Author: Denis Avetisyan
Researchers have developed a system that continuously adapts to changing online conversations, allowing it to forecast emerging trends in real-time.
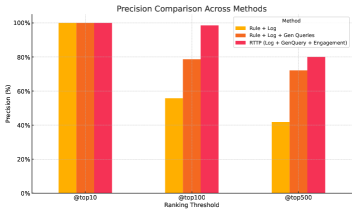
A novel approach utilizing continually-aligned large language models and a Mix-Policy Direct Preference Optimization strategy improves real-time trend prediction by generating and ranking synthetic search queries.
Detecting emerging trends in low-traffic search environments presents a fundamental challenge due to the scarcity of initial signals. This paper introduces a novel framework, ‘Real-Time Trend Prediction via Continually-Aligned LLM Query Generation’, which proactively generates synthetic search queries directly from news content to circumvent this cold-start problem. By leveraging a continually learning large language model (LLM) and a new preference-based continual learning approach-Mix-Policy DPO-the system achieves significant improvements in tail-trend detection and query accuracy. Can this proactive, LLM-driven approach unlock a new paradigm for timely understanding of evolving interests in sparse data landscapes?
Decoding the Noise: The Challenge of Dynamic Trends
The ability to detect emerging trends is paramount for organizations seeking to make informed and proactive decisions, yet conventional analytical techniques are increasingly challenged by the sheer velocity of modern data streams. Historically, trend analysis depended on examining static datasets or applying relatively simple predictive models; however, these approaches often lag behind real-time shifts in public opinion, consumer behavior, or technological advancements. This discrepancy arises because data is no longer accumulating at a steady rate – it is now characterized by exponential growth and constant flux, demanding methodologies capable of processing information as it unfolds rather than in retrospect. Consequently, a significant gap exists between the potential for data-driven insight and the practical ability to extract actionable intelligence from rapidly changing information landscapes, necessitating innovation in trend detection technologies.
Traditional methods for tracking public opinion frequently stumble when confronted with the velocity of modern online discourse. Analyses dependent on static datasets, or those employing overly simplified models, often present a distorted view of rapidly shifting trends. These approaches struggle to discern the subtle contextual cues – sarcasm, evolving slang, or nuanced sentiment – that significantly alter the meaning of online conversations. Consequently, interpretations can lag behind real-time changes in public interest, leading to inaccurate assessments and potentially flawed decision-making. The dynamic nature of online platforms demands analytical tools capable of adapting to, and interpreting, the constant flux of information – a capacity frequently absent in conventional methodologies.
The sheer volume of digital text – social media posts, news articles, blog comments, and online forums – presents a substantial challenge to understanding evolving public opinion. Traditional analytical methods are often overwhelmed by this data’s scale and, crucially, its unstructured nature. Extracting meaningful signals from this noise requires not simply counting keywords, but discerning subtle changes in language, identifying emerging themes, and recognizing the context surrounding discussions. The difficulty isn’t merely about finding information, but about efficiently processing and interpreting it to accurately detect genuine shifts in public interest before they solidify into established trends. This necessitates sophisticated natural language processing techniques capable of handling ambiguity, sarcasm, and the ever-changing lexicon of online communication.
Anticipating the Turn: A System for Real-Time Trend Prediction
The Real-Time Trend Prediction (RTTP) system operates by constructing a series of synthetic queries designed to mirror the language and topics currently prevalent in online conversations. These queries are not derived from existing search data, but rather generated algorithmically to represent the evolving landscape of online discourse. A weighting mechanism is then applied to these synthetic queries, prioritizing those that demonstrate a higher correlation with emerging trends as identified through data acquisition platforms. This approach allows the RTTP system to proactively identify and predict trends before they become widely reflected in conventional search data, enabling a more responsive and forward-looking trend detection capability.
The core of the RTTP system is CL-LLM, a language model designed to convert unstructured text data – such as social media posts and online comments – into formalized search queries. This transformation process involves natural language processing techniques to identify key entities, intents, and relationships within the text. The resulting structured queries are then used to probe data sources for emerging trends. Crucially, CL-LLM is continually updated with new data streams, allowing it to adapt to evolving language patterns and maintain accuracy in query generation over time. This continuous learning capability distinguishes it from static query methods and enables the RTTP system to provide more responsive and relevant trend predictions.
