Author: Denis Avetisyan
Researchers have developed a new reinforcement learning algorithm that achieves strong performance in board games with significantly reduced computational demands.
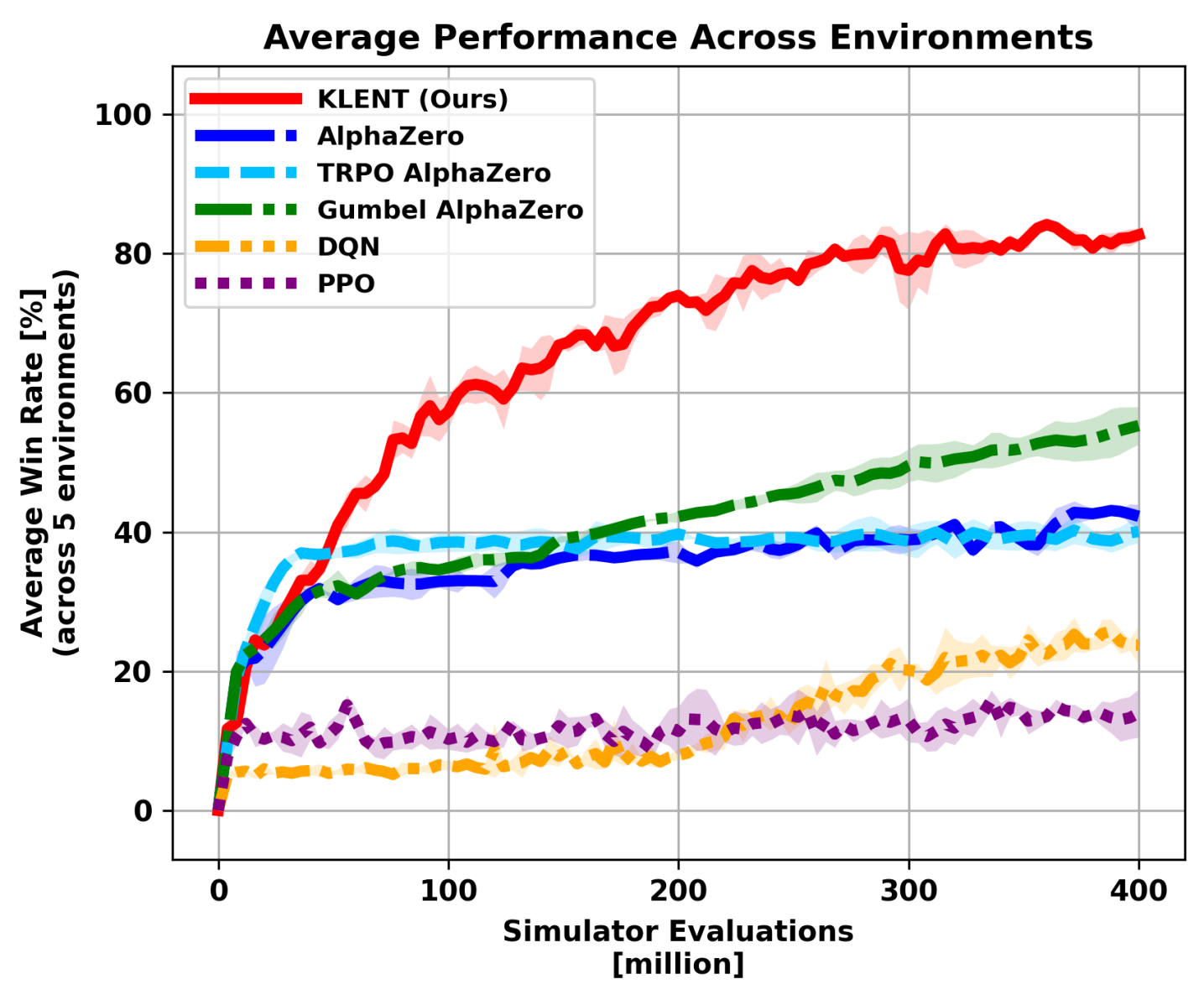
KLENT, a model-free algorithm combining KL and entropy regularization with lambda-returns, demonstrates competitive or superior performance to existing search-based methods.
Despite the successes of search-based methods in complex board game domains, their substantial computational requirements hinder wider accessibility and reproducibility. This limitation motivates the research presented in ‘Resource-Efficient Model-Free Reinforcement Learning for Board Games’, which introduces KLENT, a novel model-free reinforcement learning algorithm leveraging KL and entropy regularization with lambda-returns to achieve efficient learning. Through experiments across five games-Animal Shogi, Gardner Chess, Go, Hex, and Othello-KLENT demonstrates competitive or superior performance to existing approaches while significantly reducing computational cost. Could this work pave the way for model-free reinforcement learning to challenge search-based dominance in complex strategic environments?
