Author: Denis Avetisyan
A new deep learning method utilizes the power of diffusion models to improve the accuracy and robustness of ranking systems.
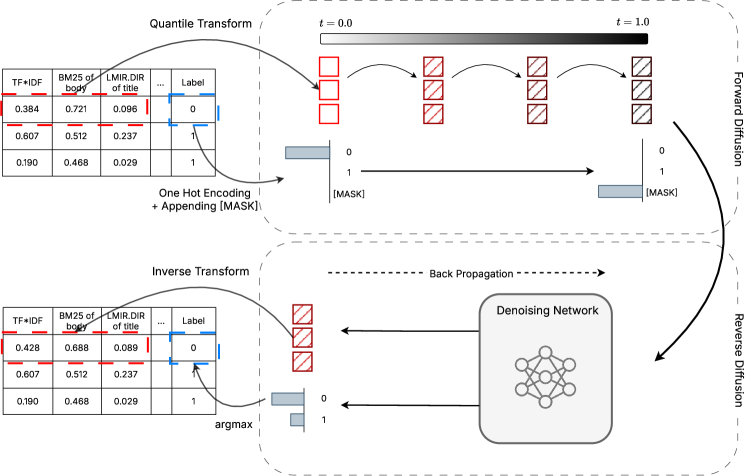
This review details DiffusionRank, a novel technique for learning to rank tabular data that jointly models features and relevance labels using generative modeling.
Traditional learning-to-rank methods often focus on discriminatively modeling relevance, potentially overlooking the underlying data distribution. This paper, ‘From Noise to Order: Learning to Rank via Denoising Diffusion’, introduces DiffusionRank, a novel generative approach leveraging diffusion models to jointly model tabular features and relevance labels. Empirical results demonstrate that DiffusionRank achieves significant improvements over discriminative counterparts by learning a more robust representation of the ranking process. Could this shift towards generative modeling unlock further advancements in information retrieval and relevance estimation?
The Essence of Effective Ranking
The efficacy of any information retrieval system hinges on its ability to accurately rank results, a factor profoundly impacting user experience and overall search quality. When presented with a multitude of options, individuals quickly assess relevance based on order; higher-ranked results receive disproportionately more attention, influencing whether a user finds what they need efficiently. Poor ranking not only frustrates users, leading to abandonment of the search, but also diminishes trust in the system itself. Consequently, substantial research focuses on refining ranking algorithms, recognizing that even incremental improvements can translate to significant gains in user satisfaction and a more productive information landscape. The fundamental principle remains: effective ranking isn’t simply about listing results – it’s about delivering the most relevant information, promptly and reliably.
Conventional learning-to-rank (LTR) methodologies, despite demonstrating considerable success in information retrieval, encounter limitations when dealing with the intricacies of real-world data. As the volume and diversity of online information increase, these methods often struggle to maintain performance due to the computational demands of training on massive datasets – a challenge known as scalability. Furthermore, complex data distributions, characterized by non-linear relationships and varying feature importance, can hinder the ability of simpler LTR models to accurately generalize and rank results effectively. This is because many traditional algorithms assume relatively straightforward data patterns, leading to diminished returns when confronted with the multifaceted nature of modern search queries and document collections. Consequently, research continually seeks more robust and efficient LTR approaches capable of handling these complexities without sacrificing accuracy or speed.
Current methods for establishing information relevance often fall short of fully utilizing the richness present in ‘Relevance Label’ data, which represents human judgements of search result quality. While these labels provide a crucial signal, existing algorithms frequently treat relevance as a single, monolithic value, neglecting the inherent gradations and subjectivity involved in assessing information. A search result deemed ‘relevant’ can vary significantly in its usefulness – ranging from marginally helpful to definitively answering a user’s query – and this nuanced understanding is often lost in simplification. Consequently, ranking systems may struggle to differentiate between subtly varying degrees of relevance, leading to suboptimal search results and a diminished user experience, as valuable information gets buried beneath less pertinent content.
