Author: Denis Avetisyan
A new approach to feature extraction leverages self-supervised learning to significantly improve object detection performance, even when labeled data is scarce.
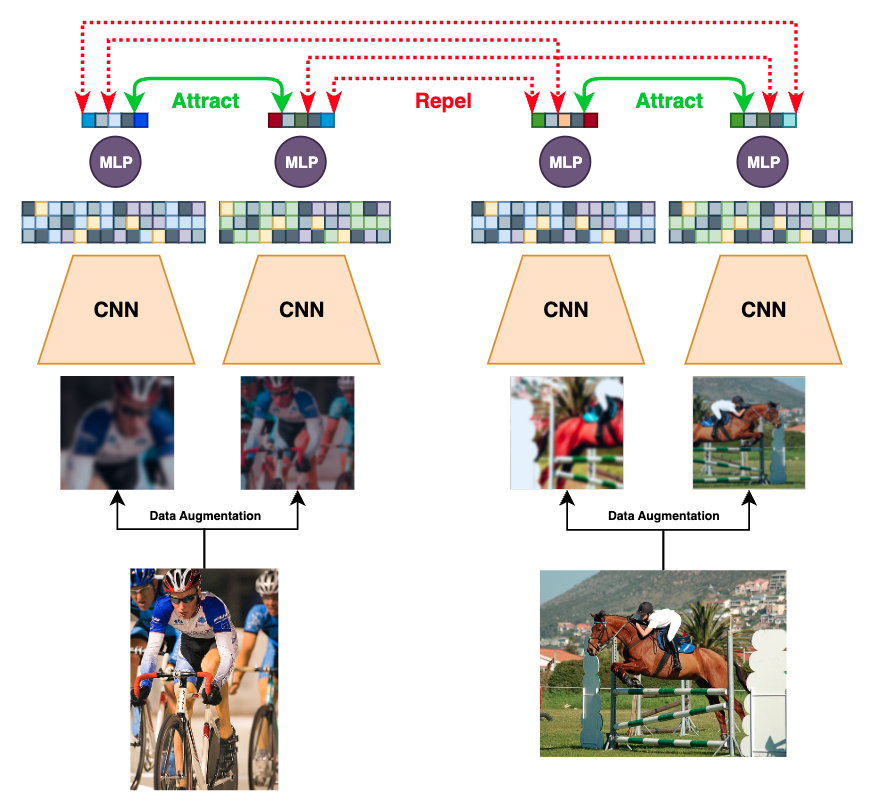
Self-supervised learning enhances feature representations for object detection, achieving improved localization accuracy compared to traditional pre-trained models.
Despite advances in deep learning, object detection models remain heavily reliant on large, labeled datasets – a costly and time-consuming bottleneck for many applications. This research, presented in ‘A Self-Supervised Approach for Enhanced Feature Representations in Object Detection Tasks’, introduces a novel self-supervised learning strategy to alleviate this dependency by improving the quality of learned feature representations. Our approach demonstrates that a feature extractor trained on unlabeled data outperforms state-of-the-art ImageNet pre-trained backbones, particularly in localization accuracy, even with limited labeled data. Could this paradigm shift unlock more robust and data-efficient object detection systems for real-world applications?
The Ascendancy of Visual Perception: Overcoming the Limits of Early Approaches
Computer vision has undergone a revolution in recent years, largely propelled by advancements in deep learning techniques. Historically, enabling machines to ‘see’ and interpret images presented significant challenges, requiring laborious manual feature engineering. Now, deep neural networks, particularly convolutional neural networks, automatically learn hierarchical representations directly from raw pixel data. This has led to breakthroughs in tasks such as image classification, object detection, and image segmentation, surpassing human-level performance on benchmark datasets like ImageNet. The ability of these networks to discern complex patterns and contextual information has unlocked applications ranging from self-driving cars and medical image analysis to facial recognition and augmented reality, demonstrating the transformative power of deep learning in the field of visual perception.
Early computer vision systems heavily relied on meticulously labeled datasets – a substantial limitation that significantly impacted their applicability in real-world scenarios. These traditional methods demanded thousands, even millions, of annotated images for training, a process both time-consuming and expensive. Consequently, performance would drastically decline when faced with new environments or objects lacking sufficient labeled examples – a situation known as the “data scarcity” problem. This dependence on extensive labeled data restricted the deployment of these systems to well-defined tasks and hindered their ability to generalize effectively, presenting a major obstacle to achieving truly adaptable and intelligent vision capabilities.
