Author: Denis Avetisyan
New research demonstrates how deep neural networks can achieve greater robustness and generalization in image recognition by learning underlying transformations, even with limited data.
Latent equivariant operators offer a promising approach to out-of-distribution generalization for image classification tasks under unseen group transformations.
Despite the successes of deep learning in computer vision, generalizing to novel viewpoints and transformations remains a persistent challenge. This is addressed in ‘Latent Equivariant Operators for Robust Object Recognition: Promise and Challenges’, which explores an architecture learning equivariant operators within a latent space, circumventing the need for pre-defined transformation knowledge. The authors demonstrate successful out-of-distribution classification on rotated and translated MNIST data, achieving robustness to unseen transformations – a feat difficult for both traditional and explicitly equivariant networks. However, scaling these architectures to more complex datasets presents significant hurdles – can these latent operators provide a pathway to truly robust and generalizable computer vision systems?
The Fragility of Perception in Deep Networks
Despite remarkable achievements in tasks like image recognition, deep neural networks frequently exhibit a surprising fragility when faced with inputs that deviate even slightly from their training data. This phenomenon, known as out-of-distribution generalization failure, reveals a core limitation: these networks often learn superficial correlations rather than robust, underlying principles. A system trained to identify cats, for example, might perform poorly if presented with a cat in an unusual pose, under different lighting, or with a minor stylistic alteration – changes a human observer would easily accommodate. This suggests that while deep networks excel at pattern matching, they struggle with genuine understanding, highlighting a critical gap between achieving high accuracy on benchmark datasets and building truly adaptable artificial intelligence.
The apparent fragility of deep neural networks isn’t merely a matter of insufficient training data, but a fundamental limitation in how these systems perceive the world. Current models frequently exhibit surprising vulnerability to even minor alterations in an object’s pose or viewing angle – changes that pose no difficulty for human vision. This sensitivity suggests the networks are not learning abstract, viewpoint-invariant representations of objects, but rather memorizing superficial correlations within the training set. Consequently, when confronted with a slightly unfamiliar perspective, the system fails to generalize, highlighting a crucial distinction between statistical pattern recognition and genuine understanding of underlying concepts. The network doesn’t ‘know’ what a chair is, it simply recognizes a specific arrangement of pixels as a chair, making it easily fooled by subtle shifts in presentation.
Current strategies for improving a deep network’s robustness often rely on data augmentation – artificially expanding the training dataset with modified versions of existing images. While conceptually simple, this approach quickly becomes computationally prohibitive. To truly prepare a network for real-world variability, an exhaustive range of transformations – encompassing alterations in lighting, viewpoint, occlusion, and numerous other factors – must be considered. The sheer number of possible input variations, however, makes complete coverage an impractical, if not impossible, undertaking. Consequently, even extensively augmented datasets often fail to protect against unexpected changes in input distribution, highlighting the limitations of relying solely on brute-force expansion of the training data.
Encoding Invariance Through Geometric Harmony
Group theory, a branch of abstract algebra, formally defines transformations as operations that map a set to itself, maintaining its structure. These transformations – including rotations, translations, and scaling – are characterized by properties like closure (applying a transformation always results in another transformation within the same group), associativity, the existence of an identity element (no transformation), and invertibility. A key concept is invariance; a property or function is invariant under a group of transformations if applying any transformation from that group does not change its value. Mathematically, if g is a transformation in group G and x is an input, invariance requires f(g \cdot x) = f(x), where f is the invariant function. By leveraging group theory, transformations can be systematically described and analyzed, allowing for the development of models that are inherently robust to changes described by the group.
Neural network architectures can be designed to exhibit robustness to changes in input viewpoint and pose by explicitly modeling geometric transformations. This is achieved by incorporating transformation parameters directly into the network, often through techniques like data augmentation with transformed versions of training examples or by building layers equivariant to specific transformations. Equivariance ensures that a transformation applied to the input results in the same transformation applied to the network’s output, preserving feature relationships under these changes. This approach improves generalization performance, particularly in applications like image recognition and 3D object analysis, where variations in viewpoint and pose are common. By learning to recognize patterns independent of these variations, the network becomes less sensitive to irrelevant changes in the input and more focused on the underlying, invariant features.
