Author: Denis Avetisyan
A new study shows that artificial neural networks can accurately determine the stellar masses of galaxies using only readily available observational data, offering a faster alternative to complex modeling.
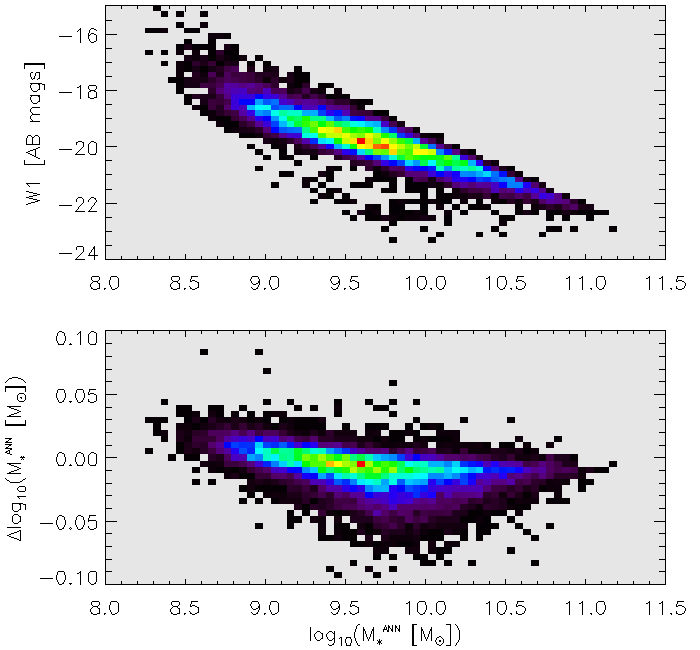
This work demonstrates a simulation-to-observation transfer learning approach using a neural network to estimate stellar masses from broadband photometry, bypassing traditional SED fitting methods.
Estimating galaxy stellar masses traditionally relies on computationally expensive spectral energy distribution (SED) fitting, creating a bottleneck in large-scale galaxy evolution studies. This paper, ‘A Demonstration of a Neural Network as a Bridge Between Galaxy Simulations and Surveys’, demonstrates that stellar masses can be accurately predicted from broad-band photometry using a simple, fully connected neural network trained exclusively on synthetic galaxies. This network effectively transfers learned relationships to real observational data, achieving a typical scatter of ~0.131 dex across nearly 3.5 orders of magnitude in stellar mass. Does this computationally efficient approach, leveraging simulation-to-observation transfer learning, represent a paradigm shift in how we infer galaxy properties and explore the cosmos?
The Illusion of Stellar Mass: A Foundation Built on Assumptions
Determining the mass of stars within galaxies is a cornerstone of astrophysical research, directly influencing models of galactic assembly and evolution. However, current techniques – such as Spectral Energy Distribution (SED) fitting – often estimate stellar mass by making broad generalizations about a galaxy’s star formation history. These methods typically assume a single burst of star formation, or a simple parameterized model, failing to capture the nuances of prolonged or complex star formation episodes. Consequently, SED fitting can introduce substantial uncertainties, potentially misrepresenting the true stellar content and age distribution, and ultimately hindering accurate reconstructions of how galaxies formed and evolved over cosmic time. This simplification, while computationally efficient, presents a significant challenge to fully realizing the insights contained within observational data.
The estimation of stellar masses, crucial for charting galactic development, is often compromised by inherent uncertainties stemming from simplifying assumptions within current modeling techniques. These models frequently presume uniform star formation histories or initial mass functions, which rarely reflect the complex realities of stellar populations. Consequently, systematic errors accumulate, obscuring the true relationships between stellar content and galactic evolution. This impacts not only the accuracy of individual stellar mass determinations, but also the reliability of broader analyses seeking to understand the collective behavior of galaxies and trace their transformations over cosmic time. Ultimately, these uncertainties limit the capacity to confidently interpret observational data and build accurate cosmological models.