The pursuit of truly generalizable computer vision systems hinges significantly on advancements in robust feature extraction. While deep learning models excel at pattern recognition within specific datasets, their performance often degrades when confronted with novel viewpoints, lighting conditions, or occlusions – scenarios where reliably identifying key image characteristics becomes paramount. Current methods frequently struggle to discern invariant features – those that remain consistent despite such variations – leading to brittle systems susceptible to even minor perturbations. Consequently, research focuses on developing algorithms capable of automatically learning and representing features that are not only discriminative but also resilient to real-world complexities, potentially through techniques like self-supervised learning or the incorporation of geometric priors. Overcoming this bottleneck is crucial for deploying computer vision beyond controlled environments and realizing its full potential in applications demanding adaptability and reliability.
Self-Supervised Learning: A Necessary Shift in Paradigms
Self-Supervised Learning (SSL) addresses the limitations of supervised learning by enabling models to extract meaningful representations from data without requiring explicit human-provided labels. Traditional machine learning algorithms rely heavily on labeled datasets, which are often expensive and time-consuming to create. SSL circumvents this requirement by formulating pretext tasks that generate labels automatically from the inherent structure of the unlabeled data itself. This allows models to learn useful features and patterns directly from the raw input, such as images, text, or audio, thereby reducing the need for manual annotation and facilitating learning from vastly larger datasets. The learned representations can then be transferred to downstream tasks with minimal fine-tuning, often achieving performance comparable to, or exceeding, supervised approaches.
Contrastive learning is a self-supervised technique that trains models to understand data relationships by evaluating the similarity and dissimilarity between examples. The core principle involves constructing pairs of data points – positives, which are considered similar (e.g., different augmented views of the same image), and negatives, which are considered dissimilar. The model learns to embed positive pairs closer together in a representation space while pushing negative pairs further apart. This is typically achieved through a loss function that penalizes small distances between negative pairs and large distances between positive pairs. The resulting learned representations capture essential data characteristics without requiring explicit labels, enabling the model to generalize effectively to downstream tasks.
SimCLR, a self-supervised learning method, employs contrastive learning to generate effective data representations. This is achieved by training a model to recognize similar instances as close in representation space, while pushing dissimilar instances further apart. A key component is the InfoNCE loss function, which formulates this objective as a classification problem: distinguishing the positive pair (a given example and a transformed version of itself) from a set of negative examples. The InfoNCE loss L = -log(\frac{exp(sim(z_i, z_j)/\tau)}{ \sum_{k=1}^N exp(sim(z_i, z_k)/\tau)}) maximizes the similarity between positive pairs (zi, zj) and minimizes similarity with negative samples, where τ is a temperature parameter and sim denotes a similarity function, typically dot product. By maximizing this contrastive objective, SimCLR learns robust and discriminative representations from unlabeled data.
Integrating EfficientNet architectures with the SimCLR framework demonstrably enhances both performance and computational efficiency. Studies indicate that replacing the standard ResNet backbone in SimCLR with EfficientNet variants – particularly larger models like EfficientNet-B6 and B7 – results in improved linear evaluation accuracy on ImageNet. This performance gain stems from EfficientNet’s compound scaling method, which uniformly scales all dimensions of depth/width/resolution using a simple yet effective compounding coefficient. Furthermore, EfficientNet’s optimized network structure and parameter count contribute to a reduction in training time and memory footprint compared to models utilizing larger, more complex backbones, without significant detriment to representation quality as measured by downstream task performance.
Evaluating Generalization on Object Detection Challenges
Object detection, a fundamental task within computer vision, aims to identify and localize objects of interest within images or videos. Recent advancements demonstrate that utilizing features learned through self-supervised learning (SSL) substantially improves performance on this task. Unlike traditional supervised learning which requires extensive labeled datasets, SSL allows models to learn meaningful representations from unlabeled data by solving pretext tasks. These learned representations, when transferred to object detection models, provide a more robust feature extraction capability, leading to increased accuracy and efficiency, particularly when labeled data is scarce. The benefits stem from SSL’s ability to capture inherent data structure and relationships, resulting in features that generalize better to downstream tasks like object detection.
Object detection performance is quantitatively assessed using metrics that evaluate the overlap between predicted bounding boxes and ground truth annotations. Mean Intersection over Union (Mean IoU) calculates the average IoU for each detected object, representing the area of overlap divided by the area of union between the prediction and the ground truth. Localization Accuracy, typically reported at specific IoU thresholds (e.g., IoU 0.5 and IoU 0.7), measures the percentage of detected objects where the predicted bounding box IoU exceeds the defined threshold. These metrics provide a standardized method for comparing the performance of different object detection models and algorithms, allowing for objective evaluation of detection quality and precision.
