Author: Denis Avetisyan
A new survey traces the evolution of meta-learning and meta-reinforcement learning, revealing the path towards truly adaptable artificial intelligence.
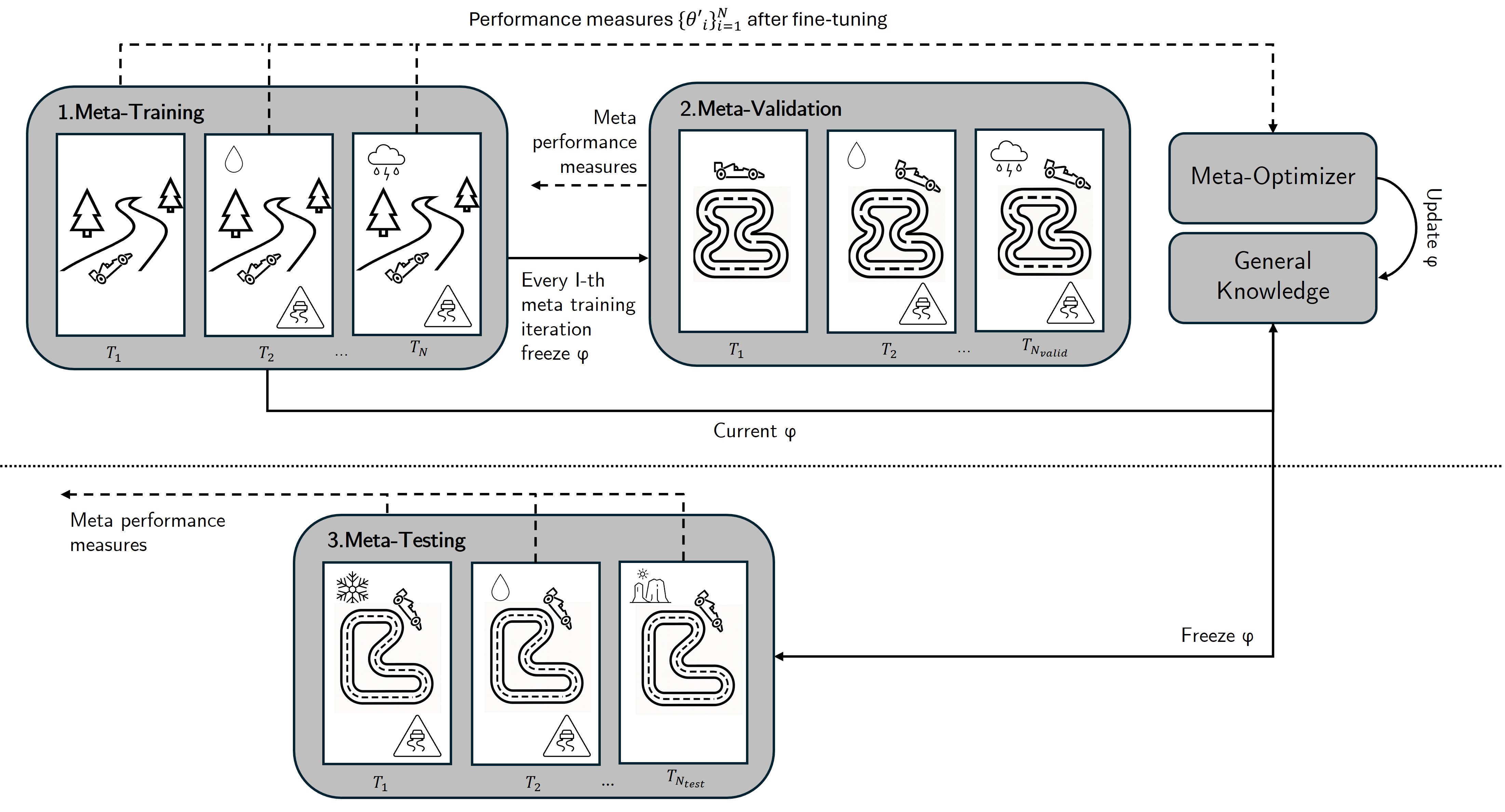
This review explores the development of algorithms enabling agents to quickly learn new tasks, from gradient-based methods to modern transformer architectures for general intelligence.
