Author: Denis Avetisyan
New research reveals that discrete diffusion models can efficiently solve complex planning tasks by leveraging structural asymmetry, surpassing the performance of traditional autoregressive methods.
Discrete Diffusion Models exploit reverse-decoding and asymmetry to achieve superior sample efficiency in lookahead planning compared to Transformer-based autoregressive models.
While Autoregressive (AR) models dominate generative tasks, their efficacy in multi-step lookahead planning remains questionable. This is addressed in ‘Discrete Diffusion Models Exploit Asymmetry to Solve Lookahead Planning Tasks’, which investigates the contrasting mechanisms of AR versus Non-Autoregressive (NAR) models-specifically Discrete Diffusion Models-when tackling such problems. The study reveals that NAR models leverage a critical asymmetry in planning-deterministic reverse generation contrasting with complex forward traversal-to decode solutions backward, achieving superior sample efficiency. Could this reverse-decoding strategy unlock a new paradigm for efficient planning in artificial intelligence?
The Illusion of Foresight: Autoregression’s Planning Bottleneck
Large language models, fundamentally built on autoregressive principles, demonstrate a remarkable capacity for predicting the subsequent element within a sequence – be it a word in a sentence or a character in a text string. However, this strength doesn’t readily translate to scenarios demanding intricate, multi-step planning. The models operate by iteratively extending existing sequences, making them proficient at continuing a thought but less adept at proactively strategizing across several distinct phases. This limitation arises because autoregressive systems are optimized for local coherence – ensuring the next prediction fits the immediate context – rather than global optimization, where the model must consider the long-term consequences of each action and evaluate numerous potential future states. Consequently, while fluent in generating text, these models often falter when confronted with tasks requiring foresight, resource management, or the exploration of diverse solution pathways.
The architecture of current large language models, while impressive in its ability to generate coherent text, fundamentally prioritizes predicting the immediate next word over formulating long-term strategies. This training paradigm, known as Causal Next-Token Prediction, optimizes for fluency – ensuring grammatical correctness and contextual relevance – but inadvertently neglects the development of genuine reasoning skills. Consequently, these models often excel at mimicking human language patterns without possessing a robust capacity for planning or anticipating the consequences of actions beyond the very near future. The emphasis on sequential prediction creates a system adept at completing patterns, but deficient in the ability to explore hypothetical scenarios or evaluate the effectiveness of different approaches – essentially trading strategic foresight for linguistic proficiency.
The inherent nature of autoregressive (AR) models presents a substantial bottleneck when confronted with complex planning tasks. Because these models process information sequentially, predicting one step at a time, they struggle to efficiently explore the branching possibilities inherent in multi-step reasoning. This limitation effectively restricts the ‘planning horizon’ – the number of future steps the model can realistically consider – and necessitates an enormous volume of training data to achieve performance comparable to systems capable of more holistic future state evaluation. Consequently, AR models often require exponentially more examples to master tasks demanding foresight and strategic exploration, revealing a fundamental deficiency in sample efficiency and hindering their application to real-world problems requiring robust, long-term planning.
Parallel Paths: Non-Autoregressive Models and the Promise of Efficient Planning
Non-autoregressive (NAR) models diverge from traditional autoregressive approaches by generating all output tokens simultaneously, rather than sequentially. This parallel generation capability fundamentally alters the computational profile of the model, eliminating the sequential dependencies that constrain autoregressive decoding. Consequently, NAR models offer significant potential speedups, particularly during inference. The ability to explore multiple potential solutions in parallel also enhances efficiency in tasks requiring search or planning, allowing the model to evaluate a wider range of options within a given computational budget and potentially identify optimal solutions more rapidly.
Non-autoregressive models differ from their autoregressive counterparts by not conditioning future token generation on previously generated tokens. This allows for the simultaneous consideration of the entire input sequence, enabling the model to leverage bidirectional context during decision-making. Specifically, each token’s generation can be informed by both preceding and subsequent tokens, offering a more comprehensive understanding of the sequence dependencies than sequential, unidirectional processing. This capability is achieved through mechanisms like attention mechanisms that process the entire input at once, rather than iteratively, facilitating a more holistic assessment of the input data for each generated token.