Deconstructing Complexity: The Limits of Traditional AI
Traditional reinforcement learning algorithms often falter when confronted with the sheer complexity of modern games and real-world scenarios. These methods typically rely on evaluating every possible state within an environment to determine optimal actions, a process that quickly becomes computationally intractable as the number of states – and therefore potential game configurations – explodes. This phenomenon, known as the “curse of dimensionality,” means that even moderately complex games present state spaces far too vast for exhaustive exploration, severely limiting the applicability of standard reinforcement learning techniques. Consequently, agents struggle to generalize learned behaviors to unseen situations, hindering their ability to achieve robust performance in dynamic and unpredictable environments, and necessitating the development of more sophisticated approaches to manage this complexity.
The ability to effectively chart a course through complex environments presents a formidable obstacle for current artificial intelligence algorithms. These systems often falter when confronted with expansive state spaces, struggling to discern optimal actions from a multitude of possibilities. Strategic planning, the capacity to anticipate future consequences and formulate long-term goals, remains a key hurdle; existing algorithms frequently prioritize immediate gains over sustained success. Efficient exploration, the art of discovering beneficial strategies without exhaustive trial-and-error, further compounds the difficulty. Many current approaches lack the sophistication to intelligently balance the need to gather information with the desire to capitalize on known rewards, resulting in suboptimal performance and a persistent gap between artificial and human-level decision-making capabilities.
A fundamental difficulty in artificial intelligence lies in an agent’s ability to decide between leveraging known beneficial actions – exploitation – and investigating potentially superior, yet unknown, options – exploration. This challenge is particularly acute in complex environments where the consequences of an action are not immediately apparent, resulting in delayed rewards. An agent consistently exploiting current knowledge risks becoming trapped in suboptimal strategies, failing to discover more effective approaches. Conversely, perpetual exploration without capitalizing on existing knowledge hinders progress. Effective algorithms must therefore dynamically calibrate this balance, prioritizing exploration when uncertainty is high and shifting towards exploitation as reliable strategies emerge, a process demanding sophisticated methods for estimating long-term value and managing inherent risk.
AlphaZero: A Systematic Approach to Mastery
Monte Carlo Tree Search (MCTS) in AlphaZero functions by constructing a game tree through repeated simulations. Each simulation involves four stages: selection, where the algorithm traverses the tree, prioritizing nodes with high value and low uncertainty; expansion, where a new node is added to the tree representing a possible game state; simulation, where the game is played out randomly from the new node until a terminal state is reached; and backpropagation, where the result of the simulation is used to update the values of nodes along the path taken during selection. This process is not a uniform exploration; AlphaZero’s implementation biases the search toward more promising lines of play based on evaluations from a deep neural network, allowing it to efficiently explore the vast game tree and concentrate computational resources on the most relevant positions.
AlphaZero’s search process is informed by a deep neural network that outputs two key components: a value representing the estimated probability of winning from a given game state, and a policy defining the probability distribution over all legal moves from that state. The network is structured to accept a game state as input and produce a single scalar value – ranging from -1 to 1 – indicating the predicted outcome, alongside a vector of move probabilities. This dual output allows the Monte Carlo Tree Search (MCTS) to prioritize exploration of promising game states with high predicted values and to select moves with a higher probability of leading to a favorable outcome, effectively guiding the search towards strategically advantageous lines of play.
AlphaZero’s ability to surpass human-level performance in complex games stems from its reinforcement learning methodology, specifically learning through self-play. The system begins with random play and iteratively improves its game strategy by playing millions of games against itself. This process generates a dataset of game positions and outcomes, which are then used to train the deep neural network guiding its Monte Carlo Tree Search. Crucially, this training requires no pre-existing human game data or expert knowledge; the algorithm discovers optimal strategies entirely through experience. This approach enabled AlphaZero to achieve superhuman performance in Chess, Go, and Shogi, demonstrating a generalized learning capability applicable to a range of strategic domains.
TRPO AlphaZero and Gumbel AlphaZero represent advancements over the initial AlphaZero algorithm by focusing on enhancements to the training process and search methodology. TRPO AlphaZero utilizes Trust Region Policy Optimization, a policy gradient method that ensures stable policy updates during reinforcement learning, leading to more consistent improvement. Gumbel AlphaZero introduces the Gumbel-Softmax trick to enable differentiable sampling during the Monte Carlo Tree Search, allowing for end-to-end gradient-based optimization of the search process. Both variants aim to improve training stability, increase search efficiency, and ultimately achieve higher performance levels compared to the original AlphaZero implementation, particularly in complex game scenarios.