The Pascal VOC dataset, and its associated evaluation protocol, serves as a standard benchmark for object detection algorithms due to its comprehensive annotations and realistic imagery. Comprising approximately 11,531 images with bounding box annotations for 20 object categories, Pascal VOC facilitates quantitative performance assessment. The dataset is divided into training, validation, and test sets, enabling rigorous evaluation of model generalization capability. Performance is typically reported using metrics such as Mean Average Precision (mAP) calculated across varying Intersection over Union (IoU) thresholds, allowing for direct comparison of different approaches and tracking progress in the field. Its continued use ensures reproducible results and provides a common ground for researchers to validate novel object detection techniques in near real-world conditions.
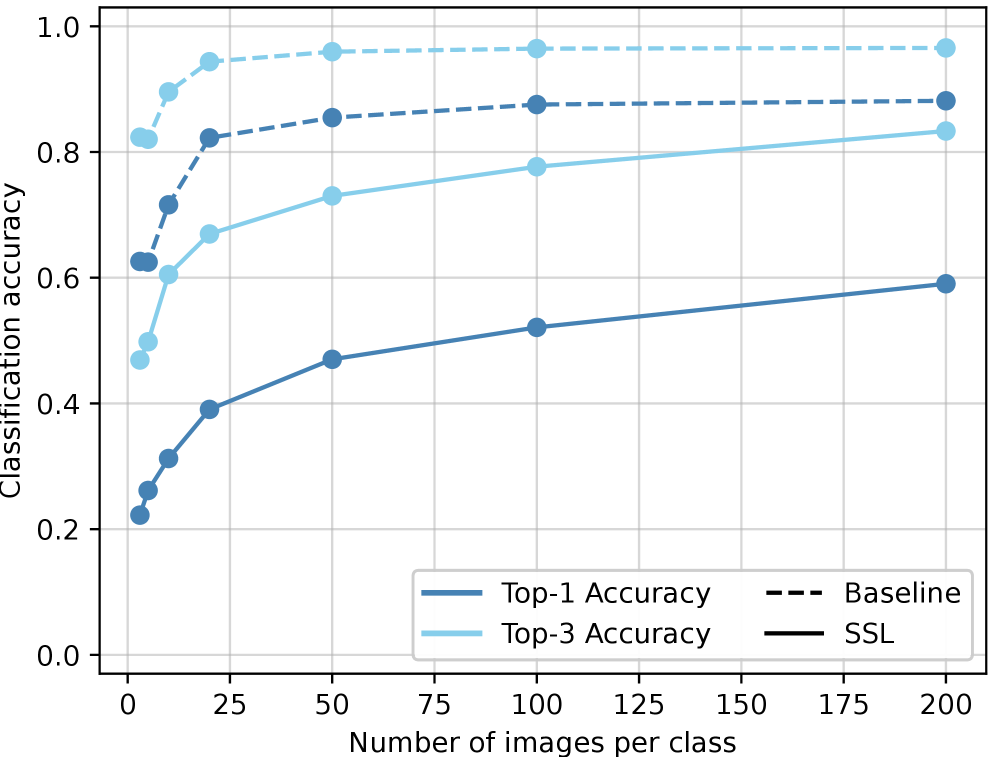
Evaluations demonstrate that the proposed self-supervised learning (SSL) backbone surpasses the performance of an EfficientNetB1 baseline, which was pre-trained on the ImageNet dataset, in object localization tasks. This improvement in accuracy is notable even when training data is limited. Specifically, the SSL backbone achieved a higher Localization Accuracy, as measured by Intersection over Union (IoU), at both the 0.5 and 0.7 thresholds compared to the baseline model. These results indicate that features learned through self-supervision are effectively transferred to improve object detection performance, particularly in data-constrained scenarios.
Transfer learning, leveraging features obtained through self-supervision, demonstrably improves object detection performance when labeled data is scarce. This approach allows models to capitalize on patterns and representations learned from unlabeled datasets, effectively pre-training the network to extract relevant features. Consequently, the model requires fewer labeled examples to achieve comparable or superior performance to those trained from scratch or with traditional supervised pre-training on datasets like ImageNet. The self-supervised features provide a robust initialization, mitigating the need for extensive labeled data and accelerating convergence during fine-tuning for specific object detection tasks.