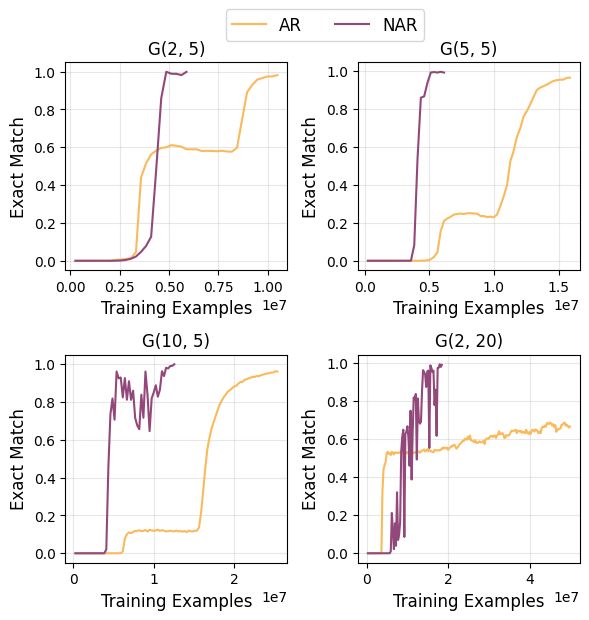
Non-autoregressive (NAR) models offer significant efficiency gains in planning tasks due to their parallel processing capability, which allows simultaneous evaluation of multiple potential solution paths. Empirical results demonstrate NAR models converge with exponentially fewer training examples compared to autoregressive (AR) models. This accelerated convergence is directly attributable to the parallel evaluation; AR models, constrained by sequential generation, require proportionally more data to achieve comparable performance. The ability to process information in parallel fundamentally alters the learning dynamic, enabling NAR models to rapidly refine their planning strategies with reduced data requirements.
Planning as Navigation: Formalizing the Problem as Graph Traversal
The planning problem is formalized as a graph traversal, enabling the application of established graph search algorithms. In this framework, each possible state of the system is represented as a node within the graph. Actions that transition the system from one state to another are defined as directed edges connecting these nodes. This representation allows planning to be viewed as finding a path from a defined start node, representing the initial state, to a goal node, representing the desired outcome. The efficiency of this approach relies on the ability of graph search algorithms – such as A*, Dijkstra’s algorithm, or Breadth-First Search – to navigate this state-action graph and identify an optimal or feasible sequence of actions.