While standard machine learning excels at specific tasks, replicating human-level adaptability remains a significant challenge. This survey, ‘Meta-Learning and Meta-Reinforcement Learning – Tracing the Path towards DeepMind’s Adaptive Agent’, provides a task-based formalization of meta-learning, charting the evolution of algorithms – from gradient-based methods to modern transformer networks – that underpin increasingly generalist reinforcement learning agents. The analysis consolidates essential concepts, revealing a clear trajectory toward autonomous systems capable of rapid adaptation with minimal data. As these approaches mature, will we see the emergence of truly general intelligence, and what new challenges will arise in building and deploying such adaptable systems?
The Illusion of Control: Learning to Learn
Conventional reinforcement learning methods often falter when confronted with dynamic environments, necessitating complete retraining with each alteration in conditions. This limitation stems from the agent’s reliance on task-specific knowledge – data learned during one scenario proves largely useless when the rules change. Consequently, an agent proficient in navigating one maze, for example, would require substantial re-education to operate effectively in a slightly modified version of the same maze, or a completely new environment. This constant need for re-calibration is not only computationally expensive but also hinders the development of robust, adaptable intelligence, as real-world scenarios rarely remain static; systems capable of learning how to learn, rather than simply learning tasks, are vital to overcome these limitations.
Rather than mastering individual tasks in isolation, meta-learning empowers agents to cultivate a broader skillset – the ability to rapidly acquire new skills. This approach centers on accumulating experience not just with performing tasks, but with the process of learning itself. Through exposure to a distribution of tasks, an agent develops an internal model of how to efficiently adapt, essentially learning which learning strategies are most effective in different scenarios. Consequently, when presented with an unfamiliar task, the agent doesn’t start from scratch; it leverages its prior experience to quickly identify relevant patterns and generalize its knowledge, dramatically reducing the time and data required for proficient performance. This capacity for swift adaptation represents a significant step towards creating artificial intelligence that can thrive in dynamic, real-world environments.