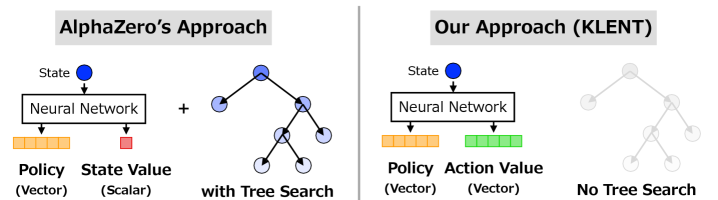
KLENT: Sculpting Stability Through Regulation
KLENT represents a new reinforcement learning framework integrating policy optimization with three regularization techniques: Kullback-Leibler (KL) regularization, entropy regularization, and the utilization of λ-returns. KL regularization constrains policy updates to remain within a defined proximity to the previous policy, preventing abrupt changes that can disrupt the learning process. Simultaneously, entropy regularization promotes exploration by incentivizing the agent to maintain a diverse policy, aiding in the discovery of potentially optimal strategies. Finally, λ-returns combine the advantages of both n-step and Monte Carlo returns, providing a more accurate and stable estimate of the value function by balancing bias and variance in temporal difference learning.
KL regularization, a core component of the KLENT framework, functions by adding a penalty term to the policy update step that is proportional to the Kullback-Leibler divergence between the new and old policies. This penalty discourages large deviations from the previous policy, effectively constraining the magnitude of each update. By limiting these changes, KL regularization mitigates the risk of catastrophic policy shifts which can lead to instability during reinforcement learning, particularly in complex environments. The strength of this regularization is controlled by a hyperparameter, allowing for a tunable balance between exploration and exploitation, and ultimately contributing to more stable and reliable learning.
Entropy regularization, a component of the KLENT framework, directly addresses the exploration-exploitation dilemma in reinforcement learning. By adding a penalty proportional to the entropy of the policy distribution, the agent is incentivized to maintain a degree of randomness in its actions, even when a seemingly optimal action is identified. This encourages continued exploration of the state space, preventing premature convergence to suboptimal policies, particularly in environments with sparse or delayed rewards. The magnitude of the entropy penalty is a tunable hyperparameter, allowing for control over the level of exploration; higher values promote greater randomness, while lower values favor exploitation of known rewards. This mechanism is critical for discovering optimal strategies in complex environments where exhaustive search is impractical.
λ-returns represent a temporal difference (TD) learning method that blends the characteristics of n-step returns and Monte Carlo returns through a weighting parameter, λ. A standard n-step return estimates the value function based on a fixed number of steps, providing bias but low variance. Monte Carlo returns, conversely, use the entire episode to calculate the return, offering unbiased estimates but with high variance. λ-returns create a weighted average of these two approaches; when λ approaches 1, the method behaves similarly to Monte Carlo learning, and when λ approaches 0, it approximates one-step TD learning. By adjusting λ between 0 and 1, the algorithm can balance bias and variance, resulting in more accurate and stable value function estimations, particularly in environments with long-term dependencies or delayed rewards.
KLENT demonstrated substantial gains in learning efficiency when tested across five distinct board game environments: Animal Shogi, Gardner Chess, Go, Hex, and Othello. Specifically, KLENT achieved a four-fold improvement in efficiency compared to the Gumbel AlphaZero algorithm, completing training with 300 million simulator evaluations versus the 75 million required by Gumbel AlphaZero. Furthermore, KLENT achieved competitive performance in the complex 19×19 Go environment, indicating the algorithm’s scalability and ability to handle high-dimensional action spaces.
Comparative analysis indicates KLENT achieves a 4x improvement in learning efficiency when benchmarked against Gumbel AlphaZero. This efficiency gain is quantified by the number of simulator evaluations required to reach a comparable performance level; KLENT necessitated 300 million evaluations, while Gumbel AlphaZero required 75 million to achieve similar results. This reduction in the number of required simulations represents a substantial decrease in computational resources and training time for achieving proficient performance.
KLENT’s efficacy was assessed through rigorous testing across five distinct board game environments: Animal Shogi, Gardner Chess, Go, Hex, and Othello. Performance validation in these diverse games – which vary in board size, complexity, and branching factor – demonstrates the algorithm’s ability to generalize beyond a single problem domain. Successful implementation across this range of games indicates that KLENT is not overfitted to any particular game’s characteristics and can effectively adapt its learning strategy to new, unseen challenges within the realm of perfect-information games.

