Author: Denis Avetisyan
A new theoretical framework offers a deeper understanding of how to align language model outputs, improving fine-tuning and preventing performance drops.
This paper introduces Distribution Discrimination Theory to quantify and optimize language model distributions for enhanced generalization and reduced catastrophic forgetting.
While reinforcement learning (RL) typically outperforms supervised fine-tuning (SFT) in language model alignment, its computational expense limits broader application. This gap motivates the work ‘Towards On-Policy SFT: Distribution Discriminant Theory and its Applications in LLM Training’, which introduces a framework for achieving on-policy learning within an efficient SFT pipeline. By leveraging \textit{Distribution Discriminant Theory (DDT)}, the authors propose techniques-including \textit{In-Distribution Finetuning (IDFT)} and \textit{Hinted Decoding}-to align training data with the model’s induced distribution and enhance generalization. Can this approach offer a practical pathway to robust and efficient language model training, bridging the performance gap between SFT and RL without sacrificing computational feasibility?
Navigating the Shifting Sands of Language: Understanding Distributional Challenges
Large Language Models, despite showcasing remarkable proficiency in various natural language tasks, often experience a significant drop in performance when confronted with data that deviates from the patterns observed during their initial training. This phenomenon, known as distributional shift, arises because these models learn to rely on statistical correlations present in the training dataset; when those correlations no longer hold true in new data – perhaps due to changes in topic, style, or demographic representation – the model’s predictions become less reliable. Essentially, an LLM excels within the confines of its learned distribution but struggles to generalize effectively to unseen variations, highlighting a critical limitation for real-world applications where data is rarely static or perfectly representative of the training conditions. This sensitivity underscores the need for techniques that enhance robustness and adaptability, enabling these models to maintain consistent performance across diverse and evolving data landscapes.
The practical application of Large Language Models frequently encounters a significant hurdle: distributional shift. While these models excel within the confines of their training data, performance diminishes when presented with inputs diverging from that initial distribution – a common occurrence in real-world scenarios. This limitation isn’t merely a matter of accuracy; it represents a fundamental challenge to reliable deployment, as seemingly minor variations in phrasing, topic, or demographic representation can lead to unpredictable outputs. Consequently, research is increasingly focused on developing robust adaptation strategies, moving beyond simple fine-tuning to explore techniques that enhance a model’s ability to generalize and maintain consistent performance across diverse and evolving data landscapes. These strategies range from data augmentation and domain adaptation to more sophisticated approaches like meta-learning and continual learning, all aimed at bridging the gap between training and deployment environments.
While seemingly a straightforward solution, traditional supervised fine-tuning (SFT) can inadvertently worsen the challenges posed by distributional shift. By exposing a pre-trained large language model to a new dataset, SFT aims to adapt its knowledge; however, if this new data differs significantly from the original training distribution, the model risks overfitting. This means it begins to prioritize memorizing the specifics of the new, potentially limited, dataset rather than maintaining its broader generalization abilities. Consequently, performance on data resembling the original distribution may actually decrease, and the model becomes increasingly susceptible to biases present within the fine-tuning set. The result is a model that excels on a narrow range of inputs but falters when confronted with the diversity of real-world data, highlighting the need for more nuanced adaptation strategies beyond simple fine-tuning.
A core challenge in deploying Large Language Models lies not just in their capacity, but in discerning how they learn and extrapolate from the data they encounter. Current research suggests LLMs don’t simply memorize; they construct internal representations of data distributions, effectively creating a probabilistic model of language. However, the fidelity of this model-how accurately it reflects the underlying data-is crucial for generalization. Investigations are now focused on mapping these internal representations to identify biases, understand the model’s sensitivity to distributional shifts, and ultimately, engineer more robust generalization capabilities. Techniques such as analyzing activation patterns, probing hidden states, and employing information-theoretic measures offer potential avenues for revealing the nuances of LLM generalization and building models that gracefully adapt to unseen data.