The pursuit of genuinely intelligent systems necessitates a departure from traditional task-specific learning approaches. Current artificial intelligence often excels at narrowly defined problems, but falters when confronted with even slight variations or entirely new challenges. A crucial advancement lies in equipping systems with the ability to learn how to learn – to internalize adaptable strategies rather than memorizing solutions for fixed scenarios. This meta-learning paradigm allows an agent to quickly assimilate new information and generalize across tasks, mirroring the cognitive flexibility observed in biological intelligence. By focusing on the underlying principles of adaptation, rather than rote memorization, researchers aim to create systems capable of continuous improvement and robust performance in dynamic, unpredictable environments, ultimately paving the way for more versatile and truly intelligent machines.
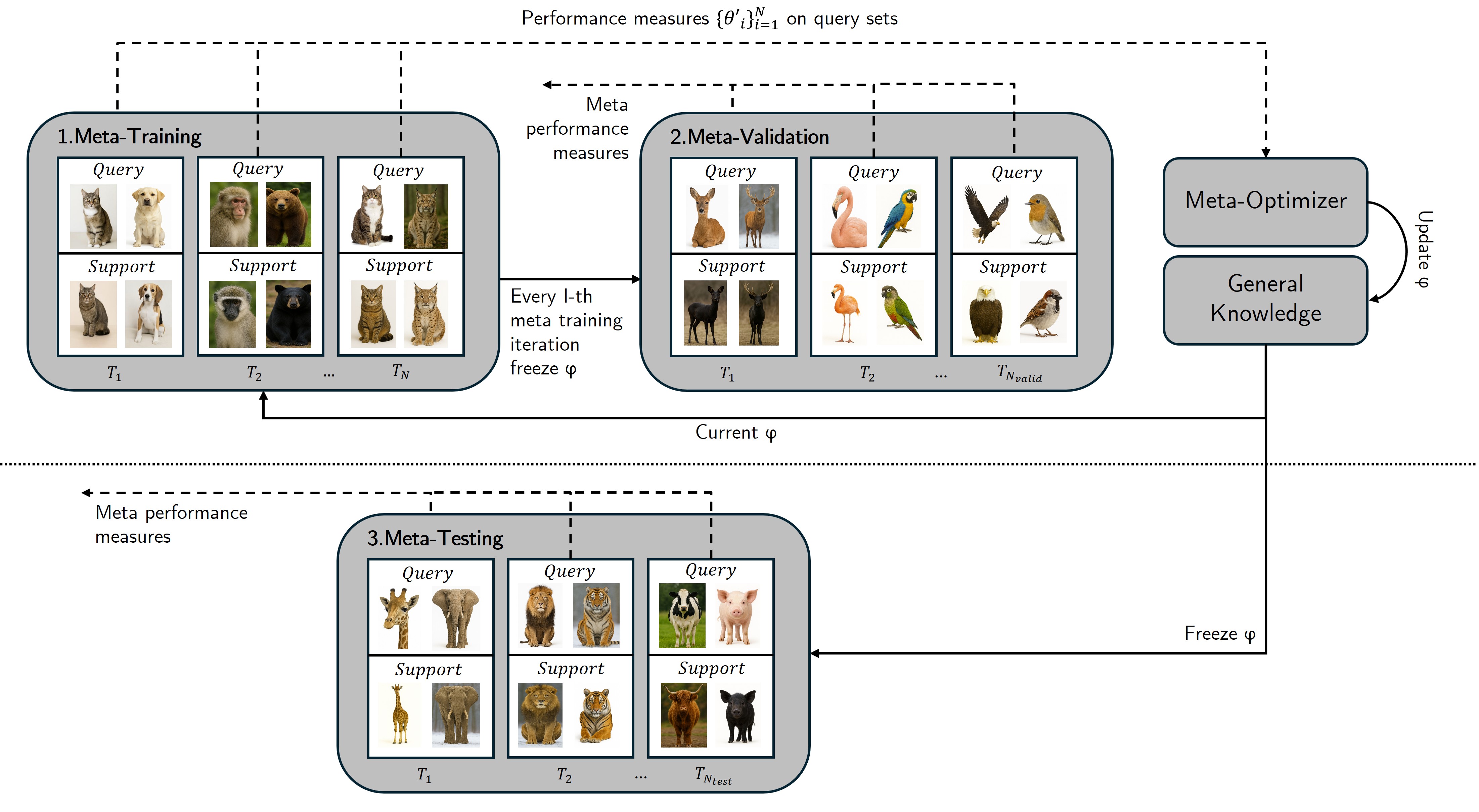
The Geometry of Adaptation: Gradient and Memory-Based Approaches
Gradient-based meta-learning, most notably demonstrated by the Model-Agnostic Meta-Learning (MAML) algorithm, centers on finding an initial model parameterization that facilitates rapid adaptation with only a few gradient steps. The core principle involves optimizing for parameters that minimize loss after one or more updates performed with data from a new task. This is achieved through a bi-level optimization process: an outer loop that updates the initial parameters based on the performance of the inner-loop adaptation, and an inner loop that performs gradient descent on a specific task using the current initial parameters. The resulting model is therefore primed to quickly learn new tasks with limited data, as it begins from a point in parameter space that is sensitive to changes induced by a small number of gradient updates. \nabla_{\theta} \sum_{T_i} L_{T_i}(\nabla_{\theta} L_{T_i}(\theta)) represents the optimization objective, where θ are the initial parameters and L is the loss function.
Gradient-based meta-learning algorithms, such as Model-Agnostic Meta-Learning (MAML), demonstrate strong performance when applied to task distributions characterized by limited variance and readily discernible patterns. However, their efficacy diminishes as task complexity increases, particularly when tasks require reasoning over extended sequences or incorporate intricate relationships between inputs. The core limitation stems from the reliance on a single set of initial parameters and a limited number of gradient updates; these methods struggle to effectively capture and generalize from distributions where optimal solutions necessitate substantial parameter shifts or the integration of information spanning multiple time steps. Consequently, performance degradation is observed in scenarios involving non-stationary environments, tasks requiring hierarchical inference, or those with sparse reward signals.
