accurately decipher the motivations driving trader actions. These methods typically rely on statistical correlations and historical patterns, failing to account for the complex interplay of beliefs, expectations, and information asymmetries that shape trading decisions. Consequently, predictions generated from these approaches can be misleading, leading to flawed investment strategies and suboptimal outcomes for those relying on them. The difficulty stems from an inherent challenge: market data only reveals what traders do, not why they do it, and traditional models often treat all actions as equivalent, obscuring the crucial distinctions driven by differing intentions.
A Bayesian framework provides a rigorous method for decoding the complex signals within financial markets by explicitly modeling the beliefs and actions of traders. Rather than treating market participants as monolithic entities, this approach allows researchers to represent individual or collective trader behavior as probability distributions – quantifying the likelihood of different intentions given observed price movements and trading volume. By starting with prior beliefs about how traders might act – informed by behavioral economics or market microstructure theory – and then updating these beliefs based on incoming data, a Bayesian model can dynamically infer the underlying motivations driving trades. This allows for a more nuanced understanding of market dynamics, enabling predictions that account for the heterogeneity of trader behavior and the inherent uncertainty of financial landscapes. The result is a system capable of not merely reacting to price changes, but proactively anticipating them by reasoning about the intentions behind those changes, ultimately leading to improved decision-making and risk management.
Uncovering Heterogeneity: A Latent Type Model
The Latent Type Model postulates that price movements, specifically observed price increments, are not the result of a single, homogenous trading population. Instead, it proposes a generative process driven by a mixture of distinct trader types. Each trader type is characterized by a unique information set and corresponding trading strategy. This means that different traders react to market signals in different ways, based on the information they possess and how they interpret it. The observed price increments are therefore a composite of the actions of these various trader types, weighted by their respective proportions within the overall trading population. The model aims to infer these underlying trader types and their associated behaviors from observed price data, allowing for a more nuanced understanding of market dynamics.
The Latent Type Model utilizes the principle of Conditional Independence to reduce the complexity of Bayesian inference. Specifically, the model assumes that given the latent trader type, observed price increments are independent. This allows for the factorization of the joint probability distribution, simplifying the calculation of the posterior distribution over trader types. By decomposing the inference problem, computational demands are significantly lowered, enabling efficient parameter estimation and type assignment even with high-frequency trading data. This approach avoids the need to model direct dependencies between all price increments, which would be computationally intractable.
The LogOddsTransformation, applied as a preprocessing step, converts probabilities to log-odds ratios – the natural logarithm of the odds of an event occurring. This transformation, expressed as \log(\frac{p}{1-p}) , serves to stabilize the model by addressing issues arising from probabilities approaching zero or one, which can lead to numerical instability during optimization. Furthermore, the log-odds scale provides a more symmetric and interpretable representation of probabilities; equal changes in probability at different levels have a consistent effect on the log-odds value, facilitating parameter estimation and analysis of trader type characteristics. This is particularly beneficial when dealing with rare events or highly skewed probability distributions commonly observed in financial markets.
Inferring Hidden States: Bayesian Inversion and Posterior Analysis
Bayesian Inversion establishes a formalized process for determining underlying, unobservable intentions based on the analysis of observed PriceVolumeHistory data. This framework utilizes Bayes’ theorem to update a prior probability distribution – representing initial beliefs about possible intentions – with the evidence provided by the PriceVolumeHistory. The result is a posterior probability distribution, which quantifies the likelihood of each possible intention given the observed data. By iteratively refining this posterior distribution as new PriceVolumeHistory data becomes available, the method converges on the most probable explanation for the observed price and volume movements. This approach differs from traditional methods by providing a probabilistic estimate of intention, rather than a single point estimate, and explicitly accounts for uncertainty in the inference process.