Traditional trend prediction methods often rely on static datasets or pre-defined keywords, limiting their ability to adapt to rapidly evolving online discourse. The RTTP system addresses this limitation through continuous learning; its underlying CL-LLM is regularly updated with new data from platforms like Facebook Search and Meta AI App. This dynamic updating process allows the system to refine its query generation and weighting algorithms in near real-time, enabling it to identify and predict emerging trends with significantly improved responsiveness compared to static approaches. The resulting +91.4% relative improvement in precision@500 demonstrates the efficacy of this continuous learning methodology in enhancing trend detection accuracy.
The Real-Time Trend Prediction (RTTP) system leverages data acquisition and evaluation through platforms including Facebook Search and the Meta AI App. Performance metrics demonstrate a +91.4% relative improvement in precision@500 for trend detection when compared to baseline methodologies. Precision@500 specifically measures the proportion of relevant trends identified within the top 500 predicted trends, indicating a substantial increase in the system’s ability to accurately identify emerging topics. This improvement is calculated relative to the performance of the baseline methods used for comparison, highlighting the efficacy of the RTTP system’s approach to real-time trend analysis.

Preserving Knowledge: Combating Catastrophic Forgetting
Continual learning (CL) models, including CL-LLM, exhibit a phenomenon known as catastrophic forgetting. This occurs because the sequential learning process, while allowing adaptation to new data, destabilizes previously acquired knowledge. Standard neural networks trained incrementally tend to overwrite existing weights when presented with novel information, resulting in a rapid decline in performance on older tasks. Unlike human learning, which features robust knowledge retention and the ability to integrate new information without wholesale erasure of prior learning, CL models lack inherent mechanisms to preserve past knowledge during updates, necessitating specialized techniques to mitigate this degradation.
Mix-Policy Direct Preference Optimization (DPO) is implemented as a training strategy to address catastrophic forgetting in continual learning models. This approach combines on-policy data, generated from the current model policy, with off-policy data sourced from previous model iterations or a static dataset. By integrating both data types, the model benefits from the stability of established knowledge embedded in the off-policy data, while simultaneously adapting to new information through on-policy learning. This blended approach reduces the tendency for new training data to drastically overwrite previously learned parameters, resulting in improved retention of existing capabilities and a more robust learning process.
Mix-Policy Direct Preference Optimization (DPO) extends the DPO algorithm by specifically addressing the ‘squeezing effect’, a phenomenon where models trained with DPO can exhibit reduced diversity in their reasoning processes. Standard DPO can overly optimize for the preferred response, leading to a narrowing of the solution space and potentially hindering performance on tasks requiring varied approaches. Mix-Policy DPO mitigates this by incorporating off-policy data alongside the on-policy preference data used in traditional DPO. This blended approach encourages the model to maintain a broader range of reasoning pathways, preventing the convergence towards a single, potentially suboptimal, solution and thereby improving overall robustness and generalization capabilities.
Evaluation using the Massive Multitask Language Understanding (MMLU) benchmark indicates that CL-LLM exhibits improved reasoning and resistance to catastrophic forgetting during continual learning. Specifically, the model maintained approximately a 5% decrease in accuracy after one month of continuous training. In contrast, models trained using Supervised Fine-Tuning (SFT) demonstrated near-total performance degradation over the same period, indicating a significantly reduced ability to retain previously learned information when exposed to new data. This performance differential highlights the efficacy of the Mix-Policy DPO strategy employed in CL-LLM for mitigating catastrophic forgetting.

Beyond Prediction: Broad Impact and Future Directions
The Real-Time Trend Prediction (RTTP) system represents a significant advancement in the ability to discern emerging patterns across diverse fields. By leveraging the capabilities of a Chain-of-Logic Large Language Model (CL-LLM) and a Mix-Policy Direct Preference Optimization (DPO) approach, the system dynamically adapts to the ever-changing landscape of online information. This architecture allows RTTP to not merely identify existing trends, but to anticipate shifts in public sentiment and behavior with a high degree of accuracy. Consequently, the system offers a valuable tool for sectors ranging from market analysis and proactive public health interventions to effective crisis management and any discipline where understanding evolving patterns is paramount, offering a responsive and scalable solution for data-driven decision-making.