Memory-based meta-learning utilizes recurrent neural networks (RNNs) and similar architectures to maintain an internal state representing accumulated experience across a sequence of tasks. This allows the model to condition its adaptation not only on the current task’s data, but also on the history of previously encountered tasks, effectively providing a form of contextual memory. Unlike gradient-based approaches which directly update model parameters, memory-based methods use this internal state to modulate the processing of new data, enabling adaptation to tasks with complex dependencies and non-stationary distributions. The internal state acts as a buffer, storing relevant information from past tasks that can be retrieved and applied to improve performance on subsequent, related tasks, leading to more nuanced and flexible adaptation capabilities.
Escaping the Local Minimum: Bayesian Inference and Off-Policy Learning
PEARL (Probabilistic Embeddings for Actor-Critic Reinforcement Learning) significantly enhances sample efficiency in meta-reinforcement learning through the utilization of off-policy data. Traditional on-policy algorithms require interactions with the environment to update the agent’s policy, making them data-intensive. PEARL addresses this limitation by learning a probabilistic embedding of the environment’s dynamics and reward function from a dataset of previously collected transitions. This allows the agent to learn and improve its policy using data generated by potentially suboptimal or exploratory policies, effectively re-using experience and reducing the number of costly online interactions needed to adapt to new tasks. The learned embedding facilitates both policy learning and value function estimation, enabling efficient adaptation even with limited data from the current task.
Bayesian Reinforcement Learning (BRL) addresses the challenge of limited information by representing beliefs about the environment as probability distributions. Instead of estimating a single optimal policy, BRL maintains a posterior distribution over possible models, allowing the agent to explicitly quantify uncertainty in its predictions. This is particularly beneficial in sparse reward environments where traditional methods struggle due to infrequent feedback; by maintaining a distribution, the agent can explore more effectively and assign higher value to potentially rewarding, but currently uncertain, states. The agent updates this posterior using Bayes’ rule as it interacts with the environment, refining its beliefs and improving decision-making under ambiguity. This probabilistic approach facilitates both exploration and exploitation, enabling agents to learn more efficiently with limited data and navigate complex, uncertain environments.
VariBAD, a prominent algorithm in advanced meta-RL, addresses the challenge of adapting to new tasks by combining Bayesian inference with episodic memory. It maintains a distribution over possible task characteristics, represented as a latent variable, and updates this distribution based on observed trajectories. This Bayesian approach allows the agent to quantify uncertainty about the current task. The algorithm employs a memory mechanism, storing past experiences – state, action, reward tuples – to infer these task characteristics and improve policy adaptation. Specifically, VariBAD uses a recurrent neural network to process the episodic memory and estimate the posterior distribution over task parameters, enabling efficient off-policy learning and improved performance in few-shot learning scenarios by leveraging previously encountered tasks.
The Illusion of Generality: Scaling Adaptation with Modern Techniques
The Adaptive Agent marks a considerable advancement in artificial intelligence through the implementation of Transformer architectures, traditionally successful in natural language processing, for the dynamic task of sequence modeling in reinforcement learning. This approach allows the agent to process and understand sequences of observations and actions, enabling robust adaptation to previously unseen environments and tasks. Unlike traditional recurrent neural networks, Transformers excel at capturing long-range dependencies within these sequences, facilitating more informed decision-making and improved generalization. By effectively modeling the temporal structure of complex tasks, the agent demonstrates an enhanced ability to learn and perform efficiently, representing a departure from systems reliant on hand-engineered features or limited contextual understanding.
Distillation techniques represent a pivotal strategy for deploying sophisticated artificial intelligence in resource-constrained environments. The process involves training a large, high-capacity model – often referred to as the “teacher” – and then transferring its learned knowledge to a smaller, more efficient “student” model. This isn’t simply copying parameters; instead, the student learns to mimic the teacher’s behavior, specifically its probability distributions over possible actions or predictions. By focusing on replicating the reasoning of the larger model, rather than just its outputs, distillation allows the student to achieve comparable performance with significantly reduced computational demands. This knowledge transfer is particularly impactful as it enables the deployment of complex agents on platforms with limited processing power, broadening the scope of potential applications and paving the way for more accessible and scalable AI systems.