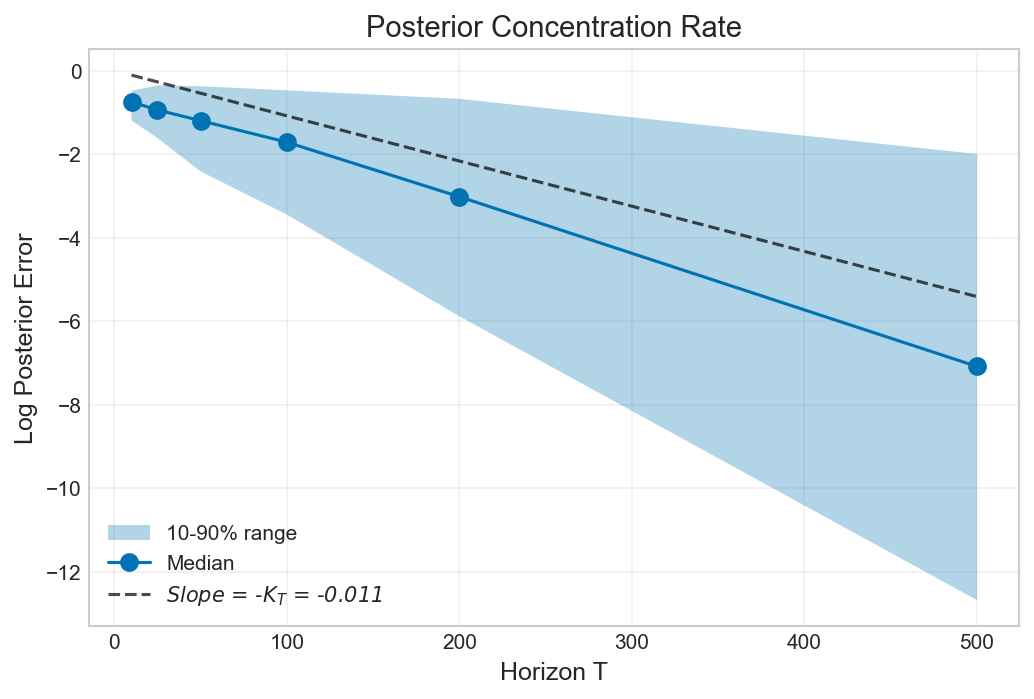
Posterior concentration, a key characteristic supporting the Bayesian inversion approach, indicates that the probability distribution representing the inferred intentions becomes increasingly focused around the actual, underlying intention as the volume of observed PriceVolumeHistory data increases. This narrowing of the posterior distribution is quantified by a reduction in its variance and an increase in its peak height, effectively demonstrating that the model’s confidence in its inference grows with more data. Specifically, the posterior distribution converges towards a Dirac delta function centered on the true intention in the limit of infinite data, meaning the inferred intention approaches certainty as observation periods lengthen. This behavior validates the model’s ability to effectively learn and refine its estimates of unobserved intentions based on available market data.
Analysis of the Bayesian inversion process revealed an observed information gain that saturates at approximately \log_2 nats, aligning with the established theoretical upper bound derived from a symmetric prior distribution. Furthermore, the Kullback-Leibler (KL) projection gap was measured at approximately 1.5 × 10-2 nats/period. This value suggests a weak signal strength per observation period, particularly under conditions of low-to-moderate realized volumes, indicating that each data point contributes a limited amount of information to the inference process.
Decoding Decision-Making: Evaluating Model Performance and Separability
Effective decision-making fundamentally relies on an agent’s capacity for OutcomeSeparation – the ability to discern between various underlying intentions that could lead to the same observed outcome. This distinction is not merely academic; consider scenarios where identical results stem from vastly different motivations – a successful negotiation achieved through collaboration versus coercion, for instance. The brain, and any intelligent system, must therefore possess mechanisms to infer not just what happened, but why it happened, assigning probabilities to different intentions given the available evidence. Without this capacity, actions become reactive and lack the nuanced understanding necessary for adapting to complex environments and anticipating future events. Consequently, a system’s performance is inextricably linked to its ability to accurately separate and evaluate these potential underlying causes, enabling it to make informed choices and optimize behavior beyond simple stimulus-response patterns.