Quantifying Alignment: CLL and DDT as Diagnostic Tools
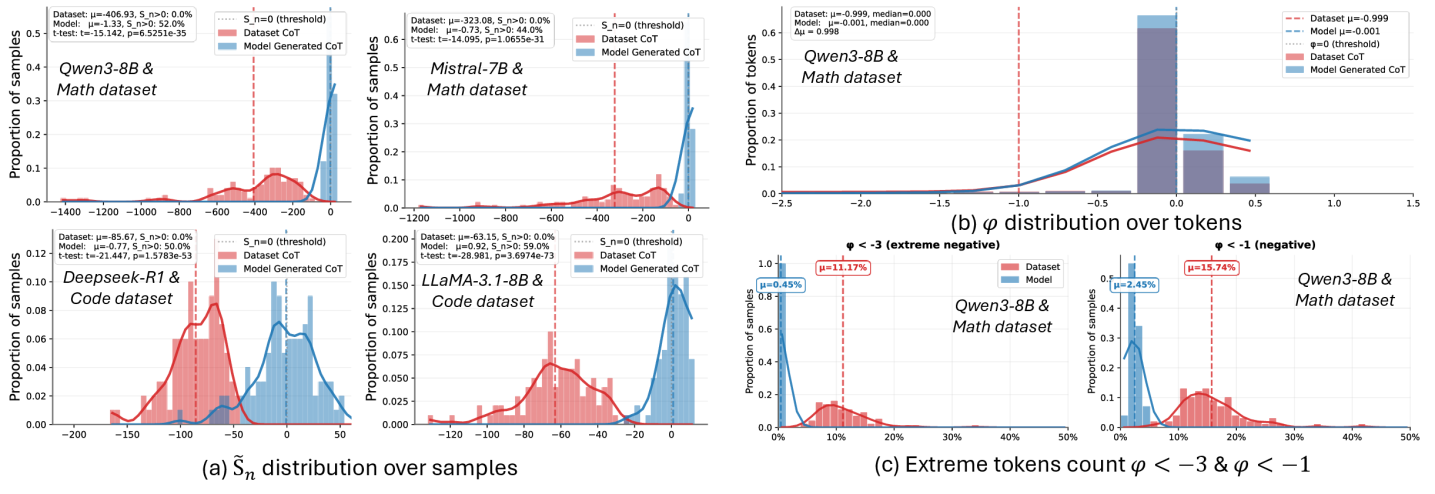
Centered Log-Likelihood (CLL) is a statistical method used to measure the degree to which a probability distribution generated by a model corresponds to an observed empirical data distribution. It functions by calculating the log-likelihood of the observed data under the model’s predicted distribution, then centering this likelihood to avoid biases from model calibration. CLL = \sum_{i=1}^{N} log(p(x_i)), where p(x_i) represents the probability assigned by the model to the observed data point x_i, and the summation is performed over all N data points. A higher CLL score indicates better alignment, as the model assigns higher probabilities to the observed data, effectively quantifying the similarity between the predicted and empirical distributions.
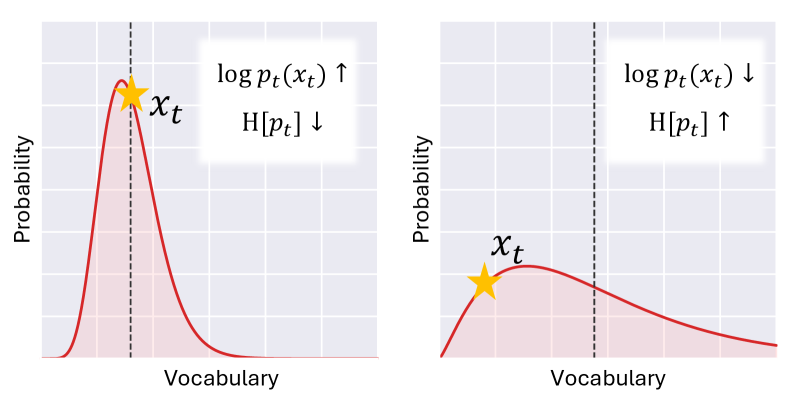
Distribution Discriminant Theory (DDT) provides a framework for evaluating the characteristics of probability distributions generated by Large Language Models (LLMs). DDT focuses on quantifying the separability between the distributions of different classes or conditions within the LLM’s output. This is achieved by analyzing the overlap or divergence between these distributions, effectively measuring how distinguishable the model’s predictions are. Key to this analysis is the calculation of φ (phi), representing the Signal-to-Noise Ratio, which indicates the degree of separation; a lower φ value signifies increased overlap and thus, less discriminability between the distributions. The application of DDT allows researchers to move beyond simple accuracy metrics and gain a nuanced understanding of the quality and characteristics of the distributions learned by LLMs.
Centered Log-Likelihood (CLL) employs the principle of maximizing log-likelihood to quantify the alignment between a model’s predicted probability distribution and the observed empirical data distribution. Specifically, CLL calculates the log probability of the observed data under the model’s predicted distribution, centered around the true data points to mitigate bias. Log Likelihood = \sum_{i=1}^{n} log(P(x_i)), where P(x_i) represents the probability of the i-th data point x_i according to the model. A higher log-likelihood value indicates a better match between the predicted and observed distributions, effectively measuring the model’s ability to accurately represent the underlying data.