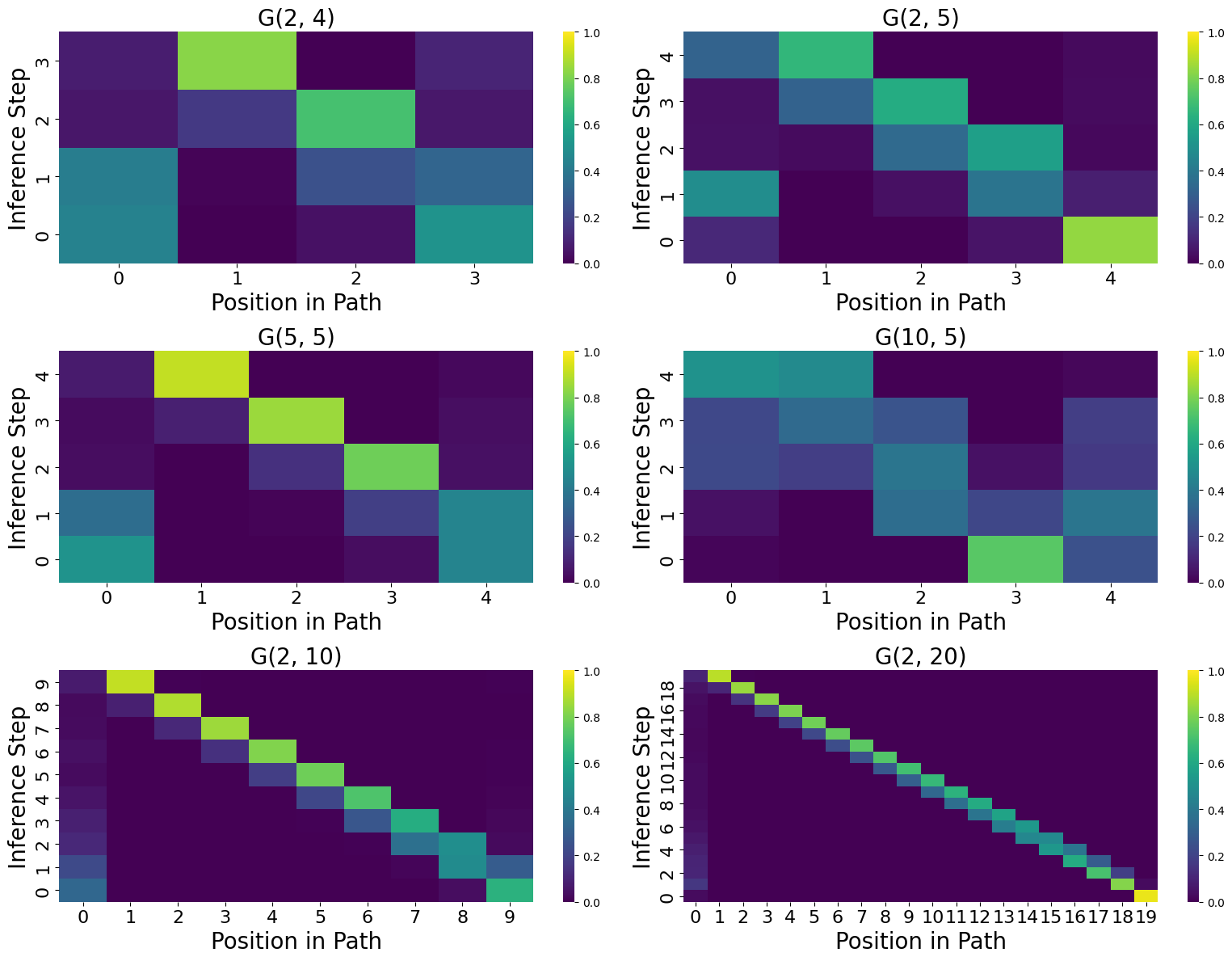
The reverse decoding strategy within Discrete Diffusion Models facilitates action planning by initiating the search for a solution from a defined goal state. Rather than generating a plan forward from an initial state, the model iteratively steps backward, identifying the preceding state and corresponding action that would lead to the current state. This process is repeated until the starting state is reached, effectively constructing a complete sequence of actions – the plan – in reverse order. The resulting action sequence can then be reversed to provide a forward-facing plan for achieving the goal. This approach leverages the probabilistic framework of diffusion models to explore potential action sequences and identify those that successfully connect the goal to the starting state.
First-order transitions, in the context of Discrete Diffusion planning, define state transitions based solely on the current state and a single action. This means the next state is determined directly from the present state without considering prior states or a history of actions. Utilizing these transitions allows for efficient graph exploration because the model only needs to evaluate immediate neighbors of a given node to determine possible next steps. Consequently, pathfinding algorithms can quickly traverse the graph, focusing solely on these direct connections to identify a sequence of actions leading from the initial state to the goal state, contributing to the computational efficiency of the planning process.
