Author: Denis Avetisyan
A new technique embeds robust, undetectable signals within synthetic datasets to verify their origin and integrity.

This paper introduces Tab-Drw, a DFT-based watermarking scheme for tabular data that balances high fidelity with robustness against common attacks.
The increasing prevalence of synthetic tabular data, while beneficial across numerous fields, introduces critical concerns regarding provenance and potential misuse. Addressing this, we present ‘TAB-DRW: A DFT-based Robust Watermark for Generative Tabular Data’, a novel watermarking scheme that embeds imperceptible signals within the frequency domain of tabular datasets. By leveraging the Discrete Fourier Transform and a rank-based pseudorandom bit generation method, TAB-DRW achieves strong detectability and robustness against common post-processing attacks while preserving data fidelity and accommodating mixed data types. Could this approach pave the way for trustworthy and traceable synthetic data generation in sensitive domains like healthcare and finance?
The Inevitable Erosion of Data Trust
The escalating value of tabular data – encompassing everything from financial records and customer databases to scientific measurements and logistical information – is directly correlated with a surge in concerns regarding its origin and trustworthiness. As datasets become central to decision-making processes and increasingly fuel machine learning algorithms, establishing clear provenance – a verifiable history of the data’s creation and modification – is paramount. Simultaneously, the potential for malicious tampering or unintentional corruption introduces significant risks, particularly as data is shared, sold, and integrated across multiple platforms. This heightened vulnerability necessitates robust mechanisms to not only detect alterations but also to confidently assert the data’s integrity, ensuring that analyses and insights are built upon a foundation of reliable information. The demand for verifiable data is no longer simply a matter of due diligence; it’s becoming a critical component of responsible data handling and a safeguard against increasingly sophisticated threats.
Conventional data security measures, such as encryption and access controls, primarily focus on preventing unauthorized access, but often lack the mechanisms to reliably prove data authenticity after it has been shared or processed. While these methods can safeguard data at rest or in transit, they frequently fail to detect subtle alterations or confirm the data’s original source. This is particularly problematic in collaborative environments or when data is integrated from multiple sources, as even minor tampering can compromise analysis and decision-making. Consequently, verifying data provenance and integrity requires more sophisticated techniques that go beyond simply preventing breaches; it demands a method of establishing trust within the data itself, a need that traditional approaches are increasingly unable to meet.
Data watermarking addresses the critical need for provenance and authenticity in increasingly valuable tabular datasets. This technique functions by subtly embedding imperceptible signals – akin to a digital fingerprint – directly within the data’s values. Unlike methods that rely on external logs or access controls, watermarking links data back to its source even after it has been copied, shared, or modified. These embedded signals are designed to be statistically undetectable to casual observation, ensuring data utility isn’t compromised, yet robust enough to withstand common data manipulations. Successful detection of the watermark confirms the data’s origin and integrity, offering a powerful deterrent against unauthorized use or malicious tampering and establishing a clear chain of custody for sensitive information.
Unlike images or audio, where watermarks can be subtly woven into the data without significantly altering perception, tabular data’s rigid structure introduces considerable hurdles. Simple perturbations to individual data points can dramatically impact analytical results, making traditional watermarking techniques ineffective or easily detectable. The inherent correlations between columns and rows-essential for data utility-complicate the process of embedding a signal without introducing statistical anomalies. Researchers are therefore exploring methods that leverage these relationships, such as modifying feature distributions or introducing carefully calibrated noise patterns, while striving to maintain data integrity and analytical validity. The challenge lies in creating a watermark robust enough to survive common data manipulations-like aggregation or filtering-yet imperceptible to anyone attempting to discern its presence without prior knowledge of the embedding scheme.
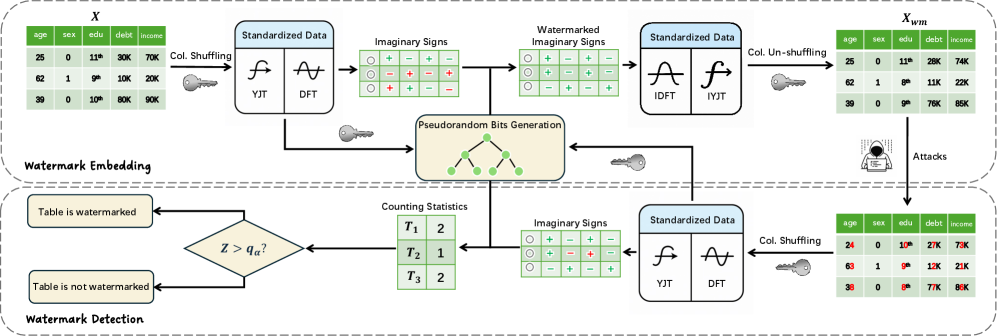
Shifting the Signal: Watermarking in the Frequency Domain
TabDrw mitigates the difficulties inherent in watermarking tabular data by shifting the embedding process from the spatial domain to the frequency domain. Traditional methods applied directly to table values are susceptible to manipulation and detectable alterations; however, by applying the Discrete Fourier Transform ($DFT$) to the tabular data, TabDrw transforms the data into a frequency representation. This allows for the embedding of a watermark signal as subtle modifications to the frequency coefficients. These modifications are less perceptible and more robust against common data manipulations, as alterations to the frequency components are less likely to be noticed or removed without impacting the overall data utility. The frequency domain representation effectively distributes the watermark across the entire dataset, improving resilience compared to embedding directly into individual cell values.
