Author: Denis Avetisyan
A new active learning framework boosts outlier detection by first mastering the characteristics of normal data.
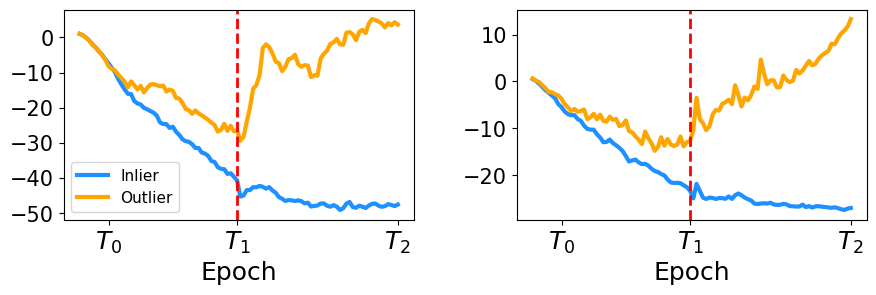
IMBoost leverages inlier memorization within generative deep models to maximize the separation between inlier and outlier scores through adaptive thresholding and a two-phase training process.
Detecting anomalous data instances remains a challenge, particularly in unsupervised settings where labeled outliers are unavailable. This work, ‘Memorize Early, Then Query: Inlier-Memorization-Guided Active Outlier Detection,’ introduces IMBoost, a novel framework that capitalizes on the recently observed inlier-memorization effect within deep generative models. By strategically querying informative labels and reinforcing this memorization, IMBoost maximizes the separation between inlier and outlier scores through a two-phase warm-up and polarization process. Could this approach unlock more efficient and accurate outlier detection with minimal labeling effort, ultimately improving data quality and decision-making?
The Curse of Dimensionality: Why Outliers Thrive
Conventional outlier detection techniques frequently falter when confronted with the intricacies of modern datasets. As dimensionality increases – meaning a greater number of variables are considered – the space in which data resides expands exponentially, creating areas of low density that can be mistaken for genuine anomalies. This phenomenon, often referred to as the “curse of dimensionality,” renders distance-based methods less effective, as distinctions between data points become blurred. Furthermore, many traditional algorithms assume data conforms to specific distributions, such as Gaussian, which rarely holds true in real-world scenarios involving complex interactions and non-linear relationships. Consequently, these methods struggle to accurately differentiate between legitimate variations within the data and truly exceptional, potentially critical, outliers, limiting their utility in fields like fraud detection, intrusion prevention, and medical diagnostics.
Many conventional outlier detection techniques, while theoretically sound, present significant obstacles in real-world implementations due to inherent limitations. Often, these methods operate under strict assumptions about the data’s distribution – for example, assuming a normal distribution or a clearly defined cluster structure – which rarely hold true for complex datasets. When these assumptions are violated, the accuracy of outlier identification diminishes considerably. Furthermore, the computational demands of certain algorithms, particularly those involving distance calculations or density estimations in high-dimensional spaces, can escalate dramatically with increasing data size. This computational expense renders them impractical for large-scale applications, effectively limiting their utility despite potentially high accuracy when applicable. Consequently, researchers are actively seeking more robust and scalable solutions that minimize reliance on strong assumptions and offer improved computational efficiency.
The accurate identification of anomalies hinges on a comprehensive understanding of the inherent structure within data, yet many current techniques falter in this regard. Traditional methods frequently treat data points as independent entities, disregarding the complex relationships and dependencies that define normal behavior in high-dimensional spaces. This simplification overlooks crucial contextual information; an observation flagged as anomalous might, in reality, be a perfectly valid point when considered within its specific data cluster or manifold. Consequently, algorithms struggle to differentiate between genuine outliers – data points truly deviating from the established patterns – and those simply residing in less-populated regions of a naturally complex distribution. Effectively capturing and utilizing this underlying structure – be it through dimensionality reduction, density estimation, or graph-based approaches – remains a significant challenge in the pursuit of robust and reliable outlier detection.
IMBoost: Learning from the Expected, Detecting the Exceptional
The IMBoost framework is predicated on the observation that machine learning models typically acquire representations of prevalent, normal data patterns – the inlier data – before effectively identifying anomalous instances. This “inlier-memorization effect” suggests that initial training phases benefit from focusing solely on establishing a robust understanding of the expected data distribution. By prioritizing the memorization of inlier characteristics, the model develops a stronger baseline for subsequently differentiating outliers, as anomalies represent deviations from these well-established patterns. This approach contrasts with methods that attempt simultaneous learning of both normal and anomalous data, which can hinder the model’s ability to accurately capture the intricacies of the inlier distribution.