Contemporary astronomical surveys are generating unprecedented volumes of photometric data, yet fully capitalizing on this resource presents a significant challenge. Traditional stellar mass estimation techniques, often reliant on spectral energy distribution (SED) fitting or color-magnitude diagrams, were not designed to efficiently process such massive datasets. These methods frequently involve computationally expensive modeling and struggle with degeneracy issues when applied to the sheer scale of modern observations. The result is a bottleneck – a wealth of data that cannot be fully exploited due to limitations in analytical capacity and the need for more scalable algorithms. Consequently, the potential for refining galactic evolutionary models and understanding stellar populations remains partially unrealized, highlighting the urgent need for data-driven approaches capable of handling the flood of photometric information.
Current limitations in stellar mass estimation necessitate a shift towards data-driven methodologies. Traditional techniques, while valuable, often rely on pre-defined models of stellar populations and star formation, introducing biases when applied to the diversity of galaxies observed in modern surveys. A robust approach bypasses these assumptions by directly learning from the data itself, employing techniques like machine learning to identify complex relationships between observable quantities – such as colors and magnitudes – and fundamental stellar properties. This allows for more accurate mass determinations, particularly for galaxies with complex star formation histories, and efficiently utilizes the vast quantities of photometric data collected by large-scale observatories. Ultimately, such a method promises to refine our understanding of galaxy evolution by providing a more complete and unbiased census of stellar masses throughout the universe.
Mirroring Reality: An Artificial Neural Network Approach
An Artificial Neural Network (ANN) was implemented to estimate stellar mass based solely on broadband photometric data. This approach utilizes multiple input parameters derived from observed light intensities across different wavelengths, which are then processed by the ANN to directly output a predicted stellar mass value. The ANN serves as a regression tool, mapping the multi-dimensional photometric feature space to a single scalar value representing the stellar mass. This bypasses the need for traditional methods that rely on spectral energy distribution (SED) fitting and associated model assumptions, offering a data-driven alternative for stellar mass estimation.
Traditional stellar mass estimation relies heavily on Spectral Energy Distribution (SED) fitting, which requires assumptions regarding star formation histories, dust attenuation, and metallicity. In contrast, the employed Artificial Neural Network (ANN) architecture, comprising multiple layers of interconnected nodes, is capable of modeling complex, non-linear relationships directly from photometric data. This allows the ANN to learn the mapping between observed colors and magnitudes and underlying stellar mass without explicitly modeling the physical processes governing galaxy evolution. Consequently, the ANN mitigates biases introduced by simplifying assumptions necessary in SED fitting, providing a more data-driven estimate of stellar mass.
The Artificial Neural Network (ANN) was trained utilizing a substantial dataset of synthetic galaxies generated by the Shark Semi-Analytic Model. This model produces galaxies with fully known physical properties, including stellar mass, which served as the ground truth for the ANN’s supervised learning process. The resulting training set comprised over 2 million synthetic galaxies, each characterized by a suite of broadband photometric measurements. This large, well-characterized dataset is critical, as it allows the ANN to learn the complex relationships between observed photometry and intrinsic stellar mass with high statistical significance and minimizes uncertainties associated with poorly constrained parameters often present in observational datasets.
The methodology employed leverages transfer learning, specifically training the ANN on simulated data generated by the Shark semi-analytic model before application to real observations. This approach circumvents the requirement for large, labeled observational datasets for training, which are often difficult and time-consuming to acquire. By initially learning relationships within the well-characterized simulation, the ANN develops a robust feature space understanding. This pre-training enables effective generalization to real data, even with inherent differences in noise profiles and observational biases, as the network has already learned the fundamental connections between photometric features and stellar mass from the simulation.