The agent’s capacity for rapid adaptation is significantly enhanced through the integration of Automated Curriculum Learning (ACL). Rather than being presented with a fixed sequence of challenges, the agent actively constructs its own learning pathway, prioritizing tasks that maximize its progress. This proactive approach involves the agent assessing its current skill level and then selecting subsequent challenges that are optimally situated to push its boundaries without overwhelming its capabilities. By dynamically adjusting the difficulty and complexity of the task sequence, the agent effectively sculpts its own learning experience, leading to substantially accelerated adaptation and improved performance compared to traditional, static curricula. This self-directed learning process allows the agent to efficiently explore the environment and acquire skills at a pace tailored to its individual learning trajectory.
Rigorous testing of the Adaptive Agent on demanding benchmarks such as MetaWorld and XLand reveals a substantial leap in both performance and generalization ability. These environments, characterized by intricate task variations and long-horizon dependencies, present a significant challenge to conventional reinforcement learning algorithms. Success in these complex domains signals a clear departure from prior evaluations primarily focused on simpler settings like grid-worlds, Atari games, and MuJoCo physics simulations. The agent’s proficiency demonstrates an ability to not only learn individual tasks, but to rapidly adapt to novel situations-a crucial step towards creating truly versatile artificial intelligence capable of operating effectively in the unpredictable complexities of real-world environments and signaling a progression toward increasingly sophisticated challenges for AI development.
A critical component of evaluating reinforcement learning agents lies in standardized performance metrics, yet current literature often lacks consistent application, hindering meaningful comparisons. This survey addresses this deficiency by clarifying essential measures – beyond simple reward accumulation – to assess generalization and adaptation capabilities. By establishing a more rigorous framework for evaluation, the study not only demonstrates the superior performance of the Adaptive Agent across diverse benchmarks, but also positions it as a leading example of a large-scale generalist agent capable of tackling increasingly complex environments. This refined approach allows for a more nuanced understanding of an agent’s true capabilities, moving beyond isolated task success to a comprehensive assessment of its learning efficiency and adaptability.
The pursuit of meta-reinforcement learning, as detailed in the survey, inevitably leads to acknowledging the inherent fragility of any constructed system. Each algorithm, each network architecture, represents a prediction about future environments – a prophecy, if you will. As Donald Knuth observed, “Premature optimization is the root of all evil.” This sentiment resonates deeply; the relentless drive to engineer ‘general’ intelligence often results in brittle systems hyper-tuned to specific training regimes. The shift toward transformer-based models, while promising increased adaptability, merely postpones the inevitable. Every deploy remains a small apocalypse, revealing the limitations of the system’s predictive capacity and the ever-present need for continuous adaptation.
What’s Next?
The trajectory traced within this work reveals a persistent, perhaps naive, ambition: to build agents that learn to learn. The field consistently reframes the problem – from gradient-based optimization of initial parameters to the architectural complexities of transformer networks – yet the fundamental challenge remains. Task inference, while increasingly sophisticated, is still a brittle exercise in pattern matching. A system that excels at a curated benchmark is not necessarily robust to the inevitable novelty of an open world. Stability is merely an illusion that caches well.
Future progress will not be marked by larger models or more intricate architectures, but by a willingness to embrace inherent unpredictability. The pursuit of ‘general’ intelligence necessitates accepting that complete control is an impossibility. Chaos isn’t failure – it’s nature’s syntax. The emphasis must shift from maximizing reward to managing uncertainty, from prediction to adaptation.
A guarantee is just a contract with probability. The true measure of success will not be achieving superhuman performance on contrived tasks, but building systems that gracefully degrade, learn from their errors, and exhibit a capacity for creative failure. The goal isn’t to eliminate risk, but to evolve alongside it.
Original article: https://arxiv.org/pdf/2602.19837.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Silver Rate Forecast
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- The Best Former NFL Players Turned Actors, Ranked
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
2026-02-25 01:19