A Generative Shift in Ranking
Generative Ranking utilizes Diffusion Models, a class of probabilistic generative models, to learn the underlying distribution of relevance data. Unlike traditional ranking models that predict a single relevance score, Diffusion Models learn to represent the entire probability distribution of ranked lists. This is achieved through a process of progressively adding noise to the data and then learning to reverse this process, effectively allowing the model to generate ranked lists that reflect the learned data distribution. By capturing the complexities of the data, these models demonstrate improved ranking accuracy and robustness, particularly in scenarios with limited or noisy training data, as they are less reliant on precise point estimates of relevance.
Traditional ranking systems typically predict a relevance score for each item, ordering results based on this single value; however, generative ranking models, leveraging diffusion processes, model the underlying probability distribution of relevance judgements. This distributional approach allows the model to capture more nuanced relationships within the data and generalize better to unseen queries and documents. By representing relevance as a distribution rather than a point estimate, the model accounts for inherent uncertainty and ambiguity in user preferences, leading to more robust rankings less susceptible to noise or variations in query formulation. This capability enables greater flexibility in incorporating diverse features and adapting to evolving user behavior without requiring extensive retraining or feature engineering.
Effective generative ranking with diffusion models necessitates distinct handling of numerical and categorical features due to their differing data types and distributions. Numerical features are typically diffused by adding Gaussian noise iteratively, allowing the model to learn a continuous representation of the data. Categorical features, however, require specialized diffusion processes, such as discretizing the noise or employing categorical diffusion mechanisms, to preserve the discrete nature of the data and prevent invalid states during the generation process. The efficacy of the ranking model is directly tied to the appropriate application of these diffusion techniques to each feature type, ensuring accurate modeling of the underlying data distribution and robust ranking performance.
Extending Tabular Diffusion to Ranking
DiffusionRank adapts the TabDiff model, initially developed for handling tabular data, to address the learning-to-rank problem. TabDiff utilizes a diffusion process to model the joint distribution of features, enabling effective data generation and imputation. By extending this framework, DiffusionRank leverages the established capabilities of TabDiff in feature modeling and applies them to the task of ranking documents for a given query. This adaptation allows the model to learn complex relationships between query and document features, ultimately facilitating improved ranking performance by modeling the underlying data distribution rather than relying solely on discriminative approaches.
DiffusionRank enhances ranking accuracy by modeling the intricate dependencies between user queries and relevant documents. Unlike traditional methods that often rely on feature engineering or shallow representations, DiffusionRank leverages a diffusion process to capture higher-order relationships. This is achieved through iterative refinement of document representations based on query context, allowing the model to discern nuanced relevance signals. The diffusion process effectively propagates information between queries and documents, enabling the model to understand which document characteristics are most indicative of relevance for a given query, ultimately leading to improved ranking performance across diverse datasets.
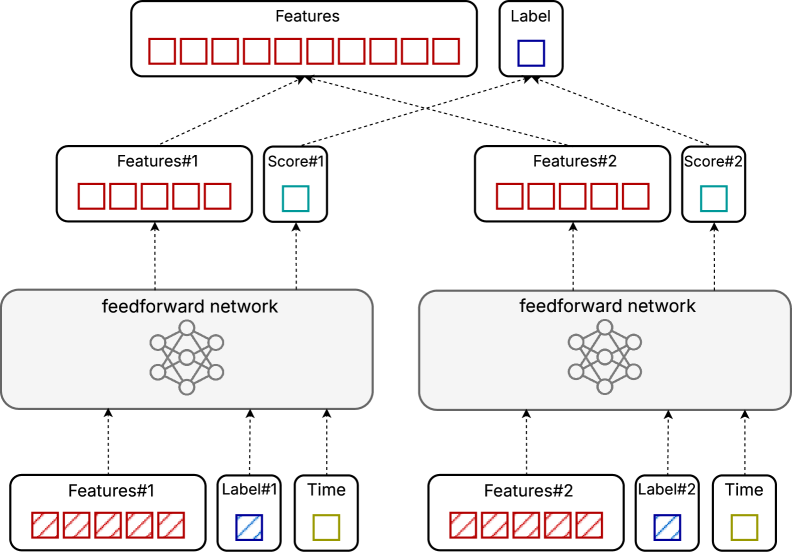
DiffusionRank accommodates both pointwise and pairwise learning-to-rank methodologies, enabling adaptable model construction. Pointwise approaches treat ranking as a regression problem, predicting relevance scores independently for each query-document pair. Conversely, pairwise methods focus on learning the relative order between document pairs for a given query, optimizing for correct pair-wise comparisons. This dual support allows practitioners to select the most appropriate strategy based on dataset characteristics and computational constraints; pairwise methods often yield higher accuracy but require greater computational resources, while pointwise methods offer a simpler, faster alternative.
