Author: Denis Avetisyan
A new wave of research is moving beyond what neural networks do, to reveal how they actually compute, offering unprecedented insight into the workings of AI.
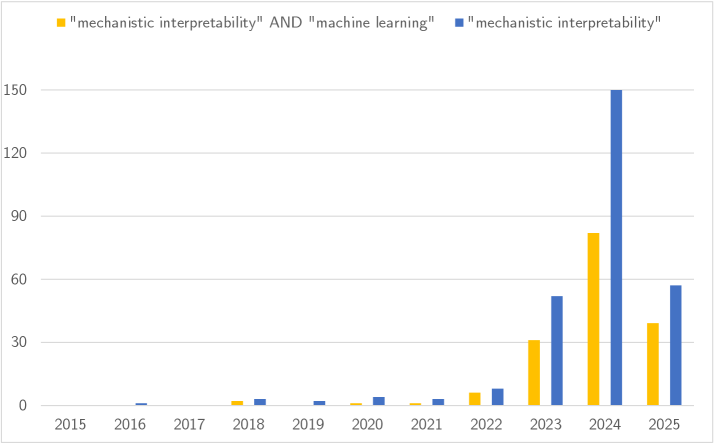
This review details the emerging field of Mechanistic Interpretability and its techniques for reverse-engineering the computations of neural networks.
Despite the increasing prevalence of deep neural networks, their internal workings remain largely opaque, hindering trust and scientific understanding. This paper, ‘Unboxing the Black Box: Mechanistic Interpretability for Algorithmic Understanding of Neural Networks’, provides a comprehensive overview of Mechanistic Interpretability (MI), a burgeoning field dedicated to reverse-engineering these models and uncovering the algorithms they implement. By moving beyond simply predicting what a network does to understanding how it does it, MI offers a path toward truly interpretable AI. Will this focus on internal computation unlock a deeper, more robust understanding of machine learning itself, transforming models from tools into subjects of scientific inquiry?
The Opaque Algorithm: Confronting the Limits of Deep Learning
Despite remarkable achievements in areas like image recognition and natural language processing, deep learning models, and especially the large-scale Foundation Models driving much of the current progress, operate as largely inscrutable “black boxes.” This opacity isn’t merely a matter of technical inconvenience; it fundamentally hinders trust and control. While these models can achieve impressive accuracy, understanding why a particular decision was reached remains a significant challenge. The complex interplay of millions – or even billions – of parameters within these neural networks makes it difficult to trace the reasoning process, creating a situation where outputs can be reliable but the underlying logic remains hidden. This lack of transparency is particularly concerning in high-stakes applications, as it prevents meaningful debugging, refinement, and verification of model behavior, potentially leading to unforeseen errors or biased outcomes. The inability to fully comprehend these systems poses a critical limitation to their widespread and responsible deployment.
The opacity of deep learning models presents significant challenges when deployed in critical applications. Without understanding why a model makes a particular prediction, potential biases embedded within the training data can lead to discriminatory outcomes in areas like loan applications or criminal justice. Furthermore, this lack of transparency creates security vulnerabilities; adversarial attacks, subtly crafted inputs designed to mislead the model, can go undetected, with potentially severe consequences in autonomous systems or medical diagnoses. Beyond these immediate risks, the inability to anticipate unintended consequences-behavior emerging from complex interactions within the network-hinders responsible innovation and public trust, necessitating careful consideration of interpretability alongside performance metrics.
The inherent complexity of deep learning models presents a significant challenge to understanding their decision-making processes. Conventional analytical techniques, designed for simpler algorithms, often fail when applied to the intricate web of interconnected nodes and weighted parameters within these networks. This opacity isn’t merely an academic concern; it actively hinders the ability to identify and correct errors, refine model performance, or even verify that the system is operating as intended. Without insight into how a model arrives at a particular conclusion, developers are left to treat the system as a “black box,” relying on empirical testing rather than reasoned understanding. Consequently, debugging becomes a process of trial and error, refinement is limited by intuition, and ensuring the robustness and reliability of these powerful systems remains a substantial undertaking.
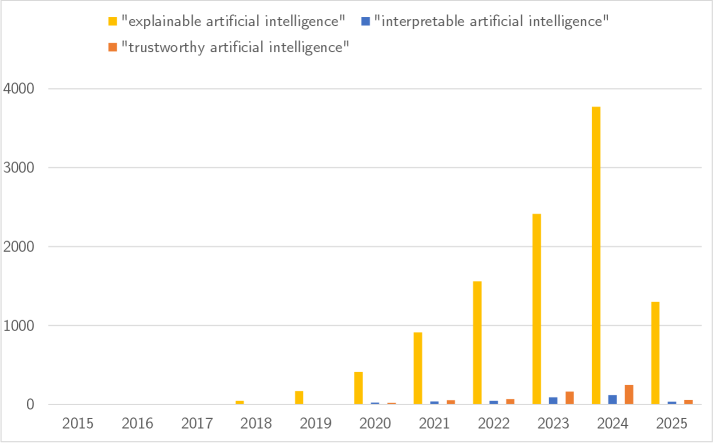
Reverse-Engineering the Algorithm: Towards Mechanistic Interpretability
Mechanistic Interpretability represents a research direction centered on decomposing neural networks to reveal the explicit algorithms they compute. Unlike traditional “black box” approaches that focus solely on input-output relationships, this field aims to identify and characterize the discrete computational steps performed within the network. This involves analyzing the weights, activations, and connectivity patterns to determine how information is processed and transformed. The goal is not merely to predict what a network does, but to understand how it achieves its results, treating the network as a transparent system of defined operations. Successful mechanistic interpretation will enable detailed analysis of model behavior and facilitate targeted interventions for improvement and control.