Researchers utilizing a combined Centered Log-Likelihood (CLL) and Distribution Discriminant Theory (DDT) methodology have achieved an average φ (Signal-to-Noise Ratio) of -0.032141. This value indicates a quantifiable improvement in the alignment between the model’s predicted probability distributions and the observed data. A higher φ value, even approaching zero from negative values, suggests a stronger signal – meaning the model’s predictions are more representative of the true data distribution and less influenced by noise or spurious correlations. This metric provides a concrete measurement of how well the model captures the underlying patterns within the data, enabling more accurate and reliable predictions.
In-Distribution Fine-Tuning: A Principled Approach to Adaptation
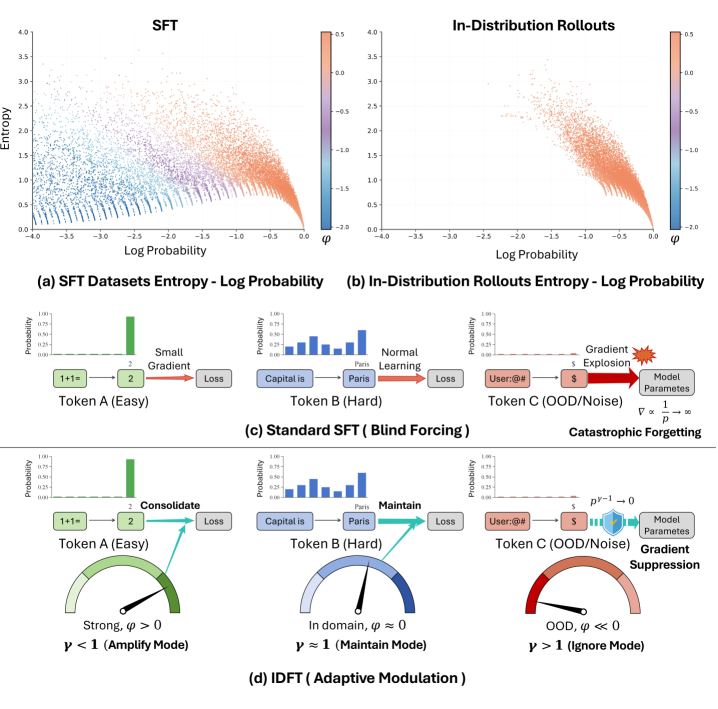
In-Distribution Fine-Tuning (IDFT) represents a departure from traditional Supervised Fine-Tuning (SFT) methodologies by specifically prioritizing training data that closely matches the statistical distribution of data the model was originally trained on. This approach focuses on refining the model’s existing capabilities within its established knowledge base, rather than attempting to significantly broaden its scope with potentially dissimilar data. By concentrating on in-distribution examples, IDFT aims to improve performance and stability, reduce the likelihood of catastrophic forgetting, and enhance generalization capabilities within the defined data domain. The core principle is to optimize the model’s response to data it is already proficient in handling, leading to more predictable and reliable outputs.
In-Distribution Fine-Tuning (IDFT) utilizes Data Distribution Testing (DDT) as a core component to identify data points that closely match the model’s pre-training distribution. This process involves analyzing the statistical properties of the training data and prioritizing examples that fall within the established distribution, effectively reducing the influence of out-of-distribution or noisy data. By emphasizing in-distribution data, IDFT minimizes the risk of overfitting to spurious correlations present in limited or biased datasets. Furthermore, this approach actively mitigates bias amplification, as the model is less likely to extrapolate from atypical examples, leading to improved generalization and more reliable performance on unseen, in-distribution data.
Offline Reinforcement Learning (Offline RL) integration within In-Distribution Fine-Tuning (IDFT) allows for behavioral refinement by leveraging distributional criteria as reward signals. This process utilizes a fixed dataset – identified through Data Distribution Tuning (DDT) as being in-distribution – to train a policy without requiring further environmental interaction. The reward function is designed to incentivize actions that maintain or improve alignment with the established data distribution, effectively shaping the model’s behavior based on the characteristics of the training data. This differs from traditional RL which relies on active exploration and can introduce distributional shift; instead, Offline RL within IDFT focuses on optimizing performance within the existing data manifold, leading to increased stability and data efficiency.