Understanding the impact of transformations on data is central to achieving encoding invariance. Group transformations, mathematically defined through concepts like groups, subgroups, and representations, provide a formal language for describing these changes in data coordinates. A transformation g acts on a data point x to produce gx , altering its representation. The key is to model how these transformations affect relevant features. This modeling involves representing transformations as elements within a group, enabling the prediction of how a transformed input gx relates to the original input x . Representations, such as matrices or other parameterized functions, allow these transformations to be computationally implemented and integrated into neural network architectures.
Learning Equivariance in Latent Space: A Principle of Refinement
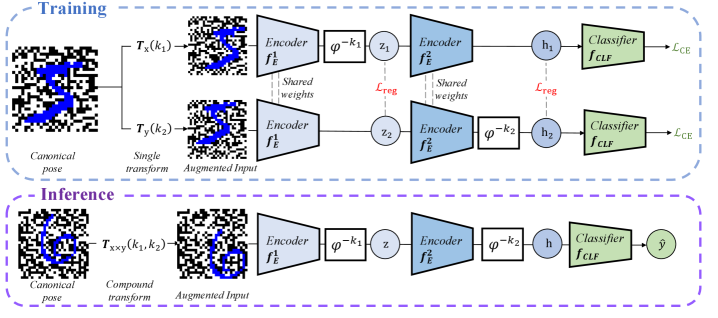
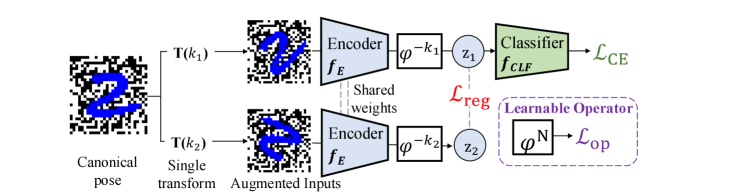
Latent Equivariant Operator Methods address the challenge of incorporating symmetry and transformation understanding into machine learning models by directly learning group transformations from training data. Rather than relying on hand-engineered features or assumptions about data symmetries, these methods learn to represent transformations-such as rotations, translations, or reflections-as operators within a lower-dimensional latent space. This is achieved by mapping input data into a latent representation and then applying learned transformations within that space. The key advantage is the ability to generalize to unseen transformations and viewpoints, as the learned operator effectively captures the underlying geometric principles governing the data. This approach allows models to maintain consistent behavior even when presented with transformed inputs, improving robustness and reducing the need for extensive data augmentation.
The process begins with a linear encoder that transforms high-dimensional input data into a lower-dimensional latent space. This encoding facilitates subsequent operations and reduces computational complexity. Critically, a shift operator is integrated within this latent space to address variations in input pose. The shift operator effectively aligns representations of the same object, despite differing orientations or positions, to a standardized, or canonical, pose. This alignment is achieved by applying a known transformation to the latent representation, ensuring that the system focuses on intrinsic properties rather than extrinsic variations. The use of a linear encoder and shift operator combination establishes a pose-normalized latent space, which is crucial for learning equivariant representations.
The representation consistency loss functions by minimizing the distance between the latent representations of an input and its transformed views. This is achieved by applying various transformations – such as rotations, translations, or scaling – to the input data and then calculating a loss based on the difference between the resulting latent vectors. By enforcing consistency across these transformed views, the model learns to extract features that are invariant to these specific transformations. This process directly improves the robustness of the learned representation to variations in input data and enhances the model’s ability to generalize to unseen data points, effectively preventing the model from treating geometrically similar inputs as distinct.
The framework utilizes a periodic operator to enforce consistent transformation behavior within the latent space by composing multiple transformations with a defined period. This ensures that applying the learned transformation repeatedly, or with variations within its period, results in predictable and stable outputs. Specifically, the operator is designed such that after a fixed number of applications – the period – the representation returns to its initial state, preventing unbounded or erratic changes in the latent representation. This periodicity is crucial for maintaining the integrity of the learned transformations and enhancing the robustness of the overall system, as it constrains the possible outputs and avoids instability in downstream tasks.
Validation and Impact on MNIST: A Robustness Demonstrated
The proposed framework underwent rigorous validation utilizing the widely recognized MNIST dataset of handwritten digits, but not without deliberate enhancements to mimic real-world complexities. Researchers intentionally augmented the standard dataset with a series of geometric transformations, including rotations and translations, to test the model’s robustness beyond simple, aligned inputs. Further increasing the challenge, a checkerboard background was introduced, adding visual clutter and requiring the model to discern digits against a non-uniform backdrop. This carefully constructed augmentation strategy aimed to move beyond idealized conditions and evaluate the framework’s ability to generalize to more realistic, and therefore more difficult, image recognition scenarios.