Beyond the Game: A Glimpse at the Future of Intelligent Systems
The core tenets underpinning both KLENT and AlphaZero – a synergistic blend of search algorithms with the power of deep learning, an emphasis on stable and consistent learning, and a proactive encouragement of exploration – extend far beyond the realm of game playing. These principles represent a broadly applicable framework for tackling complex decision-making problems across diverse fields. Consider robotics, where a system could learn to navigate unpredictable environments by combining search for optimal paths with deep learning for visual perception and control. Autonomous driving similarly benefits from this combination, enabling vehicles to plan routes and react to unforeseen circumstances. Beyond physical systems, resource management and financial trading can leverage these techniques to optimize strategies and adapt to changing conditions, demonstrating the potential for these algorithms to drive innovation in any domain requiring intelligent adaptation and strategic planning.
The core principles driving advancements in artificial intelligence, such as those demonstrated by KLENT and AlphaZero, extend far beyond game-playing. These algorithms possess the potential to revolutionize fields demanding complex decision-making in dynamic environments. In robotics, they could enable more adaptable and efficient robots capable of navigating unstructured spaces and performing intricate tasks. Autonomous driving systems stand to benefit from enhanced perception and planning capabilities, leading to safer and more reliable self-driving vehicles. Resource management, including energy grids and supply chains, could be optimized through predictive modeling and efficient allocation strategies. Even in the volatile world of financial trading, these algorithms offer the prospect of identifying subtle patterns and executing trades with increased precision, though responsible implementation and risk management remain paramount.
Continued development hinges on expanding the operational scope of these algorithms to tackle increasingly intricate and dynamic environments, a challenge demanding significant advances in computational efficiency. Current systems often require vast datasets for training; therefore, improving sample efficiency – enabling robust performance with limited data – represents a crucial research priority. Beyond simply mastering new scenarios, future work will likely concentrate on transfer learning methodologies, allowing algorithms to leverage knowledge gained from one domain to accelerate learning in another, ultimately paving the way for more adaptable and generalized artificial intelligence capable of tackling unforeseen challenges with minimal retraining.
The convergence of knowledge learned through algorithms like KLENT and AlphaZero with complementary machine learning paradigms promises substantial advancements in artificial intelligence. Integrating these search-based methods with imitation learning – where algorithms learn from expert demonstrations – could accelerate the training process and improve performance in complex tasks. Furthermore, combining these approaches with meta-learning, or ‘learning to learn’, enables algorithms to quickly adapt to new, unseen environments with minimal data. This synergistic potential extends beyond simply improving existing capabilities; it paves the way for systems that not only master specific challenges but also exhibit a more generalized and flexible intelligence, capable of tackling a wider range of problems with greater efficiency and robustness.
The pursuit of efficient learning algorithms, as demonstrated by KLENT, echoes a fundamental principle: true understanding demands rigorous testing. The algorithm’s combination of KL and entropy regularization with lambda-returns isn’t merely about achieving competitive performance; it’s about probing the limits of model-free reinforcement learning itself. As Linus Torvalds once stated, “If you can’t break it, you don’t understand it.” This sentiment perfectly encapsulates the spirit of the research – deliberately challenging existing methods to reveal their weaknesses and, in turn, construct a more robust and resourceful system. The paper’s success isn’t just in what it achieves, but in how it arrives at those results – through a process of iterative refinement and relentless exploration of the problem space.
Beyond the Board: Where Does This Leave Us?
The pursuit of resource-efficient learning, as demonstrated by KLENT, invariably exposes the brittleness of current benchmarks. Board games, while convenient proving grounds, are ultimately curated illusions-sanitized environments lacking the messy, irreducible complexity of reality. The algorithm’s success isn’t merely about mastering a game; it’s about a method for extracting signal from noise, and the true test will lie in applying this to domains where the rules aren’t neatly codified, or worse, aren’t even knowable in advance. One suspects that the algorithm’s reliance on lambda-returns, while effective, represents a comfortable compromise – a way to sidestep the truly difficult problem of credit assignment in genuinely long-horizon tasks.
Future work isn’t about refining KLENT, but about dismantling its assumptions. Can this approach be adapted to continuous action spaces without succumbing to the curse of dimensionality? More provocatively, can the principles of KL and entropy regularization be decoupled from reinforcement learning entirely, providing a more general framework for exploration and knowledge acquisition? The algorithm currently learns a policy; a more radical direction would involve an agent that discovers the very structure of the game-or, failing that, actively rewrites the rules to its advantage.
Ultimately, the most valuable outcome of this line of inquiry may not be better game-playing AI, but a deeper understanding of the fundamental limits of learning itself. The algorithm doesn’t solve the problem of intelligence; it merely shifts the burden of complexity elsewhere. And, as any seasoned engineer knows, that’s often progress enough.
Original article: https://arxiv.org/pdf/2602.10894.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Top 10 Coolest Things About Invincible (Mark Grayson)
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- Celebs Who Narrowly Escaped The 9/11 Attacks
2026-02-12 15:12