Author: Denis Avetisyan
A new study highlights the importance of strategically designed back markings for reliably identifying individual pigs using computer vision and machine learning.

Careful design of back marks, coupled with data augmentation techniques, is crucial for accurate individual animal identification in precision livestock farming applications using ResNet-50 models.
Individual animal identification remains a challenge, particularly for species with limited natural markings. This is addressed in ‘Insights on back marking for the automated identification of animals’, which investigates the design of artificial back marks to facilitate machine learning-based monitoring. Through training a ResNet-50 neural network to classify pigs bearing unique marks, this study demonstrates that mark design must account for factors like motion blur, viewing angle, and data augmentation strategies to ensure reliable individual recognition. How can these insights be generalized to optimize back mark design for a wider range of species and monitoring applications?
The Illusion of Control: Identifying Individuals in a Chaotic System
Modern livestock operations are fundamentally shifting toward data-driven management, and at the heart of this transformation lies the ability to consistently identify individual animals. This isn’t merely a matter of record-keeping; precise identification unlocks the potential for continuous health monitoring, allowing for early detection of disease and optimized preventative care. Furthermore, tracking individual performance – growth rates, reproductive success, and feed efficiency – enables farmers to make informed decisions about breeding programs and resource allocation. Ultimately, the capacity to differentiate between animals, and access their unique data profiles, is becoming essential for maximizing productivity, improving animal welfare, and ensuring the sustainability of livestock farming systems.
Historically, monitoring livestock health and productivity has depended on farmers manually tracking individual animals – a process demanding significant labor and susceptible to human error in recording data or even correctly identifying each animal. This reliance on visual observation and handwritten records becomes increasingly impractical as herd sizes grow and management complexities increase. Consequently, the field of Precision Livestock Farming actively pursues automated identification systems, leveraging technologies like computer vision and machine learning to accurately and efficiently monitor individual animals without constant human intervention. These systems promise not only to reduce labor costs and minimize errors but also to provide a wealth of data for optimizing animal welfare and production efficiency, moving beyond broad herd-level management to individualized care.
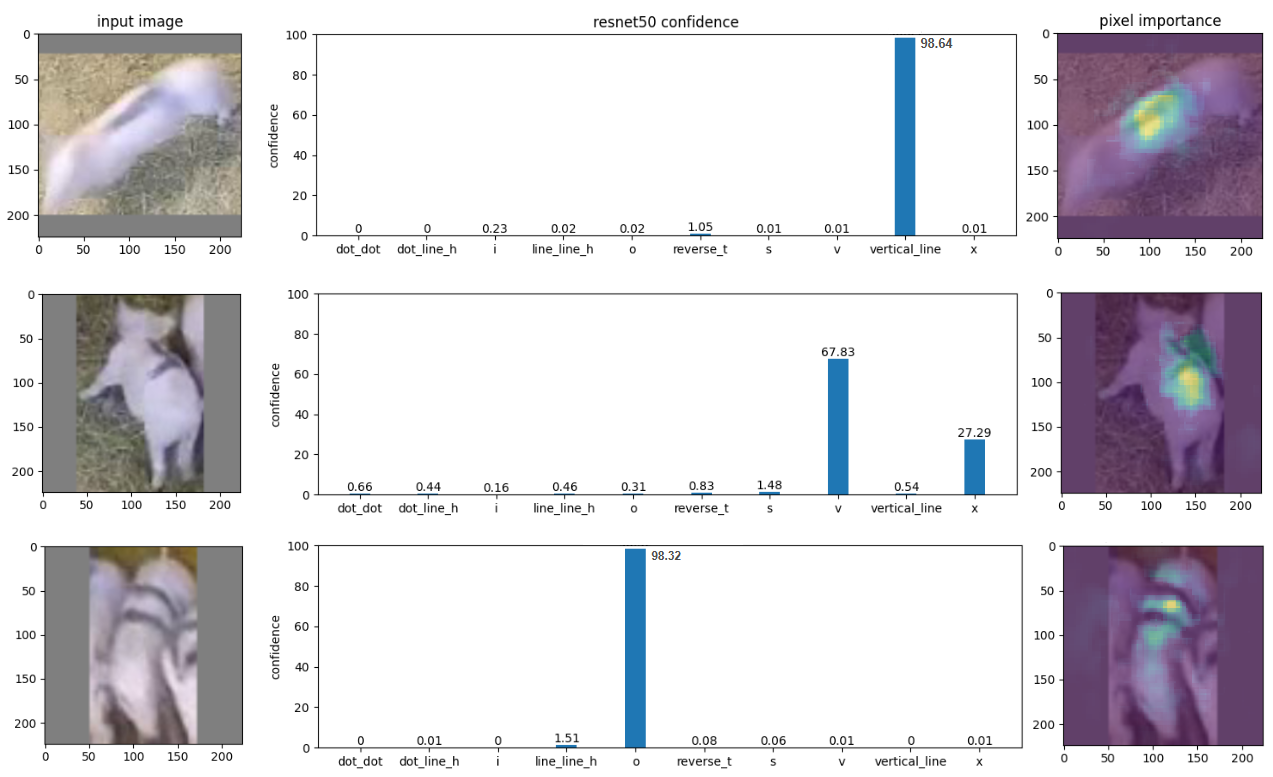
The reliable tracking of individual livestock hinges significantly on visual identification methods, notably the analysis of unique ‘Back Marks’ – naturally occurring patterns on an animal’s hide. However, consistently recognizing these markings presents considerable difficulties. Animal movement introduces motion blur and varying perspectives, while changes in lighting, coat condition due to seasonal shedding or mud, and even the angle of observation can dramatically alter the appearance of these visual cues. Consequently, automated systems designed to interpret Back Marks require robust algorithms capable of compensating for these dynamic conditions, demanding high-resolution imaging, sophisticated image processing, and potentially, multi-spectral analysis to ensure accurate and continuous individual identification within a Precision Livestock Farming context.