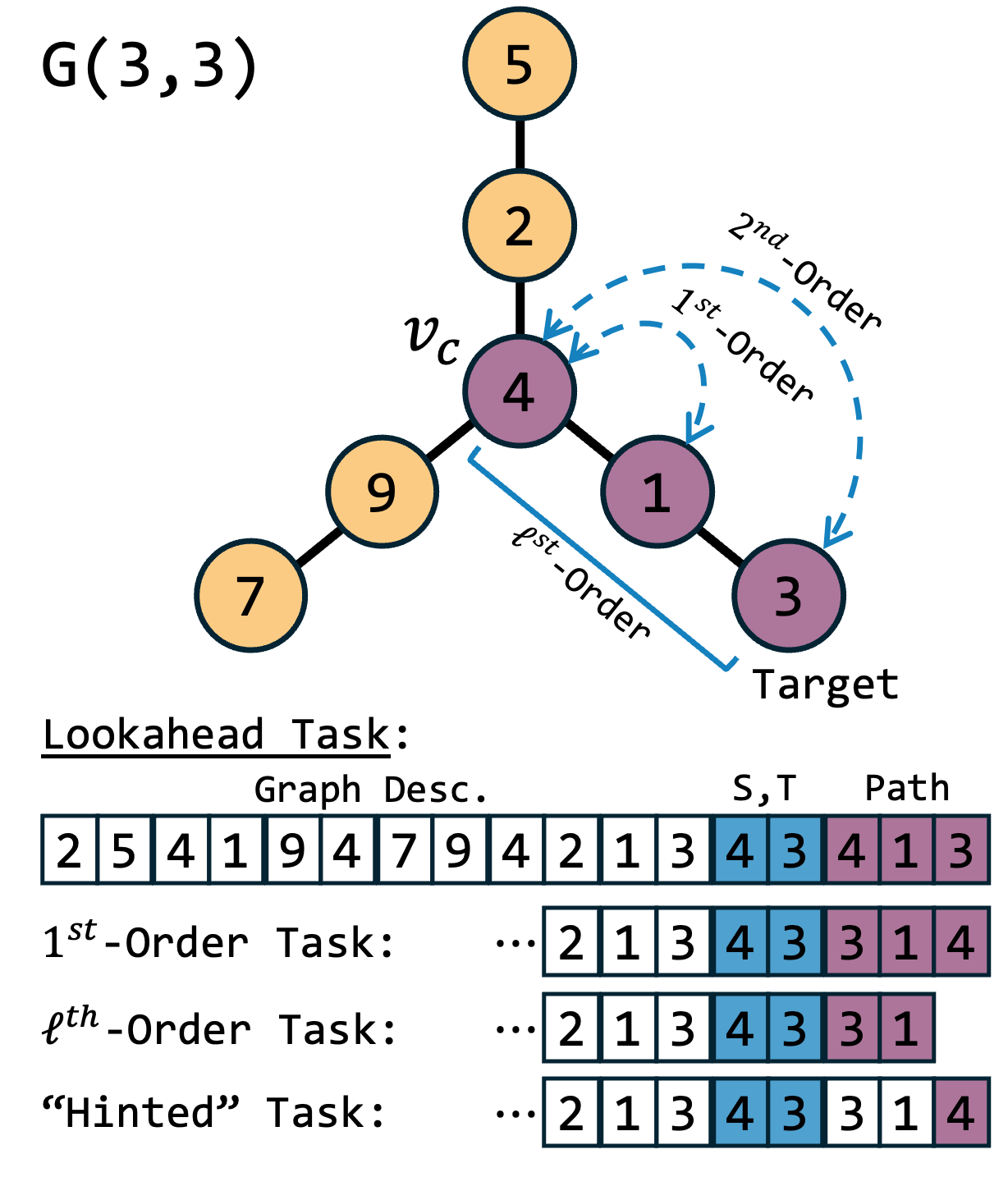
Strategic Reasoning: Validating NAR Models with the Star-Path Task
The Star-Path Task is designed to assess an agent’s capacity for sequential planning within a simplified, yet representative, environment. This task utilizes a ‘Star-Graph’ structure, consisting of a central node connected to multiple peripheral nodes; an agent must navigate from a starting peripheral node to a target peripheral node, passing through the central node. The controlled structure of the Star-Graph allows for systematic variation of path length and complexity, enabling precise measurement of planning performance as the number of steps required to reach the goal increases. This controlled environment isolates the planning ability, minimizing the influence of perception or low-level motor control, and providing a robust benchmark for evaluating different planning algorithms and architectures.