The DiffusionRank model utilizes a Feedforward Network (FFN) architecture as its core component, serving as the basis for both its discriminative and generative processes. This FFN consists of multiple fully connected layers with non-linear activation functions, enabling the model to learn complex relationships between input features representing queries and documents. The discriminative component of the FFN is responsible for predicting relevance scores, while the generative component facilitates the diffusion process by modeling the distribution of relevance scores. This dual functionality allows DiffusionRank to both assess and refine ranking results, improving overall performance. The FFN’s parameters are learned during training to optimize the model’s ability to differentiate relevant from irrelevant documents and generate realistic relevance distributions.
Validating DiffusionRank: Performance and Benchmarks
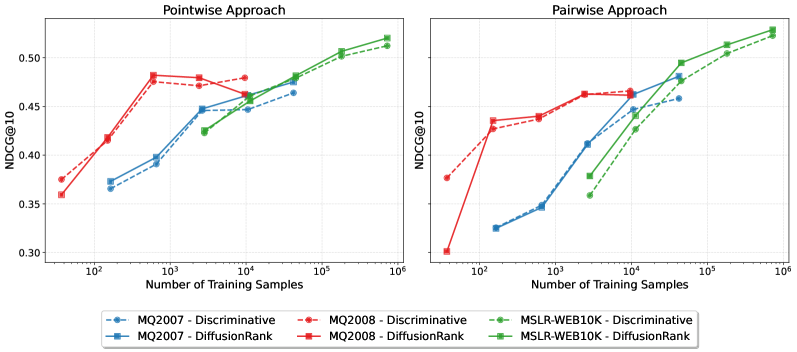
Rigorous evaluation of DiffusionRank across established datasets, notably LETOR 4.0 and MSLR-WEB10K, confirms its effectiveness in addressing complex ranking challenges. These datasets, comprising diverse query and document characteristics, served as critical benchmarks for assessing the model’s ability to accurately order search results. Performance across these datasets demonstrated DiffusionRank’s capacity to generalize beyond synthetic data, handling the nuances of real-world search queries. The consistent results obtained on both datasets highlight the robustness and practical applicability of the generative approach implemented in DiffusionRank, validating its potential for improving search relevance and user experience.
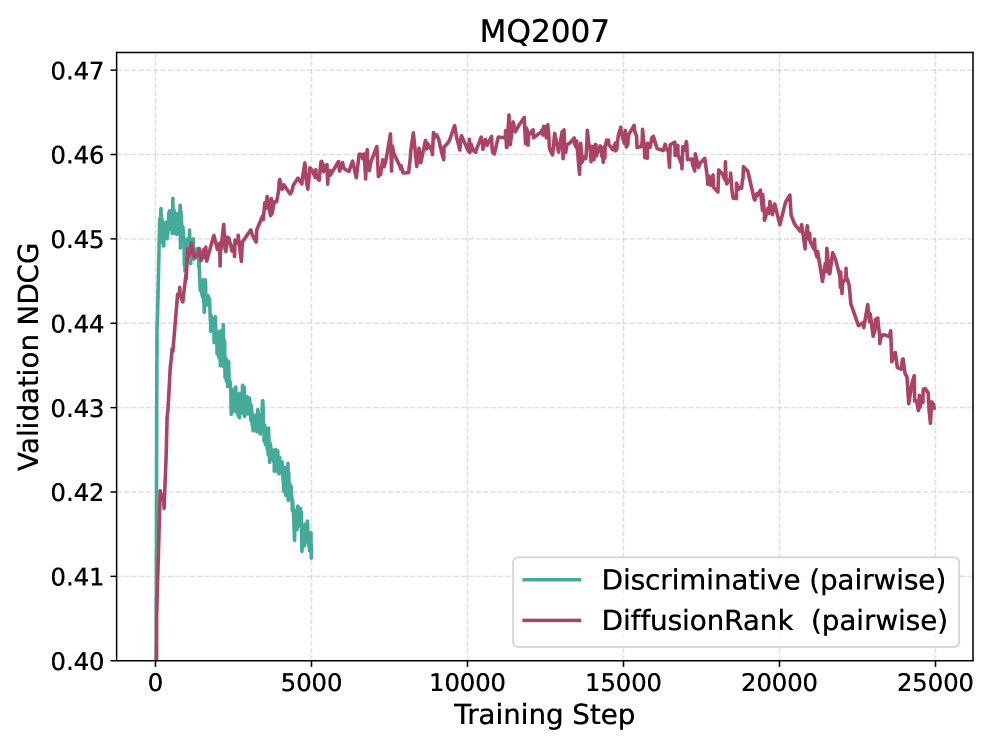
Evaluations demonstrate that DiffusionRank attains performance levels competitive with established learning-to-rank models, including XGBoost, as measured by standard metrics like Mean Average Precision (MAP) and Normalized Discounted Cumulative Gain (NDCG). Notably, the model consistently surpasses discriminative baseline approaches, showcasing significant improvements in both MAP@10 and NDCG@10. These results indicate DiffusionRank’s capacity to effectively re-rank search results, delivering more relevant content higher in the ranking and ultimately enhancing the user experience. The consistent outperformance suggests a robust methodology capable of addressing the complexities inherent in modern search ranking tasks.