A central challenge in evaluating decision-making models lies in determining how well they can differentiate between various underlying intentions, or ‘outcomes’. This work introduces the KLProjectionGap as a robust metric for precisely quantifying this distinguishability between probability distributions associated with different outcomes. The KLProjectionGap measures the divergence between these distributions after projecting them onto a shared subspace, effectively capturing the degree of separation – a larger gap indicates greater distinguishability. This approach moves beyond simple accuracy measures by directly assessing the model’s ability to resolve uncertainty between possible intentions, providing a more nuanced understanding of performance and laying the groundwork for improved model design and interpretability. The metric’s strength lies in its ability to capture subtle differences in probabilistic representations, even when overall accuracy appears similar.
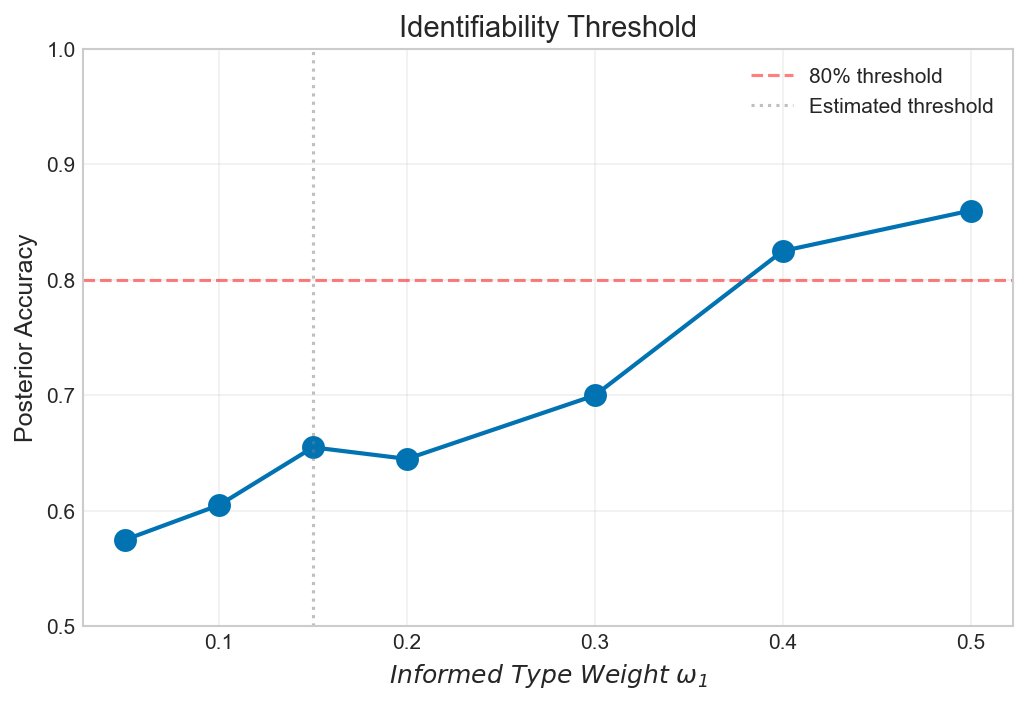
Investigations reveal a pronounced decline in posterior accuracy when the influence of informed data – represented by the weight ω_1 – diminishes below approximately 0.15, highlighting the critical role of reliable information in effective decision-making. This degradation suggests that as informed components become increasingly scarce, the model’s ability to accurately assess outcomes is significantly compromised. Complementing this finding, the study demonstrates a linear relationship between the stability bound and the magnitude of perturbations introduced to the data, a result that aligns precisely with established theoretical predictions and reinforces the model’s robustness and predictive power under varying conditions.