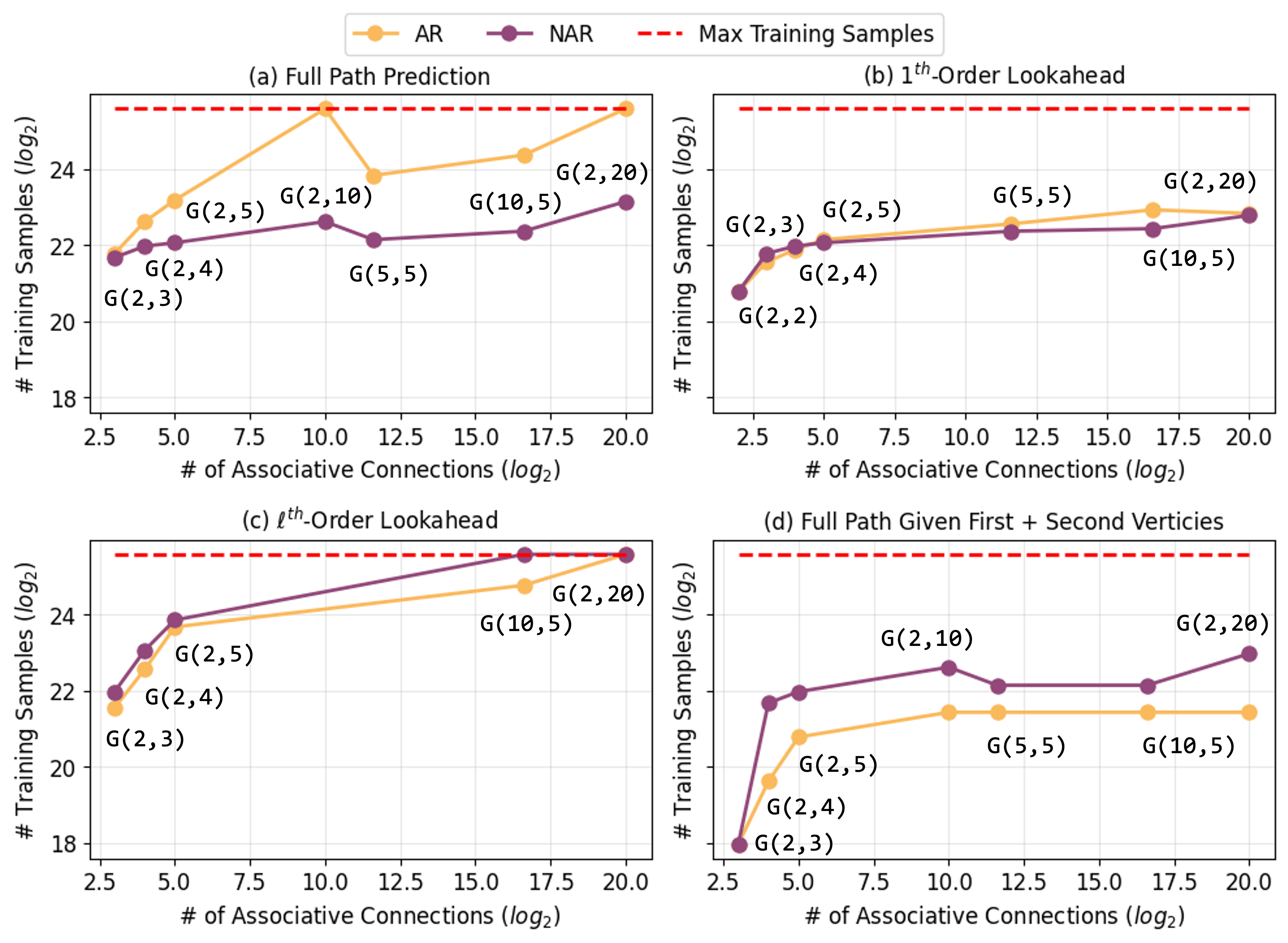
Discrete Diffusion Models, when trained using a reverse decoding strategy on the Star-Path Task, exhibit performance advantages over autoregressive (AR) models. While both AR and Non-Autoregressive (NAR) models are capable of achieving perfect accuracy on this task, NAR models demonstrate substantially improved data efficiency. Specifically, NAR models require significantly less training data to reach perfect accuracy compared to their AR counterparts, indicating a more effective learning process and potentially better generalization capabilities within the constraints of the Star-Path Task’s structure.