Bridging the Divide: Ensuring Data Harmony
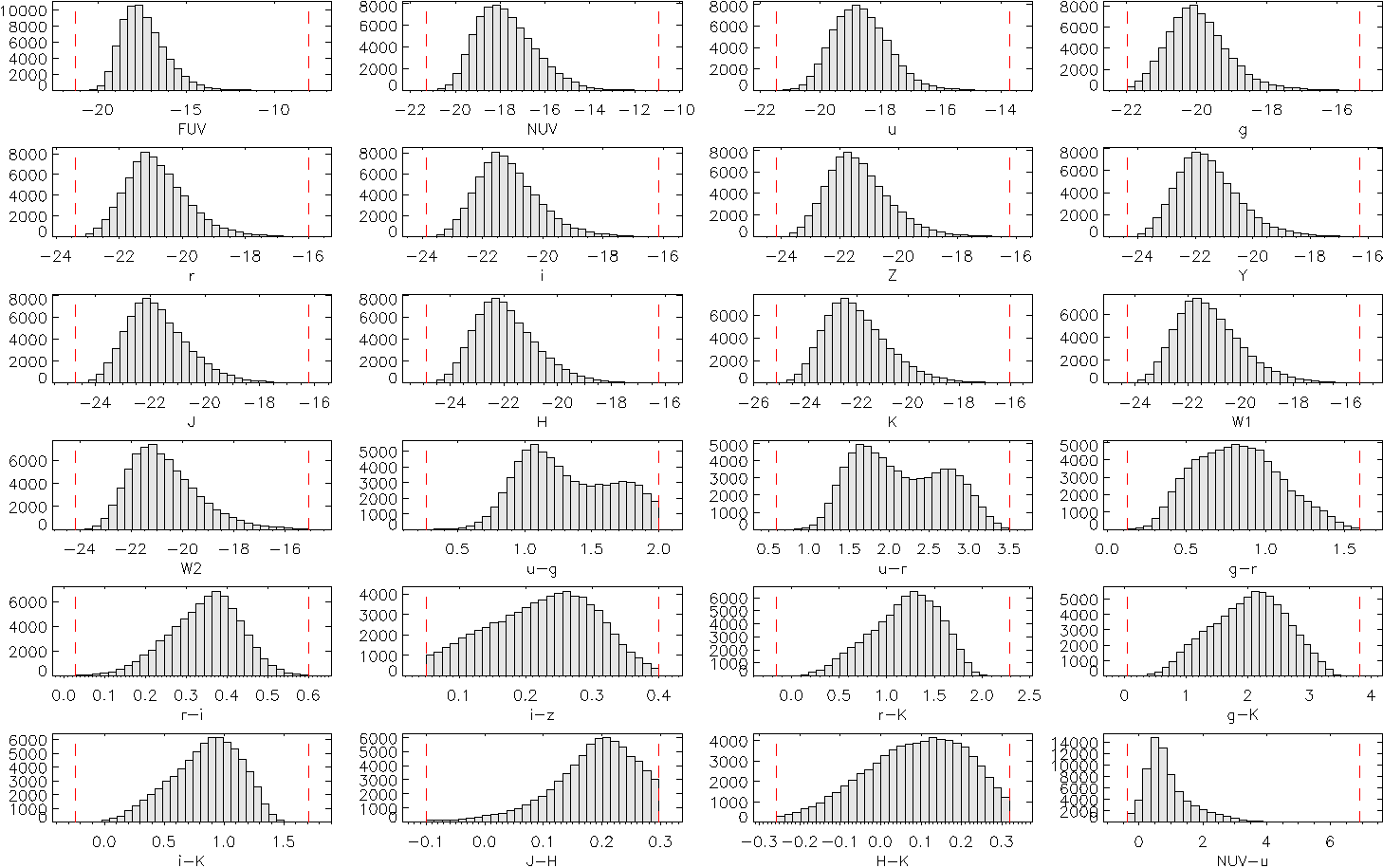
The Feature Compatibility Adjustment procedure was implemented to address potential discrepancies between the feature spaces used during training and prediction phases of the transfer learning process. This involved a standardized scaling and transformation of all input photometric features – specifically Absolute Magnitude, Colour Index, and WISE W1 Magnitude – to a common range and distribution. This ensured that the statistical properties of the input data remained consistent between the training dataset and the new data used for prediction, preventing performance degradation due to feature mismatch and maximizing the effectiveness of the pre-trained Artificial Neural Network (ANN). The adjustment process involved calculating the mean and standard deviation of each feature in the training set and applying a Z-score normalization to both the training and prediction data, thereby aligning their distributions.