IMBoost operates through a sequential two-phase training process. The initial warm-up phase focuses the model on learning the underlying distribution of inlier data, establishing a robust baseline for normal pattern recognition. This is followed by a polarization phase, designed to amplify the differences between inlier representations and those of potential outliers. During polarization, the model is specifically trained to enhance the separation between these two data categories, resulting in improved outlier detection accuracy and a more distinct boundary between normal and anomalous data points.
IMBoost’s core functionality relies on a Deep Generative Model (DGM) to learn the underlying data distribution and quantify the degree to which individual data points deviate from this established norm. The DGM is trained to reconstruct inlier data, and its reconstruction error is used as an outlier score; higher error values indicate greater anomaly. This approach allows IMBoost to achieve state-of-the-art performance in outlier detection by providing a robust and quantifiable metric for assessing data point novelty, surpassing previous methods in benchmark evaluations.
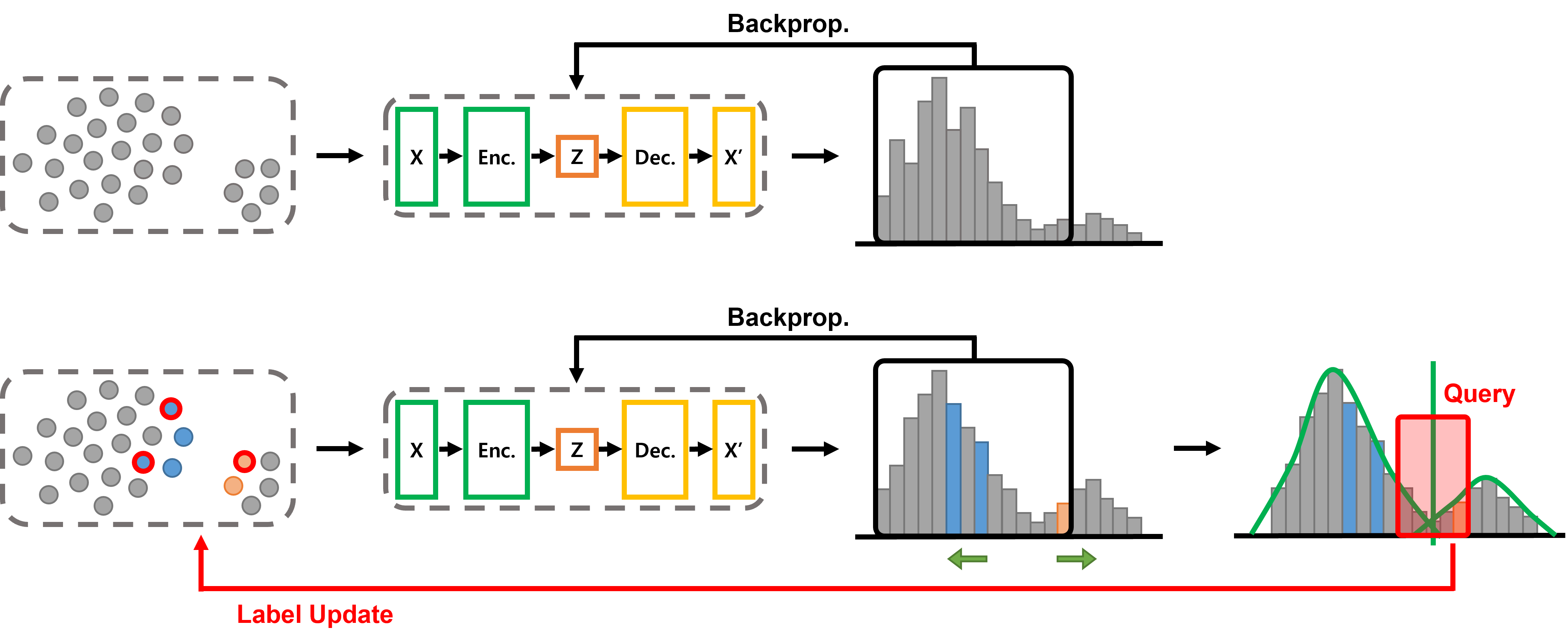
Active Learning: Sharpening the Signal, Reducing the Noise
The polarization phase of IMBoost employs active learning to refine outlier detection by intelligently selecting data points for labeling. Rather than randomly sampling or uniformly processing the dataset, this approach prioritizes instances that maximize information gain regarding the distinction between inliers and outliers. This selective querying process focuses on samples where the model has the lowest confidence or where disagreement between different model components is highest, effectively concentrating labeling efforts on the most informative data points. By strategically querying, the algorithm efficiently improves the separation between inlier and outlier scores, leading to enhanced detection performance with reduced labeling requirements.