Automated Sorting: A Band-Aid on a Broken System
Automated back mark identification utilizes computer vision techniques to analyze images of components and identify markings without manual inspection. This process involves training a machine learning model to recognize specific patterns and characteristics within the images that correspond to different back marks. By converting visual data into a quantifiable format, the system can classify components based on their markings, offering a scalable and objective alternative to human-based quality control. The technology facilitates high-throughput inspection and reduces the potential for subjective errors inherent in manual processes, improving overall efficiency and reliability.
The ResNet-50 architecture was chosen as the foundation for the automated identification system due to its established efficacy in image classification. This convolutional neural network, featuring 50 layers, is pre-trained on the ImageNet dataset, providing a strong starting point for transfer learning. Its depth allows for the learning of complex features, while residual connections mitigate the vanishing gradient problem common in deep networks. Prior research and benchmarks consistently demonstrate ResNet-50’s ability to generalize well across diverse image datasets, making it a suitable choice for this application despite the specific challenges of back mark identification.
The PyTorch deep learning framework was selected as the foundation for implementing the ResNet-50 model due to its flexibility and comprehensive tooling. PyTorch provides both dynamic computational graphs, facilitating rapid prototyping and debugging, and robust support for GPU acceleration, critical for the computational demands of training a convolutional neural network. Specifically, PyTorch’s torchvision package offered pre-built datasets and model architectures, streamlining the development process. Furthermore, the framework’s deployment capabilities, including tools for model serialization and integration with various hardware platforms, were essential for transitioning the trained model from the research environment to a functional identification system.
Initial evaluation of the back mark identification system, using a validation dataset, yielded 91% classification accuracy. This result indicated promising potential for automated identification. However, subsequent testing with a separate, unseen test dataset revealed a significant performance decrease to 69%. This disparity between validation and test set performance suggests overfitting of the model to the validation data, or a lack of generalization to real-world image variations not adequately represented in the training and validation sets. Further investigation and model refinement are required to improve performance on unseen data and ensure reliable operation in a production environment.
Artificial Expansion: Fooling the System with Mirrors and Color Shifts
Data augmentation was implemented to address limitations in the quantity of available training data. This process artificially expands the dataset by creating modified versions of existing images, thereby increasing both the size and variability of the training set. Techniques used generate new samples without requiring additional data collection, improving the model’s ability to generalize and reducing the risk of overfitting. The resulting expanded dataset provides a more robust foundation for training, leading to improved performance on unseen data.
Data augmentation employed three primary methods to generate variations of the original images. Flip augmentation created mirrored versions of images along a designated axis, effectively doubling the dataset with horizontally or vertically flipped instances. Crop augmentation randomly selected sub-regions of the images, simulating variations in object positioning and scale. Colour augmentation adjusted the colour properties of images through alterations in brightness, contrast, saturation, and hue, introducing variations in lighting conditions and object appearance. These transformations collectively increased the diversity of the training data without requiring the acquisition of new images.
Data augmentation techniques enhance a model’s generalization capability by exposing it to a wider range of variations within the training data. This is achieved by creating modified versions of existing images-such as flipped, cropped, or colour-altered instances-effectively increasing the dataset’s size and diversity. By training on this augmented data, the model learns to identify relevant features regardless of minor alterations in perspective, composition, or appearance. Consequently, the model demonstrates improved performance on unseen images captured under varying real-world conditions, including differing lighting, angles, and partial occlusions, thereby increasing its robustness and reducing the risk of overfitting to the original, limited dataset.
The initial dataset used for training the object detection model was sourced from video footage captured by a HIKVISION DS 2CD5046G0-AP IP camera. This camera, known for its 4MP resolution and infrared capabilities, provided the raw visual data. The footage was selected due to its consistent image quality and representative scenes of the target environment. All subsequent data augmentation processes were applied to this original footage, effectively scaling the dataset while preserving the characteristics of the imagery captured by the HIKVISION camera.