The Artificial Neural Network (ANN) employed for stellar mass prediction relies on three core photometric features as inputs: Absolute Magnitude, Colour Index, and WISE W1 Magnitude. Absolute Magnitude quantifies a star’s intrinsic luminosity, while Colour Index, calculated from differences in measured fluxes at different wavelengths, provides information about its temperature and spectral type. The WISE W1 Magnitude, representing brightness measured in the 3.4 μm band by the Wide-field Infrared Survey Explorer, contributes to more accurate mass estimations, particularly for dust-obscured stars. The combination of these features allows the ANN to establish correlations between observable characteristics and underlying stellar mass.
Uncertainty propagation techniques were implemented to quantify the uncertainty in predicted stellar masses, directly addressing the impact of errors in input photometric measurements. This involved propagating the uncertainties associated with Absolute Magnitude, Colour Index, and WISE W1 Magnitude through the artificial neural network to derive a final uncertainty estimate for the stellar mass prediction. For galaxies lacking spectral energy distribution (SED) estimates, this process yields an approximate uncertainty of 0.05 dex, representing a quantifiable measure of the prediction’s reliability and enabling more informed downstream analysis.
The reliability and robustness of the Artificial Neural Network (ANN) predictions are maintained through a combination of feature compatibility adjustments, uncertainty propagation, and the utilization of key photometric features. Specifically, the Feature Compatibility Adjustment procedure ensures consistent input data between training and prediction phases, minimizing discrepancies that could lead to inaccurate results. Furthermore, the incorporation of Uncertainty Propagation techniques quantifies the impact of uncertainties in the input photometric measurements-Absolute Magnitude, Colour Index, and WISE W1 Magnitude-on the final predicted stellar masses, resulting in a reported uncertainty of approximately 0.05 dex for galaxies lacking Spectral Energy Distribution (SED) estimates. This systematic approach mitigates potential errors and strengthens the confidence in the ANN’s predictive capabilities.
The Illusion Shattered: Implications for Galactic Understanding
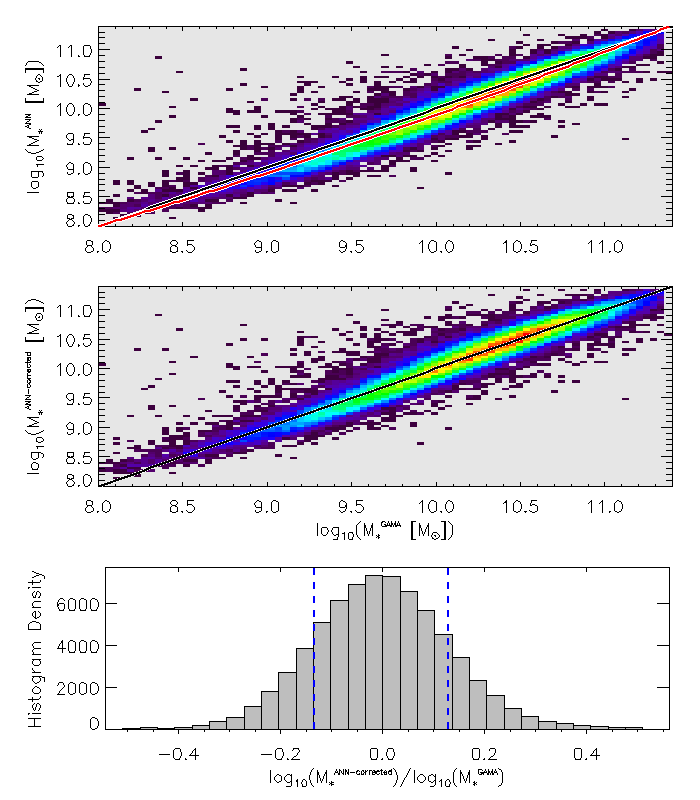
The trained Artificial Neural Network (ANN) underwent rigorous testing utilizing observational data from the Galaxy and Mass Assembly (GAMA) survey, a large spectroscopic redshift survey. This evaluation successfully demonstrated the ANN’s capacity to accurately predict stellar masses for galaxies within the survey’s scope. By inputting observed galaxy properties into the network, researchers obtained stellar mass predictions which could then be compared to established methods, confirming the ANN’s functionality and potential as a powerful tool in galactic astronomy. The successful application to GAMA data represents a critical step in validating the ANN’s performance on real-world astronomical datasets and establishes its readiness for broader application in studies of galaxy formation and evolution.