The polarization phase employs multiple query strategies to identify the most informative data points for outlier detection. Specifically, Confidence Poles (QueryStrategy_CP) selects samples with the highest uncertainty based on current model predictions. Random Sampling (QueryStrategy_RD) provides a baseline by selecting samples uniformly at random. Mixture Models (QueryStrategy_MM) utilize a probabilistic approach, modeling the data distribution with a Gaussian Mixture Model and prioritizing samples with low likelihoods or high distances from cluster centers. Performance is evaluated across benchmark datasets to determine the optimal query strategy for maximizing the discrepancy between inlier and outlier scores.
IMBoost’s active learning approach demonstrably improves outlier detection accuracy by maximizing the separation between inlier and outlier scores during the polarization phase. Evaluations across benchmark datasets indicate an average performance margin of approximately 5% when compared to the second-best performing baseline. This enhancement is achieved through strategic sample selection, focusing the learning process on data points that contribute most significantly to differentiating between inliers and outliers, effectively amplifying the signal for more robust anomaly identification.

Adaptive Thresholds: Embracing the Dynamic Nature of Anomalies
IMBoost distinguishes between typical data points – inliers – and anomalies – outliers – through a dynamically adjusted threshold, rather than a fixed value. This adaptive approach analyzes the distribution of the data itself to establish what constitutes a normal range; as the data shifts, so too does the threshold for identifying unusual observations. By responding to the inherent characteristics of the dataset, IMBoost avoids the pitfalls of static thresholds which can misclassify normal variations as anomalies or, conversely, fail to detect subtle but significant deviations. This method ensures a more nuanced and accurate identification of outliers, particularly in complex datasets where the distribution is non-normal or changes over time.
The identification of anomalous data points within IMBoost relies on a quantile-based threshold, a statistical approach that defines expected ranges based on data distribution. Rather than a fixed value, this threshold dynamically adapts by dividing the dataset into equal-sized subgroups, each representing a specific quantile – for example, the 95th percentile. Any data point falling beyond a designated upper or lower quantile is flagged as a potential outlier, indicating a deviation from the norm. This method proves remarkably robust because it’s less sensitive to the absolute magnitude of values and more attuned to their relative position within the dataset, effectively mitigating the impact of skewed distributions or varying scales and providing a reliable measure of anomaly.
Evaluations demonstrate that IMBoost attains state-of-the-art performance in anomaly detection, consistently achieving the highest reported Area Under the Curve (AUC) scores. Rigorous testing reveals an approximate 5% performance advantage over the next best performing baseline, signifying a substantial improvement in identifying anomalous data points. Importantly, this superior performance isn’t achieved sporadically; the remarkably small standard deviation accompanying these results confirms the robustness and consistency of IMBoost’s capabilities across diverse datasets and conditions, establishing it as a reliable solution for outlier identification.

The pursuit of definitive boundaries, as illustrated by IMBoost’s focus on maximizing discrepancy between inlier and outlier scores, echoes a timeless human endeavor. It assumes a clear separation, a distinct ‘other’ to define the normal. Yet, as David Hume observed, “A wise man proportions his belief to the evidence.” This framework, while promising in its adaptive thresholding and two-phase polarization, still operates within a constructed reality. The ‘evidence’ – the generative model’s interpretation of data – is itself a product of inherent biases and limitations. Technologies change, dependencies remain; the fundamental challenge isn’t simply detecting outliers, but acknowledging the fragility of any system built on categorization.
The Seed Will Sprout
This work, in its pursuit of defining the boundary between known and unknown, reveals a familiar truth: every definition casts a longer shadow. The ‘inlier memorization’ effect, coaxed and amplified by IMBoost, is not so much a solution as a refinement of the question. The system doesn’t truly detect outliers; it learns, with increasing fidelity, what it already considers ‘normal.’ The warmth of certainty, the polarization of scores – these are merely stages in a growth process, not destinations. One anticipates a future where such frameworks will be judged not by their accuracy on static datasets, but by their resilience to the inevitable drift of the underlying distribution.
The two-phase warm-up and polarization, while effective, feel provisional. It is a scaffolding, erected to guide the system’s initial learning, but destined to be overgrown. The true challenge lies not in optimizing loss functions, but in accepting the inherent impermanence of any ‘normal’ state. Future iterations will likely explore methods for continual adaptation, where the very definition of an inlier evolves in response to the incoming stream of data – a system that doesn’t merely detect anomalies, but anticipates them as the natural consequence of change.
One suspects that the pursuit of ‘active’ outlier detection will ultimately lead to a re-evaluation of the term itself. Perhaps the goal isn’t to actively find the unusual, but to cultivate a system capable of gracefully accommodating it. Every refactor begins as a prayer and ends in repentance; the same, it seems, will be true of every attempt to define the boundaries of the known.
Original article: https://arxiv.org/pdf/2601.10993.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-01-19 18:59