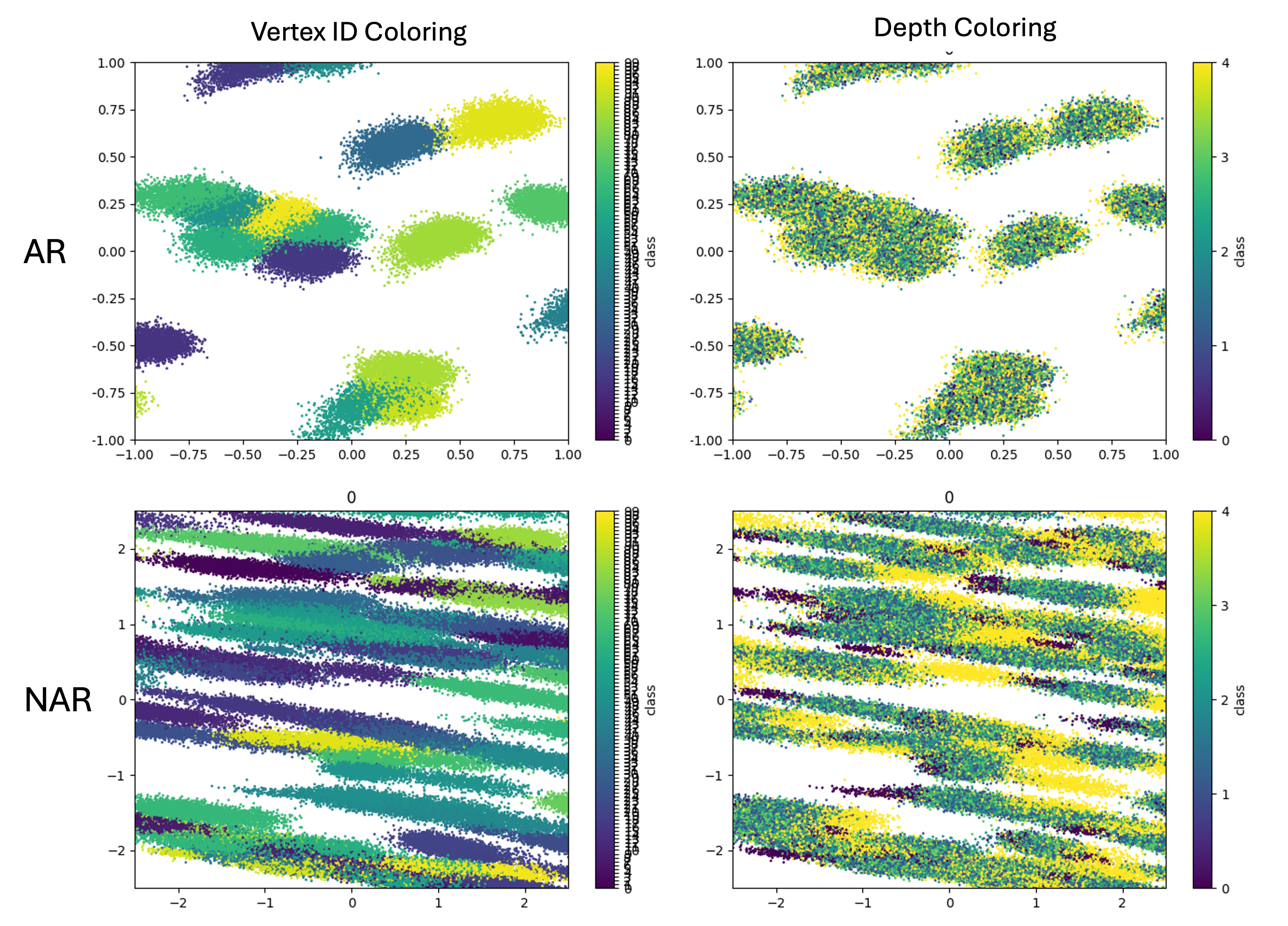
Examination of the Non-Autoregressive (NAR) model’s latent representation demonstrates its capacity to encode information pertaining to future states within the `Star-Path Task`. Specifically, the learned latent vectors contain discernible patterns that correlate with the expected outcome of potential actions, allowing the model to predict the resulting node in the `Star-Graph`. This encoding is not simply a memorization of training examples; analysis confirms the model generalizes to unseen initial states and goal nodes. The ability to effectively represent future states is critical to the model’s planning capabilities, enabling it to efficiently determine optimal paths without requiring extensive search or trial-and-error.