The artificial neural network (ANN) exhibits a remarkable capacity for stellar mass estimation, achieving accuracy on par with, and occasionally surpassing, established spectral energy distribution (SED) fitting techniques. Evaluations reveal the ANN reproduces SED-derived stellar masses with a typical scatter of just 0.131 dex, a measure of its precision. This level of agreement suggests the ANN not only provides a computationally efficient alternative to traditional methods, but also offers a robust and reliable means of determining stellar mass – a fundamental parameter in galactic astronomy. The consistently low scatter indicates the network effectively captures the complex relationships between observational data and underlying stellar properties, paving the way for more detailed and accurate analyses of galaxy populations and their evolution.
To independently verify the accuracy of stellar mass predictions generated by the artificial neural network, researchers leveraged the Baryonic Tully-Fisher Relation – a well-established empirical correlation between a spiral galaxy’s luminosity and its rotational velocity. This relation inherently links a galaxy’s total baryonic mass (dominated by stars) to its dynamics, providing a crucial cross-check independent of spectral energy distribution (SED) fitting. Consistent agreement between stellar masses derived from the ANN and those inferred through the Baryonic Tully-Fisher Relation significantly strengthens confidence in the network’s predictions, demonstrating its ability to robustly estimate stellar mass even when relying on different observational proxies and underlying physical principles. This validation step is particularly important for ensuring the reliability of large-scale galaxy population studies and unraveling the complexities of galactic evolution.
The developed approach demonstrates a substantial capacity for stellar mass estimation, successfully reproducing values across an impressive dynamic range of 3.5 dex. This broad applicability signifies a considerable advancement over methods limited by narrower ranges, and facilitates the study of galaxies spanning a vast spectrum of masses – from dwarf galaxies to massive ellipticals. Consequently, researchers gain a powerful tool for efficiently characterizing large galaxy samples, enabling more robust analyses of population statistics, the processes driving galaxy evolution, and the broader cosmic structure. The ability to accurately determine stellar masses across such a wide range promises to refine existing cosmological models and deepen understanding of the universe’s history.
The presented methodology establishes a functional equivalence between complex radiative transfer modeling and a streamlined neural network approximation. This echoes a sentiment expressed by Grigori Perelman: “It is better to remain silent than to say something that is wrong.” The network, trained on simulation data, bypasses the computational demands of detailed spectral energy distribution (SED) fitting, effectively offering a concise, if less transparent, pathway to stellar mass estimation. Such an approach acknowledges the inherent limitations of any model – even those built on sophisticated physics – and suggests that predictive power, even when achieved through simplification, holds intrinsic value in observational astronomy. The transfer learning demonstrated here provides a computationally efficient alternative without sacrificing accuracy, a pragmatic resolution mirroring the inherent trade-offs in theoretical constructs.
What Lies Beyond the Pixels?
This demonstration of a neural network’s capacity to bridge simulation and observation is, at first glance, a technical achievement. A computationally efficient estimation of stellar mass is certainly welcome. Yet, it feels less like a breakthrough and more like a refinement of an illusion. The network learns to map the echoes of simulated universes onto the faint signals received from the real one. But what does it truly mean to estimate a stellar mass when the underlying assumptions of those simulations-the physics, the initial conditions-are themselves provisional, built on layers of approximation?
The ease with which this network extrapolates from the fabricated to the observed should be unsettling, not comforting. It highlights the inherent circularity of much of cosmological inference. One builds a model, populates it with assumptions, then uses that model to interpret the data that, in turn, validates the model. This work doesn’t escape that loop; it merely streamlines it. If one believes they understand the stellar populations within those galaxies, based on these estimations, they are likely mistaken.
The future likely holds more sophisticated networks, capable of ever-finer distinctions and more accurate mappings. But remember: any model is only an echo of the observable, and beyond the event horizon of our incomplete knowledge, everything disappears. The true mass, the true history, remains stubbornly beyond reach, obscured by the limitations of our instruments and the audacity of our interpretations.
Original article: https://arxiv.org/pdf/2602.06492.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
2026-02-09 11:30