The Inevitable Breakdown: Reality Bites Back
The identification of back markings proved particularly challenging for the model due to common real-world conditions encountered in agricultural settings. Instances of motion blur, caused by animal movement during image capture, significantly degraded the clarity of these patterns, hindering accurate classification. Similarly, partial or complete occlusion – where markings were hidden by other animals, vegetation, or even shadows – presented a substantial obstacle. Beyond these image-based distortions, variations in animal pose – the angle and orientation of the animal within the frame – introduced further complexity, as the appearance of markings shifted with changes in body position. These combined factors demonstrate a critical limitation in the model’s ability to generalize from training data to the dynamic and often imperfect conditions of a live farm environment.
Analysis of the identification patterns revealed a significant disparity in classification accuracy. While the ‘Vertical Line’ pattern demonstrated a robust 88% success rate in correctly identifying marks, the ‘Reverse T’ pattern struggled, achieving only 38% accuracy on the test set. This considerable difference suggests that the model is particularly sensitive to the orientation and configuration of markings; the ‘Reverse T’ shape, potentially more susceptible to distortions from animal movement or perspective, presented a greater challenge for accurate recognition compared to the simpler, more consistently detectable ‘Vertical Line’ pattern. These findings underscore the importance of considering feature robustness when designing identification systems for dynamic environments.
The limitations observed in classifying animal poses underscore a critical need for computer vision algorithms designed to withstand the complexities of real-world agricultural environments. Current systems often falter when confronted with common distortions like motion blur or partial occlusions – an animal hidden behind foliage, for instance. Furthermore, the inherent variability in animal behavior-a cow turning its head, or a pig shifting its weight-introduces significant pose variation that challenges existing models. Developing algorithms capable of maintaining accuracy despite these factors isn’t merely about improving classification rates; it’s about creating tools that are genuinely useful for practical applications such as livestock monitoring and automated welfare assessment, demanding a new level of robustness and adaptability in computer vision systems.
Despite employing data augmentation techniques designed to enhance robustness, the model’s performance underscores a significant limitation in current computer vision systems when applied to the complexities of agricultural environments. The persistent difficulty in accurately identifying livestock markings – even after artificially expanding the training dataset with variations in pose, lighting, and partial obstructions – demonstrates that existing algorithms struggle to generalize beyond controlled conditions. This gap isn’t merely a matter of achieving higher accuracy percentages; it represents a fundamental challenge in bridging the divide between laboratory-perfect image recognition and the messy, unpredictable reality of farms, where animal movement, varying viewpoints, and environmental factors introduce substantial visual noise and ambiguity. Addressing this requires innovative approaches that move beyond simple data scaling and embrace methods capable of truly understanding and adapting to real-world image distortions.
“`html
The pursuit of automated animal identification, as demonstrated by this study on back marks for pigs, feels predictably optimistic. It’s another layer of abstraction built on top of inherently messy biological systems. The researchers meticulously crafted these back marks, aiming for robustness against variations in pose and lighting – a noble effort, certainly. But one must remember, even the most elegant ResNet-50 model will eventually encounter a pig that simply refuses to cooperate with the algorithm. As Fei-Fei Li once said, “AI is not about replacing humans; it’s about augmenting human capabilities.” This augmentation is often temporary. The system functions, then production finds the edge cases, and the cycle begins anew. The problem isn’t identifying the animal; it’s believing the identification will always work.
The Devil in the Details
The enthusiasm for automated animal identification via computer vision is… predictable. Every farm wants its ‘digital twin’, and every technologist believes a sufficiently complex algorithm can solve any problem. This work on back marks, however, subtly points out a truth often overlooked: the real world is stubbornly analog. A carefully designed mark, accounting for the animal’s natural movement and the distortions introduced by data augmentation, isn’t a triumph of artificial intelligence, it’s a brute-force accommodation of physical reality. One suspects that as the scale increases – and it always does – these ‘solved’ problems will re-emerge, manifesting as edge cases and inconsistent reads.
The reliance on ResNet-50, while sensible as a starting point, feels less like a breakthrough and more like a postponement. The inevitable quest for ‘scalability’ will push towards ever-smaller models, ever-larger datasets, and, inevitably, a degradation of accuracy. The question isn’t whether the system can identify an animal, but how many misidentifications are acceptable before the cost of correction outweighs the benefits of automation.
Perhaps the most valuable takeaway is the implicit acknowledgement that identification isn’t solely a visual problem. It’s a behavioral one. Animals don’t cooperate with algorithms. They turn, they occlude each other, they simply refuse to be conveniently framed. Better one robust mark, consistently applied and reliably read, than a hundred elegant but brittle systems chasing a phantom of perfect data.
Original article: https://arxiv.org/pdf/2603.25535.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
2026-03-28 00:20