Evaluations demonstrate that DiffusionRank’s generative approach offers a promising pathway for tackling the intricacies of complex ranking problems and enhancing search relevance. Across benchmark datasets – specifically MSLR-WEB10K and MQ2007 – the model consistently achieved statistically significant improvements (p < 0.05) compared to established methods. This suggests that by framing ranking as a generative process, DiffusionRank effectively captures nuanced relationships within data, leading to more accurate and meaningful results for users seeking information. The observed statistical significance reinforces the potential for generative models to move beyond discriminative techniques and fundamentally improve the quality of search experiences.
The pursuit of ranking, as demonstrated by DiffusionRank, often descends into a labyrinth of intricate features and complex models. It’s a field where engineers build elaborate structures to mask fundamental uncertainties. One observes a tendency to overcomplicate, believing that greater complexity equates to superior performance. Blaise Pascal keenly observed that, “The eloquence of the tongue consists not in its power to convince, but in its ability to express.” Similarly, this work suggests that true advancement in learning to rank isn’t about adding layers of abstraction, but distilling the core signal from noisy tabular data. The generative approach, by modeling the underlying distribution of relevance, offers a path toward a more elegant, and ultimately, more effective solution.
Further Steps
The current work demonstrates a generative approach to ranking-a worthwhile diversion from established discrimination. However, the inherent complexity of diffusion models invites scrutiny. Gains in accuracy must be weighed against computational cost. Simplicity, once abandoned, is rarely regained without significant effort.
A pressing concern remains the reliance on tabular data. Relevance is rarely, if ever, neatly arranged in rows and columns. Future work should explore the extension of this framework to more complex, unstructured inputs-text, images, and the messy signals of real-world user behavior. The model’s robustness, while noted, requires further testing against adversarial perturbations and distribution shifts-the inevitable consequences of deployment.
Ultimately, the value of any ranking system lies not in its theoretical elegance, but in its utility. The pursuit of ever-finer distinctions in relevance becomes, at a certain point, an exercise in diminishing returns. A more fruitful path may lie in prioritizing interpretability and user control-allowing individuals to shape the ranking process, rather than being subjected to its opaque logic.
Original article: https://arxiv.org/pdf/2602.11453.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- The Best Directors of 2025
2026-02-16 01:46