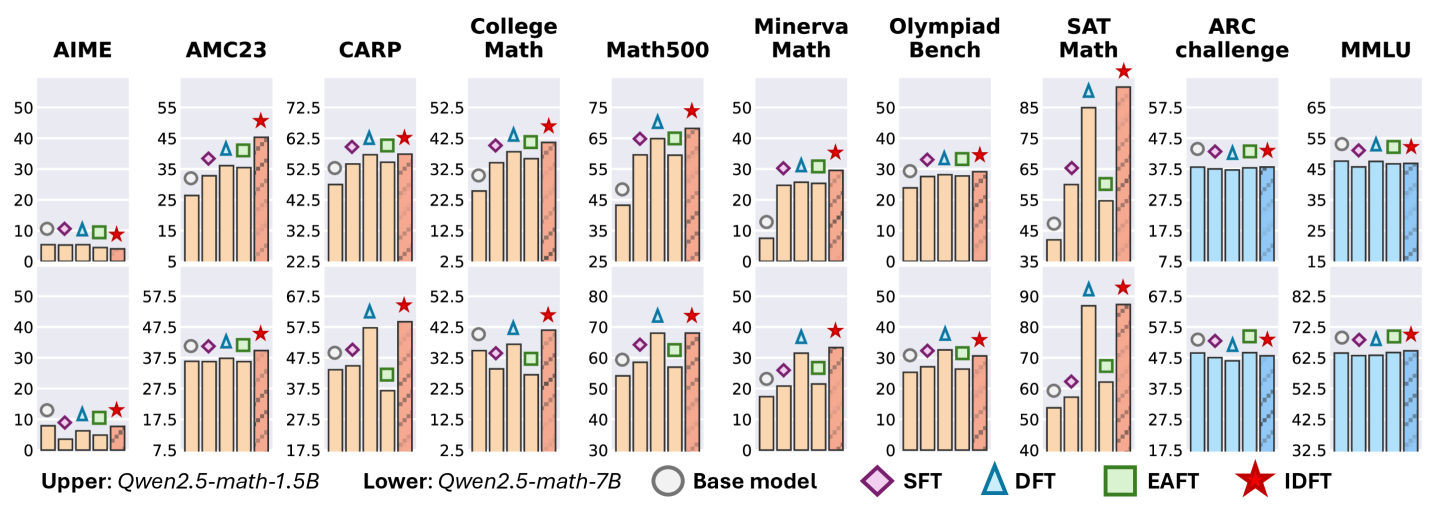
Evaluations demonstrate that the In-Distribution Fine-Tuning (IDFT) approach achieves accuracy and generalization performance comparable to standard Supervised Fine-Tuning (SFT) methods. Critically, IDFT accomplishes these results with improved data efficiency, requiring fewer training examples to reach comparable performance levels. A specific demonstration of this efficacy is the success achieved by the African Team in competitive matches; utilizing IDFT with optimized data alignment and training protocols, the team secured victories in 11 matches, validating the practical application and effectiveness of this adaptation strategy.
Guiding the Generation Process: Hinted Decoding for Consistent Outputs
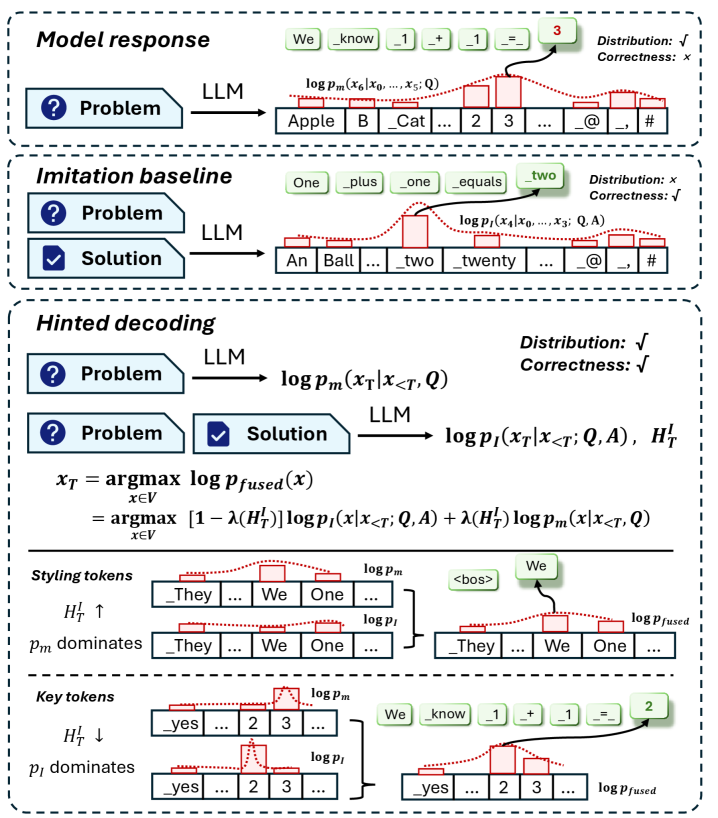
Hinted Decoding represents a novel approach to text generation, functioning as an algorithm specifically engineered to harmonize generated responses with the probability distribution inherently learned by the language model itself. Unlike traditional decoding methods that often prioritize simply the most probable next token, Hinted Decoding actively steers the generation process towards outputs that are statistically representative of the model’s internal understanding of language. This is achieved by subtly influencing the selection of tokens during generation, encouraging the model to stay ‘within’ its learned distribution rather than venturing into less probable, and potentially nonsensical, territory. The result is a system that doesn’t just produce text, but produces text demonstrably consistent with the model’s core knowledge, leading to more reliable and predictable outputs.