The Discrete Fourier Transform (DFT) is employed to convert tabular data from the spatial domain into the frequency domain, represented as a spectrum of amplitudes and phases. This transformation enables watermark embedding by manipulating the coefficients within the frequency spectrum. Because the human perceptual system is less sensitive to subtle changes in frequency components, modifications to these coefficients can be made without introducing visually detectable distortions in the reconstructed tabular data. Specifically, the $DFT$ decomposes the table into a sum of complex exponentials, and the watermark signal is embedded by slightly altering the magnitudes or phases of selected frequency components. Upon reconstruction via the Inverse Discrete Fourier Transform (IDFT), these alterations remain largely imperceptible, providing a means for covert data transmission within the table itself.
The Yeo-Johnson Transformation (YJT) is applied as a preprocessing step to tabular data prior to Discrete Fourier Transform (DFT) analysis to improve the efficacy of subsequent watermarking. Tabular data often exhibits non-normal distributions and varying scales across columns, introducing heterogeneity that can negatively impact the DFT and reduce watermark robustness. The YJT is a power transform, similar to the Box-Cox transformation, but does not require data to be strictly positive; it normalizes the data distribution, reducing skewness and variance, and thereby stabilizing the data for frequency domain analysis. This normalization process minimizes the impact of outliers and ensures a more consistent signal representation after applying the DFT, leading to more reliable watermark embedding and extraction.
The watermark embedding in TabDrw is governed by pseudorandom bits derived from a combination of GrayCode and RankStatistic methods. GrayCode is employed to generate a sequence with minimal Hamming distance between successive bits, facilitating incremental watermark changes. RankStatistic then operates on the tabular data to determine the order of values, and this ranking, combined with the GrayCode sequence, dictates the specific locations within the frequency domain where the watermark signal is inserted. This approach ensures that the watermark is distributed throughout the data’s frequency representation, enhancing robustness against various attacks and manipulations while maintaining imperceptibility. The combination provides a statistically uncorrelated bitstream for controlled watermark embedding.

Evidence of Resilience: Performance and Evaluation
Rigorous evaluation of TabDrw necessitates the use of synthetically generated tabular datasets, produced by the TabSyn framework, to maintain precise control over experimental variables. Utilizing synthetic data allows for the systematic manipulation of dataset characteristics – such as size, feature distributions, and correlations – which is crucial for isolating the performance of the watermark embedding and detection mechanisms. This approach circumvents the inherent complexities and uncontrolled factors present in real-world datasets, enabling repeatable and statistically significant results when assessing TabDrw’s efficacy under various conditions. The ability to define ground truth regarding the presence or absence of the WatermarkSignal within the synthetic data is also a key benefit, simplifying the calculation of key performance indicators like the true positive rate and false positive rate.
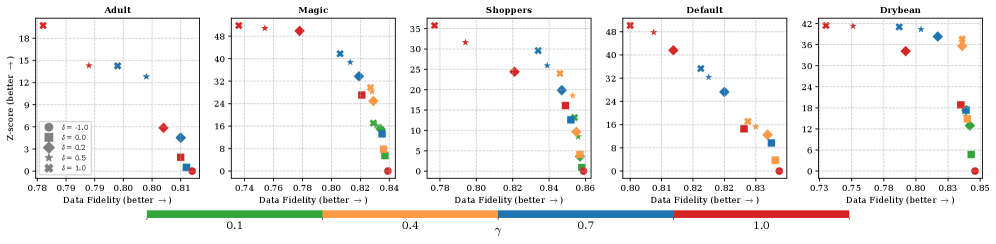
The Z-score is utilized as the primary statistical metric for evaluating the detectability of the embedded $WatermarkSignal$. This score quantifies the difference between the observed watermark strength and the expected background noise, allowing for a determination of statistical significance. Experimental results indicate that TabDrw achieves the highest Z-scores when tested on the Adult, Shoppers, and Default datasets, signifying a strong and reliably detectable watermark presence within these specific tabular data distributions. Higher Z-scores correlate with a greater confidence level in the successful detection of the embedded signal, indicating improved robustness against potential data perturbations and attacks.
Watermark detection reliability in TabDrw is quantified using the true positive rate (TPR) and false positive rate (FPR). Experimental results demonstrate a TPR of 1.0, indicating perfect detection of the embedded watermark, achieved at a false positive rate of 0.1% across most tested datasets. Critically, this performance is obtained utilizing only 300 rows of tabular data, establishing an efficient detection capability with limited data requirements.