Decoding the Reasoning: Visualizing Model Decisions
The ability to discern why a computer vision model arrives at a specific prediction is fundamentally important for both refining its accuracy and ensuring its dependability. Without understanding the features-the specific patterns or characteristics within an image-that most influence a model’s decision, identifying and correcting errors becomes significantly more challenging. A model might, for instance, consistently misclassify images due to an unintended focus on background noise rather than the primary object. By investigating these driving features, developers can pinpoint such issues, implement targeted improvements to the training data or model architecture, and ultimately build systems that are not only more accurate but also more robust to variations and unforeseen circumstances. This process of feature-level analysis moves beyond simply assessing what a model predicts to understanding how it arrives at that prediction, which is crucial for deploying reliable computer vision applications.
Gradient-weighted Class Activation Mapping, or Grad-CAM, provides a powerful technique for understanding why a convolutional neural network makes a specific prediction. Rather than simply outputting a classification, Grad-CAM visually highlights the image regions that most influenced the model’s decision, creating a coarse localization map. This is achieved by using the gradients of any target concept flowing into the final convolutional layer to produce a weighted combination of the feature maps. The resulting heat map effectively pinpoints the areas of the input image that were most salient to the network, allowing researchers and developers to inspect whether the model is focusing on meaningful features – such as an object’s defining characteristics – or spurious correlations within the data. This visual insight is crucial for debugging model behavior and fostering trust in computer vision applications.
The application of visualization techniques, such as Grad-CAM, extends beyond simply understanding what a model sees; it actively facilitates the detection of problematic focusing patterns. A model concentrating on spurious correlations – like a specific watermark consistently present in images of cats, rather than feline features – indicates a potential bias that could lead to inaccurate predictions in real-world scenarios. By highlighting these irrelevant focal points, researchers and developers gain crucial insight into the model’s reasoning, allowing them to address and mitigate such issues through data augmentation, architectural adjustments, or targeted retraining. This proactive identification of weaknesses is fundamental to building computer vision systems that are not only accurate but also demonstrably reliable and free from unintended prejudice.
The pursuit of robust and reliable computer vision systems hinges critically on the ability to understand why a model arrives at a particular decision. Enhanced interpretability isn’t merely about transparency; it’s a foundational step towards building systems that generalize well to unseen data and exhibit predictable behavior. When developers can dissect a model’s reasoning, they are equipped to identify and mitigate vulnerabilities, such as reliance on spurious correlations or biases present in the training data. This deeper understanding facilitates targeted improvements to model architecture, training procedures, and data augmentation strategies, ultimately yielding systems that are less prone to failure in real-world applications and more trustworthy in critical contexts. Consequently, prioritizing interpretability is not simply a matter of good practice, but an essential ingredient for deploying computer vision solutions with confidence and accountability.
The pursuit of robust feature representations, as detailed in the study, aligns directly with the need for deterministic outcomes in machine learning systems. Yann LeCun aptly stated, “If the result can’t be reproduced, it’s unreliable.” This principle underscores the significance of the self-supervised learning approach presented, as it aims to create feature extractors less reliant on extensive labeled datasets – a frequent source of variability and potential unreliability. By focusing on learning from the inherent structure of data itself, the method strives for consistent and reproducible performance, particularly in the critical aspect of object localization, thereby addressing a core challenge in building dependable deep learning pipelines. The work champions a move towards algorithms whose correctness isn’t simply demonstrated through testing, but is fundamentally rooted in mathematical principles.
What Remains to be Proven?
The demonstrated improvement in localization accuracy, achieved through self-supervised pre-training, is not merely an engineering triumph, but a pointed reminder. It highlights the inherent compromises within supervised learning-the reliance on painstakingly curated labels, a process fundamentally divorced from the elegance of mathematical truth. While the results are encouraging, the true test lies in establishing why these self-supervised features generalize better. Correlation is not causation, and a pragmatic boost in performance does not equate to a deeper understanding of representation learning.
Future work must move beyond empirical validation. The field requires a formal characterization of the feature space learned through self-supervision. What geometric or topological properties differentiate these representations from those obtained via traditional pre-training? Is it simply a matter of regularization, or does self-supervision unlock a fundamentally more efficient encoding of visual information? The current approach, while effective, feels suspiciously like applied heuristics-a useful approximation, certainly, but a far cry from a provably optimal solution.
Ultimately, the path forward necessitates a rejection of the ‘good enough’ philosophy. The pursuit of perfect feature extraction-one derived from the intrinsic structure of data, free from the biases of human annotation-remains an elusive, yet essential, goal. Until then, these improvements, however substantial, are merely steps toward a more mathematically grounded understanding of vision.
Original article: https://arxiv.org/pdf/2602.16322.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- The Best Directors of 2025
- Gold Rate Forecast
2026-02-19 13:56