Traditional machine learning analysis primarily focuses on input-output relationships, treating neural networks as “black boxes.” Mechanistic interpretability, however, shifts the focus to the internal computations. This involves detailed analysis of individual neurons – identifying their specific functions, such as feature detection or logical operations – and tracing the flow of information through interconnected circuits. By characterizing these internal mechanisms, researchers aim to determine how a network arrives at a particular decision, rather than simply what decision it makes. This dissection involves techniques like activation patching and causal tracing to establish the computational role of specific network components and understand their contribution to the overall model behavior. This approach allows for a granular understanding of the implemented algorithms, moving beyond behavioral observation to reveal the underlying computational processes.
Circuit Discovery techniques systematically probe neural networks to identify interconnected groups of neurons – termed functional subnetworks or circuits – that perform specific computations. These methods involve activating different parts of the network and observing the resulting activations to map the flow of information. By analyzing activation patterns and the weights of connections within these circuits, researchers can infer the circuit’s role – for example, edge detection in an image processing model or specific feature recognition in a natural language processing system. The goal is to decompose the complex network into understandable, modular components, allowing for the characterization of each circuit’s function and its contribution to the overall model behavior. This decomposition relies on techniques such as automated feature attribution and the identification of strongly connected components within the network graph.
The development of reliable, safe, and trustworthy artificial intelligence systems necessitates a comprehensive understanding of their internal logic. Current AI models, particularly large neural networks, often function as “black boxes,” where inputs and outputs are observable but the intermediate computational steps remain opaque. This lack of transparency hinders debugging, verification, and the identification of potential failure modes. A clear understanding of the algorithms implemented within these models allows for targeted interventions to correct errors, improve robustness against adversarial attacks, and ensure predictable behavior in critical applications. Furthermore, interpretability is crucial for establishing trust, as users and stakeholders require confidence that the system operates as intended and aligns with ethical guidelines and safety standards.
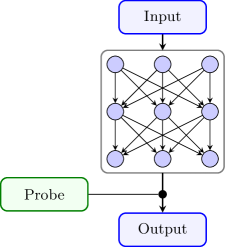
Decoding the Representation: Disentangling Features Within the Algorithm
Feature disentanglement addresses the inherent complexity of neural representations, wherein individual neuron activations rarely correspond to a single identifiable factor of variation in the input data. Instead, neurons typically encode a superposition of multiple features, creating a distributed representation. This poses a significant challenge for interpretability, as directly observing neuron activity does not reveal which specific aspects of the input are being represented. Successful disentanglement requires techniques capable of isolating and identifying the distinct, underlying factors contributing to the observed neuronal response, allowing researchers to understand how different features are encoded and processed within neural circuits. The difficulty arises from the high dimensionality of neural data and the non-linear relationships between input features and neuronal activation patterns.
Sparse Autoencoders are a type of neural network architecture utilized to decompose high-dimensional data into a set of interpretable features. These networks are trained to reconstruct their input data through a bottleneck layer with fewer neurons than the input, forcing the network to learn a compressed, efficient representation. The “sparse” aspect is enforced through regularization techniques, such as L1 regularization on the activations of the bottleneck layer, which encourages only a small number of neurons to be active for any given input. This sparsity promotes the isolation of individual features within distinct neurons, as the network seeks to represent each input using a minimal, distributed code. By identifying which neurons respond most strongly to specific input variations, researchers can gain insights into the features the network has learned and how those features contribute to the overall representation.
Superposition in neural representations refers to the encoding of multiple, distinct features within the activation of a single neuron. This phenomenon deviates from the ideal of sparse, disentangled representations where each neuron ideally responds to only one specific input or feature. Consequently, interpreting neuron activations becomes significantly more complex, as the observed response is a combined effect of several underlying factors. This necessitates methods capable of deconvolution or separation of these superimposed features to accurately determine the neuron’s role within the broader neural circuit and to understand how information is being processed. The degree of superposition varies across brain areas and network layers, impacting the efficiency and interpretability of internal representations.
Activation patching is a technique used to determine the functional role of individual neurons within a neural circuit by selectively ablating or modulating their activity and observing the resulting changes in downstream processing. This involves identifying neurons that significantly impact a specific computation and then systematically altering their activation patterns – either by setting them to a constant value or replacing their activations with those from a different input. By analyzing how these manipulations affect the activity of subsequent layers, researchers can trace the flow of information through the circuit and understand how the neuron’s activity contributes to the overall transformation of the input signal. The technique allows for the identification of neurons critical for specific features or computations, providing insights into the circuit’s internal representation and functional organization.