TabDrw utilizes the frequency domain for watermark embedding, a technique that enhances resilience to data perturbations. By representing tabular data in the frequency domain, the embedded $WatermarkSignal$ becomes distributed across multiple frequency components, rather than being localized to specific data points. This distribution mitigates the impact of common data transformations – such as normalization, scaling, or the addition of noise – which tend to affect only a limited range of frequencies. Experimental results demonstrate TabDrw’s superior robustness against post-processing attacks, including row shuffling, column dropping, and feature scaling, maintaining high detection accuracy even after these transformations are applied to the dataset.
Expanding the Toolkit: A Future of Traceable Data
Recent advancements in data watermarking extend beyond traditional methods like TabDrw, with techniques such as TabWak pioneering a novel approach that utilizes diffusion models. Instead of directly altering data values, TabWak embeds signals within the inherent noise of the data’s latent space. This strategy offers a subtle yet effective means of tracking data provenance and detecting unauthorized modifications. By leveraging the power of diffusion models – typically used for generative tasks – the watermark becomes integrated into the data’s underlying structure, making it more resilient to common data transformations and potentially reducing the risk of detection or removal. This embedding within latent noise represents a significant departure from conventional watermarking, promising a more robust and imperceptible solution for safeguarding tabular data integrity.
MUSE presents a unique watermarking approach for tabular data by strategically selecting samples to modify based on a calculated pseudorandom score. This method deviates from directly altering data points and instead focuses on a curated subset, enhancing robustness against removal attacks. Each row receives a score, and those exceeding a threshold are subtly adjusted to embed the watermark. The efficacy of this selective modification is then rigorously assessed using TabSyn, a tool designed to evaluate watermark detectability and data fidelity. By combining pseudorandom selection with careful evaluation, MUSE offers a complementary strategy to techniques like TabDrw, expanding the options for safeguarding data integrity and traceability in sensitive applications.
Despite employing varied approaches, current watermarking techniques for tabular data converge on a singular objective: to reliably verify data integrity and establish its origin. Methods such as TabDrw, TabWak, and MUSE each offer unique embedding strategies, yet all aim to subtly alter data in a way that signals authenticity without compromising usability. Notably, TabDrw demonstrates a commitment to preserving data quality, achieving a remarkably low level of degradation – less than 0.01 – while successfully embedding its watermark. This shared focus on both security and minimal disruption underscores the growing importance of provenance tracking in an era increasingly reliant on data-driven insights and applications.
As reliance on data-driven applications expands across critical sectors – from healthcare and finance to scientific research and policy-making – establishing robust methods for data integrity and provenance becomes paramount. The continued development of watermarking techniques, like those explored for tabular data, isn’t merely a technical exercise, but a fundamental step in fostering trust. Without verifiable data origins and assurances against malicious or unintentional alteration, the potential for flawed analysis, biased outcomes, and eroded public confidence increases substantially. These emerging strategies offer a means to demonstrate data authenticity, enabling stakeholders to confidently utilize information and build reliable systems, ultimately solidifying the foundation for responsible innovation and informed decision-making in an increasingly digital world.
The pursuit of perfect watermarking, as demonstrated by Tab-Drw’s fidelity and robustness against attacks, is a curious exercise. It seeks to embed information without disrupting the core structure, a delicate balance mirroring the growth of any complex system. Donald Knuth observes, “A system that never breaks is dead.” This resonates deeply with the work; a watermark must be detectable, even under scrutiny, implying a controlled vulnerability. The authors’ frequency domain analysis and robust bit generation aren’t about preventing all attacks-an impossible feat-but about ensuring a predictable failure mode, a traceable signature within the inevitable entropy of data manipulation. It’s not about flawlessness, but about revealing the inherent structure of the system itself.
What Lies Ahead?
The pursuit of watermarking generative tabular data, as demonstrated by this work, is less a problem of signal encoding and more a study in inevitable compromise. Each frequency-domain adjustment, each pseudorandom bit woven into the data’s fabric, is a prophecy of future failure-a temporary reprieve before adversarial adaptation. The architecture isn’t structure; it’s a compromise frozen in time. One imagines a continuing arms race, where the fidelity metrics rise only to be surpassed by more subtle attacks.
The true difficulty isn’t simply detecting a watermark, but establishing provenance in a world where data perpetually remixes itself. Current evaluations focus on specific attacks, but the landscape of potential manipulations is vast and continuously evolving. Future work must shift from evaluating resilience against known distortions to assessing the detectability of any modification, however novel.
Technologies change, dependencies remain. The core issue isn’t the Discrete Fourier Transform itself, nor any particular bit generation algorithm. It’s the fundamental tension between utility and control-the inherent fragility of any attempt to impose order on a system designed for emergence. The field will likely move beyond watermark detection and towards systems capable of auditing data lineage – tracing its transformations rather than merely confirming its ‘authenticity’.
Original article: https://arxiv.org/pdf/2511.21600.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- The Best Former NFL Players Turned Actors, Ranked
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Biogen’s Jolly Good Showing
2025-11-30 20:18