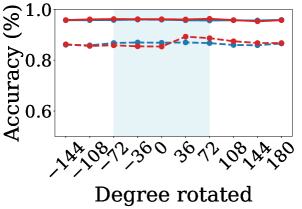
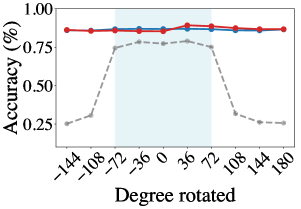
The framework leverages K-Nearest Neighbors (k-NN) within its latent space to effectively infer the pose of transformed digits, showcasing a remarkable capacity to generalize to previously unseen variations. Rather than retraining for each new transformation, the model identifies the closest examples in its latent representation – those with similar features – and uses their known poses to estimate the pose of the input digit. This approach allows for rapid adaptation to novel transformations without requiring extensive computational resources or labeled data. Performance evaluations indicate that, utilizing a reference set of 2000 examples, the k-NN pose inference achieves an accuracy of 70-80%, demonstrating its robustness and practical applicability in handling diverse input conditions.
The model’s training regimen centers on Cross-Entropy Loss, a function carefully chosen to simultaneously maximize classification accuracy and enforce equivariance to applied transformations. This means the model isn’t simply learning to recognize digits, but also to understand how those digits change when rotated, translated, or otherwise manipulated. By minimizing the Cross-Entropy Loss, the network learns a latent space where similar digits, even under different transformations, are clustered closely together. This approach effectively builds robustness into the model, allowing it to generalize effectively to unseen transformations during testing-a crucial step towards real-world applicability where input data is rarely pristine or perfectly aligned.
Evaluations on the MNIST dataset reveal a remarkably stable performance, with the model consistently achieving 95-96% classification accuracy even when presented with digit images subjected to previously unseen transformations. This robustness represents a substantial improvement over standard approaches, indicating an enhanced capacity for generalization. Further analysis utilizing k-Nearest Neighbors for pose inference demonstrated an accuracy range of 70-80%, achieved with a reference set comprising 2000 examples – a testament to the model’s ability to effectively leverage latent space representations for handling novel viewpoints and distortions.
The pursuit of robust object recognition, as detailed in the study, echoes a fundamental principle of elegant design: harmony between form and function. The researchers demonstrate that latent equivariant operators allow networks to generalize beyond their training data, adapting to unseen transformations with a subtle efficiency. This approach isn’t merely about achieving accuracy; it’s about building systems that understand transformations, mirroring how a well-designed structure anticipates and accommodates external forces. As Fei-Fei Li aptly stated, “AI is not about replicating human intelligence, it’s about augmenting it.” This work exemplifies that augmentation, not through brute force, but through a deeper, more principled understanding of the underlying structure of visual data, and a commitment to consistency in the face of the unexpected.
Beyond the Horizon
The demonstration that latent equivariant operators can coax generalization from limited data is not merely a technical advance; it is a subtle redirection. The field has long chased ever-larger datasets, believing volume alone guarantees robustness. This work suggests something different: that intelligent structure-a network designed to understand transformations, not simply memorize examples-can be a powerful corrective. The elegance lies not in the quantity of data, but in the quality of representation.
However, the current formulation remains tethered to relatively simple transformations and datasets. Scaling these methods to the messy, high-dimensional world of truly ambiguous data-where transformations are not cleanly defined, and noise is pervasive-will demand a more nuanced approach. The true test won’t be MNIST with a slight rotation, but a real-world image distorted by atmospheric conditions, partial occlusion, and the inherent imperfections of the sensing apparatus.
The challenge, then, is not simply to impose equivariance, but to discover the relevant transformations. A network that can learn the underlying symmetries of a dataset-that can distill order from chaos-will be a powerful tool indeed. Such a system would not merely recognize objects; it would understand them, and that understanding, unlike brute-force memorization, should scale beautifully.
Original article: https://arxiv.org/pdf/2602.18406.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Trading Crypto with AI: A New Approach to Portfolio Management
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Thinking Before Acting: A Self-Reflective AI for Safer Autonomous Driving
2026-02-24 04:59