Beyond Transparency: Towards Robustness, Privacy, and Control of the Algorithm
Mechanistic interpretability transcends theoretical curiosity by offering concrete pathways to enhance the robustness of complex machine learning models. Rather than treating these systems as opaque entities, this approach dissects their internal mechanisms, revealing how specific computations contribute to overall performance. This detailed understanding allows researchers to pinpoint vulnerabilities – subtle flaws in the model’s logic that can be exploited by adversarial attacks or unexpected inputs. By identifying these weaknesses, targeted interventions can be developed to fortify the model against manipulation and improve its reliability in real-world scenarios. Consequently, mechanistic interpretability doesn’t just explain what a model does, but illuminates how it does it, paving the way for proactively building more resilient and trustworthy artificial intelligence.
A crucial benefit of mechanistic interpretability lies in its potential to bolster data privacy. Current machine learning models, while powerful, often operate as ‘black boxes’, raising concerns about the inadvertent memorization and potential leakage of sensitive information present in their training datasets. Through detailed analysis of a model’s internal mechanisms, researchers can now actively verify whether specific data points, or patterns derived from them, are being stored and utilized in ways that compromise privacy. This isn’t simply about detecting obvious memorization; it extends to identifying subtle representations that, while not exact copies, could allow for the reconstruction of private data. By pinpointing these vulnerabilities, developers can implement targeted interventions – such as differential privacy techniques or internal regularization – to mitigate risks and ensure that models generalize effectively without revealing confidential information.
Mechanistic interpretability offers a pathway beyond simply understanding a model’s reasoning; it enables precise, surgical modification of its internal workings. Rather than retraining an entire model to correct an error or adapt to changing circumstances, researchers are developing techniques to directly edit specific neurons or circuits responsible for particular behaviors. This granular control promises to drastically reduce computational costs and improve efficiency, allowing for targeted fixes without disrupting the model’s overall performance. Imagine correcting a factual inaccuracy by adjusting a single weight, or adapting a model to a new task by rewiring a specific computational pathway – this level of control shifts the paradigm from opaque, monolithic systems to transparent, malleable algorithms capable of continuous refinement and adaptation.
The progression toward mechanistic interpretability signals a decisive move beyond the era of artificial intelligence as inscrutable “black boxes.” Historically, machine learning models have functioned as complex input-output mappings, offering predictions with little insight into how those conclusions were reached. This new paradigm prioritizes dissecting the internal mechanisms of these models, allowing researchers to not only understand the reasoning behind a prediction, but also to directly influence and control that process. Instead of simply accepting a model’s output, the focus shifts to manipulating its internal components – correcting errors, refining its knowledge, and ensuring alignment with desired behaviors. This transition promises a future where algorithmic systems are not just powerful predictors, but transparent, auditable, and ultimately, controllable tools – fundamentally altering the relationship between humans and artificial intelligence.
The pursuit of Mechanistic Interpretability, as detailed in the article, centers on dismantling the ‘black box’ nature of neural networks. It seeks not merely correlation, but a causal understanding of internal computations. This echoes Edsger W. Dijkstra’s sentiment: “It’s not enough to show that something works; you must also show why it works.” The article’s focus on circuit discovery and feature disentanglement attempts precisely this – to reveal the underlying logic, stripping away complexity to expose the essential mechanisms. A system that requires opaque prediction has, in a sense, already failed to provide true insight. The goal isn’t building more elaborate networks, but elegantly simple ones whose function is readily apparent.
What Remains?
The pursuit of mechanistic interpretability, as detailed within, reveals not a path towards complete understanding, but a relentless refinement of ignorance. The field does not solve the black box; it merely sculpts away layers of opacity, revealing ever more intricate, and potentially infinite, nested structures. Current methods, while progressing, remain fundamentally limited by the scale of modern networks; disentangling computation in a network with billions of parameters is akin to charting a nebula with a hand-drawn map.
Future progress necessitates a move beyond descriptive analysis. Identifying circuits is valuable, but insufficient. The critical question is not what a network computes, but why it computes it that way. A focus on causal inference, extending beyond simple feature attribution, is paramount. Furthermore, the observed phenomenon of superposition-where individual neurons participate in multiple, seemingly contradictory computations-demands deeper theoretical investigation; it hints at a computational paradigm fundamentally different from our own.
Ultimately, the value of this endeavor lies not in achieving perfect knowledge, an asymptotic goal, but in establishing a framework for principled reduction. The aim is not to replicate intelligence, but to understand it, even if that understanding reveals the inherent limitations of our own cognitive tools. What remains, after the circuits are mapped and the features disentangled, will define the true boundaries of machine, and perhaps, human, intelligence.
Original article: https://arxiv.org/pdf/2511.19265.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading Smarter: AI-Powered Execution Schedules
- Gold Rate Forecast
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Smarter Order Execution: How AI is Outperforming Wall Street’s Playbook
- 15 Films That Were Shot Entirely on Phones
2025-11-26 00:17