The ability to rapidly identify emerging trends holds substantial promise across diverse sectors, extending far beyond simple market analysis. In marketing, the system offers the potential to preemptively respond to shifting consumer preferences and tailor campaigns with unprecedented precision. Public health organizations can leverage similar insights to detect early signals of disease outbreaks or monitor the spread of health misinformation, enabling faster and more effective interventions. Crisis management teams benefit from the capacity to gauge public reaction to events in real-time, facilitating targeted communication strategies and resource allocation. Ultimately, any field that depends on accurately interpreting public opinion – from political campaigns to social movements – stands to gain from a tool capable of distilling meaningful signals from the vast ocean of online data and anticipating shifts in collective sentiment.
Efforts are underway to enhance the Real-Time Trend Prediction (RTTP) system by incorporating advanced time-series analysis techniques. Specifically, researchers plan to integrate models like InceptionTime – a sophisticated approach currently utilized in Amazon’s trend detection infrastructure – to refine the system’s predictive capabilities. This integration aims to move beyond simple query generation accuracy and capture the dynamic evolution of trends over time. By analyzing sequential data patterns, the combined system anticipates a more nuanced understanding of emerging topics and a strengthened ability to forecast future shifts in online activity, potentially delivering earlier and more reliable trend insights across diverse applications.
The Real-Time Trend Prediction (RTTP) system demonstrates a high degree of precision in formulating search queries, achieving an accuracy of 90.5% – a significant improvement over standard Supervised Fine-Tuning (SFT) baselines, with initial gains reaching 4%. This performance suggests the system’s capacity to effectively capture evolving online interests. Further refinement is anticipated through the integration of statistical techniques, specifically the Poisson Model – a method already utilized by platforms like Google Trends and X to monitor and interpret fluctuations in search volume. Implementing this model promises to heighten the RTTP system’s sensitivity, enabling it to detect even the most nuanced and subtle shifts in online activity, and ultimately provide more accurate and timely trend predictions.

The pursuit of real-time trend prediction, as detailed in this work, demands a system capable of adaptation without succumbing to the pitfalls of catastrophic forgetting. The presented RTTP system, utilizing continual learning and a Mix-Policy DPO strategy, aims for precisely this – a refinement, not a replacement, of existing knowledge. This aligns with Ada Lovelace’s observation: “The Analytical Engine has no pretensions whatever to originate anything.” The engine, like RTTP, functions by processing and reorganizing information, continuously aligning its query generation to reflect the evolving landscape of social media trends. The value lies not in inventing new data, but in efficiently discerning patterns within the existing flow.
What’s Next?
The presented system, while demonstrating a capacity for adaptive query generation, merely skirts the fundamental issue of signal versus noise. Social media, by its nature, is an amplifier of both. Future work must confront not simply how to predict trends, but whether those trends deserve prediction-or are, in fact, transient artifacts of algorithmic echo chambers. The Mix-Policy DPO strategy offers a refinement of continual learning, but it does not solve the core problem of catastrophic forgetting; it merely manages it. A more radical approach might involve a deliberate forgetting mechanism, a controlled pruning of learned associations to prioritize genuine, durable signals.
The current focus on query generation, while pragmatic, risks treating the symptom rather than the disease. True trend prediction requires a deeper understanding of the underlying generative processes – the cultural, economic, and psychological forces that create trends. The system could be re-envisioned as a framework for hypothesis testing, generating queries not to predict what will be popular, but to validate existing theories about the drivers of social change. Such a shift demands a move away from purely predictive metrics toward explanatory ones.
Ultimately, the value of this work-and of the broader field-lies not in perfecting the art of anticipation, but in cultivating a healthy skepticism toward it. The simplest model, stripped of unnecessary complexity, remains the most elegant – and, often, the most accurate. Perhaps the next step isn’t to build a better predictor, but to build a better filter.
Original article: https://arxiv.org/pdf/2601.17567.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Silver Rate Forecast
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
2026-01-27 20:43