The Echo of Experience: Towards Robust Planning and Beyond
Discrete Diffusion Models exhibit a remarkable capacity for planning, a capability fundamentally rooted in their associative memory. This mechanism allows the model to effectively recall and reuse previously experienced states as building blocks for novel solutions. Rather than approaching each planning problem from scratch, the model leverages its past experiences, identifying and adapting familiar patterns to navigate new challenges. This process mirrors aspects of human cognition, where prior knowledge significantly accelerates problem-solving. By retaining and efficiently accessing a library of successful state transitions, these models demonstrate improved efficiency and robustness in complex planning scenarios, suggesting a pathway toward more adaptable and intelligent artificial systems.
The implementation of Flow Matching techniques represents a substantial refinement to the diffusion process employed in artificial planning systems. This training paradigm moves beyond traditional diffusion models by directly learning a vector field that transports data distributions, resulting in a markedly more efficient and stable learning trajectory. Consequently, the planning performance is significantly improved, as the model requires fewer iterations to converge on optimal solutions and exhibits greater robustness to noisy or incomplete information. By establishing a more direct and reliable pathway through the solution space, Flow Matching not only accelerates the planning process but also enhances the overall quality and consistency of the generated plans, paving the way for more dependable and scalable AI systems.
The demonstrated efficiency of NAR models in achieving exponentially faster convergence during planning tasks suggests a pathway toward tackling significantly more complex artificial intelligence challenges. Future investigations will focus on extending these techniques beyond current limitations, with the aim of applying them to realistic, high-dimensional planning scenarios. This includes areas such as robotic navigation in dynamic environments, intricate game playing, and potentially even long-term strategic decision-making. Successfully translating these advancements to more demanding contexts promises to unlock new frontiers in AI, enabling systems capable of robust and adaptable planning in the face of real-world complexities and uncertainties.
The pursuit of efficient planning, as detailed in the study of Discrete Diffusion Models, often fixates on predicting future states. Yet, this work subtly suggests a different path – not prediction, but a carefully constructed reverse decoding. This echoes Ada Lovelace’s observation: “The Analytical Engine has no pretensions whatever to originate anything.” The engine, like these non-autoregressive models, doesn’t invent the solution; it skillfully navigates a latent space, reconstructing a path from a desired outcome. The focus shifts from generating complexity to exploiting existing structural asymmetry, a principle that aligns with the idea that scalability isn’t about brute force, but elegant simplification. Everything optimized will someday lose flexibility, and this approach demonstrates a path toward resilient, efficient planning.
What’s Next?
The demonstrated efficacy of Discrete Diffusion Models in navigating lookahead planning tasks does not resolve the fundamental tension inherent in all predictive systems. The paper illuminates a pathway – exploiting structural asymmetry – but sidesteps the inevitable question of when, not if, those asymmetries will erode. Architecture is, after all, how one postpones chaos, not defeats it. The observed sample efficiency is a temporary reprieve, a localized reduction in entropy. It is not transcendence.
Future work will undoubtedly probe the limits of this reverse-decoding strategy. The question is not whether more complex lookahead patterns can be discovered within autoregressive models, but whether any model can truly escape the combinatorial explosion that defines complex planning. There are no best practices – only survivors. The challenge lies not in achieving perfect foresight, but in building systems resilient enough to gracefully degrade as prediction inevitably fails.
The exploration of latent space analysis, briefly touched upon, hints at a deeper truth. Order is just cache between two outages. The true frontier is not in refining the algorithms themselves, but in understanding the inherent fragility of all predictive structures and designing systems that can adapt, reconfigure, and even forget in the face of inevitable uncertainty.
Original article: https://arxiv.org/pdf/2602.19980.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- The Best Former NFL Players Turned Actors, Ranked
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- New HELLRAISER Video Game Brings Back Clive Barker and Original Pinhead, Doug Bradley
2026-02-24 21:55