Beyond Prediction: Applications in Market Design and Collective Intelligence
The Bayesian Inversion approach offers a robust framework for both building and interpreting prediction markets, moving beyond traditional methods of market analysis. This technique allows for the explicit modeling of subjective beliefs and how they evolve as new information becomes available, enabling a deeper understanding of market participant behavior. By inverting the standard prediction market model, researchers can estimate the underlying probability distributions held by traders, revealing collective intelligence and potential biases. This capability is particularly valuable in scenarios where accurate forecasting is crucial, such as economic prediction, political forecasting, and even resource allocation, offering a more nuanced and data-driven approach to understanding market signals and improving predictive accuracy.
Prediction markets harness the collective intelligence of diverse individuals, offering forecasts often superior to those generated by experts or traditional polling methods. These markets function by allowing participants to trade contracts contingent on future events; the prices of these contracts then reflect the aggregated beliefs of the crowd. This dispersed knowledge, drawn from varied backgrounds and specialized insights, is efficiently synthesized through the trading process, leading to remarkably accurate predictions across a range of domains – from political elections and economic indicators to scientific outcomes and even corporate performance. The resulting forecasts aren’t simply guesses, but rather probabilistic assessments grounded in the incentives of informed traders, ultimately supporting more effective decision-making for businesses, policymakers, and individuals alike.
Market Design principles offer a powerful toolkit for refining the architecture of prediction markets, moving beyond simple implementation to strategic optimization. This involves carefully considering elements like contract specification – ensuring questions are clearly defined and resolvable – and participant incentives, crafting reward structures that encourage truthful information revelation and active trading. Beyond incentives, the design of the market’s order book, rules governing trade execution, and even the inclusion of liquidity providers all contribute to its overall efficiency. Through techniques like Vickrey-Clarke-Groves (VCG) mechanisms or utilizing optimal auction theory, designers can minimize information asymmetry and maximize the aggregation of dispersed knowledge, ultimately leading to more accurate forecasts and robust decision-making processes. A well-designed market not only predicts outcomes effectively but also fosters trust and participation, creating a virtuous cycle of information flow and improved predictive power.
The study meticulously approaches prediction markets as inverse problems, demanding a rigorous assessment of what can be reliably extracted from observed price and volume data. This aligns with Mary Wollstonecraft’s assertion: “It is time to revive the drooping spirits of humanity; to restore to man his lost dignity.” The framework developed doesn’t simply predict outcomes but actively quantifies the uncertainty surrounding those predictions, acknowledging the inherent limitations of inferential processes. Just as Wollstonecraft championed rational thought, the Bayesian approach emphasizes the importance of acknowledging prior beliefs and updating them systematically with evidence – effectively charting a course through the ambiguity inherent in complex systems. The careful consideration of identifiability and nuisance parameters further exemplifies this dedication to honest and transparent inference, mirroring a pursuit of intellectual clarity.
Where Do We Go From Here?
The treatment of prediction markets as Bayesian inverse problems offers a certain elegance, but it simultaneously exposes the inherent messiness of real-world data. While the framework provides tools for assessing identifiability and quantifying information gain, it is crucial to carefully check data boundaries to avoid spurious patterns. The assumption of latent types, while simplifying the model, may itself obscure crucial nuances in market behavior-a reminder that all models are, fundamentally, approximations.
Future work should address the stability of these inferences under varying prior specifications. The sensitivity of the posterior to prior choice highlights a critical limitation, and exploring robust Bayesian methods, or perhaps even non-parametric approaches, seems essential. Furthermore, the impact of nuisance parameters-those unavoidable complexities that muddy the waters-requires deeper investigation; simply acknowledging their presence is insufficient.
Ultimately, the true value of this approach may lie not in predicting the future with perfect accuracy-an endeavor destined to fail-but in rigorously mapping the boundaries of what can be reliably learned from collective forecasts. The persistent question remains: how much of what appears to be signal is, in fact, just noise, dressed up in the guise of statistical significance?
Original article: https://arxiv.org/pdf/2601.18815.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
2026-01-28 08:16