Large language models, while powerful, can sometimes produce unpredictable outputs due to the inherent stochasticity of text generation. Hinted Decoding addresses this challenge by actively shaping the decoding process to better reflect the probability distribution the model learned during training. Instead of solely relying on maximizing the likelihood of the next token, this technique incorporates distributional information, gently nudging the generation towards more probable and therefore more consistent responses. This approach doesn’t constrain the model, but rather guides it, fostering outputs that are not only coherent but also demonstrably more aligned with the model’s established understanding of language, ultimately increasing the reliability and trustworthiness of the generated text.
Combining Hinted Decoding with Instance-Dependent Feature Transformation (IDFT) creates a powerful synergy in addressing distributional shift – a common challenge where a model’s performance degrades when faced with data differing from its training set. IDFT dynamically adjusts the input embeddings based on the specific instance being processed, effectively bringing the input closer to the model’s familiar distribution. When coupled with Hinted Decoding, which steers the generation process toward outputs aligned with the model’s inherent probabilities, this combination provides a dual defense against drift. IDFT stabilizes the input, while Hinted Decoding ensures the output remains within the bounds of reliable generation, resulting in notably more consistent and trustworthy large language model responses even when encountering novel or out-of-distribution data.
Hinted Decoding leverages the power of Kullback-Leibler (KL) Divergence to steer large language models towards generating more predictable and reliable text. By quantifying the difference between the model’s intended probability distribution and the actual generated output, KL Divergence acts as a guiding force during decoding. This measurement allows the algorithm to penalize deviations from the model’s inherent understanding, effectively encouraging responses that align with its learned patterns. The result is a pathway to greater control over LLM outputs, diminishing the likelihood of unexpected or nonsensical generations and fostering increased trustworthiness in the model’s responses – a crucial step towards deploying these powerful systems in sensitive or critical applications.
The pursuit of robust language models, as detailed in this work, hinges on understanding distributional alignment. The paper’s exploration of distribution discrimination and its application to fine-tuning elegantly reflects a core principle of systemic design – structure dictates behavior. As Claude Shannon observed, “The most important thing in communication is to get the message across.” This resonates deeply with the article’s focus; achieving effective LLM alignment isn’t merely about scaling parameters, but about precisely shaping the distribution of generated outputs to reliably convey intended meaning. A fragile design, attempting clever shortcuts, will inevitably falter; a system grounded in clear distributional principles, however, offers a pathway to enduring performance and mitigates the risks of catastrophic forgetting.
Further Horizons
The presented work, while offering a formalization of distribution discrimination, implicitly acknowledges a persistent tension in language model training: the seductive appeal of optimizing for immediate reward versus cultivating robust, generalizable behavior. Documentation captures structure, but behavior emerges through interaction; a model perfectly aligned to the training distribution may still falter when presented with the subtly novel. The logarithmic transformation, borrowed from signal detection theory, represents an elegant attempt to modulate this sensitivity, but the choice of base, and its implications for weighting rare events, remains an area ripe for exploration.
Future investigations should address the interplay between distribution discrimination and the inherent hierarchical nature of language. Does optimizing for distributional alignment at lower levels of abstraction – syntax, morphology – necessarily translate to improved performance at higher levels – reasoning, common sense? The current framework, focused largely on fine-tuning, could be extended to encompass pre-training objectives, potentially guiding the initial learning process towards distributions more amenable to subsequent alignment.
Ultimately, the question isn’t simply how to align language models, but to what? A truly robust system will not merely mimic the patterns of its training data, but demonstrate an understanding of the underlying principles – an ability to extrapolate, to adapt, and to gracefully degrade when faced with the inevitable imperfections of the real world. This demands a shift in focus, from purely distributional metrics to a more holistic assessment of emergent cognitive abilities.
Original article: https://arxiv.org/pdf/2602.12222.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-02-15 17:13