Author: Denis Avetisyan
A new approach harnesses the power of artificial intelligence to translate human expertise into robust, scalable anomaly detection systems for critical time series data.
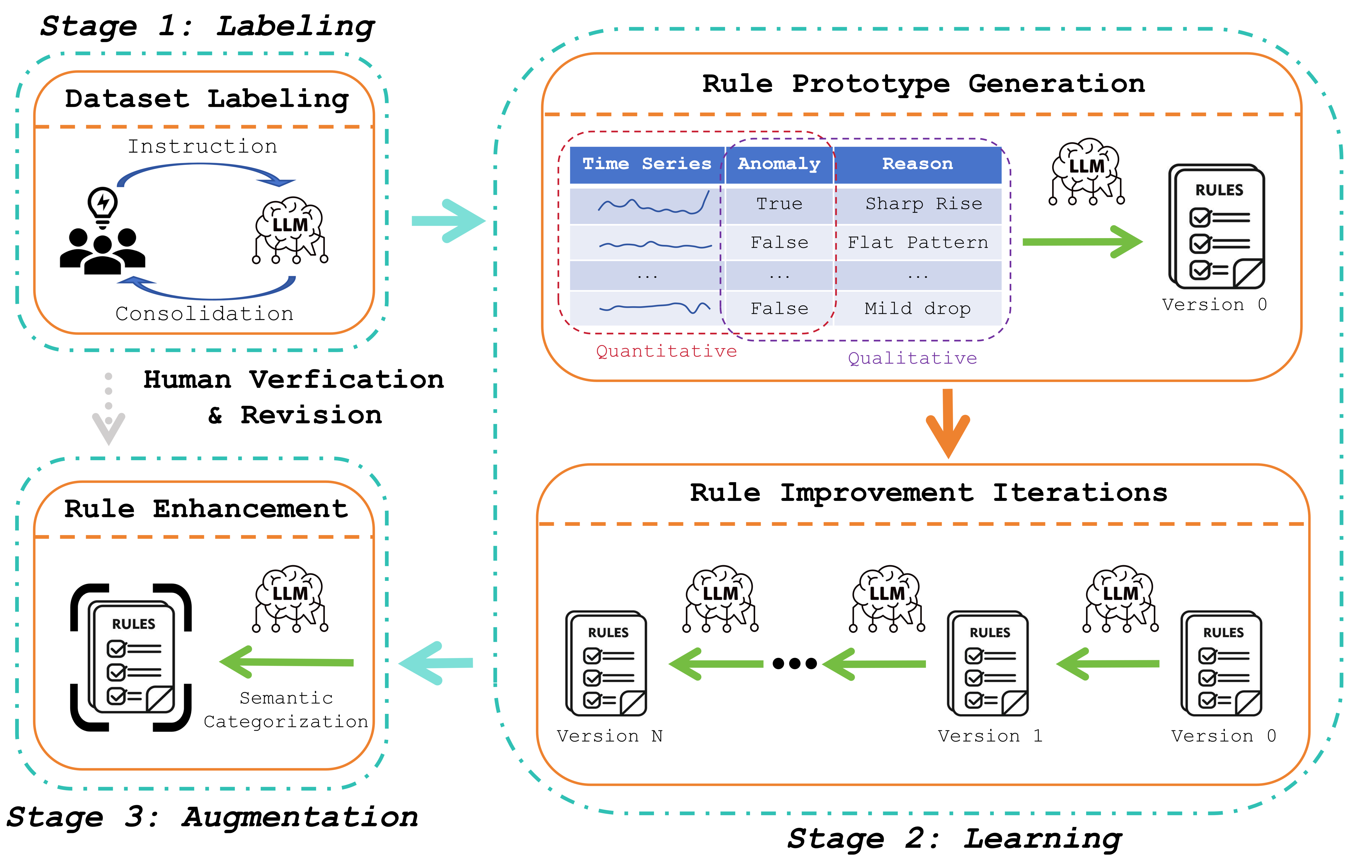
This work introduces a framework leveraging large language models to automate the creation of interpretable, logic-based rules for time series anomaly detection in supply chain management and beyond.
Effective anomaly detection in complex time series data-critical for proactive supply chain management-is often hampered by a trade-off between scalable automation and the incorporation of valuable domain expertise. This paper, ‘LLM-Assisted Logic Rule Learning: Scaling Human Expertise for Time Series Anomaly Detection’, introduces a novel framework that bridges this gap by leveraging large language models to systematically encode human knowledge into interpretable, logic-based rules for anomaly detection. Our approach demonstrably outperforms traditional unsupervised methods in both accuracy and interpretability, offering deterministic results with reduced computational cost. Could this paradigm of translating expert knowledge into explicit rules unlock new possibilities for human-AI collaboration in operational settings and beyond?
Unveiling Complexity: The Limits of Traditional Anomaly Detection
Conventional time series anomaly detection techniques, relying on static statistical thresholds or simplistic machine learning algorithms, are increasingly challenged by the sheer scale and intricate patterns within contemporary data streams. These methods often treat each data point in isolation or fail to capture the nuanced dependencies inherent in complex systems, leading to a high rate of false positives or, more critically, missed anomalies. The flood of data generated by modern operations-spanning everything from financial transactions to supply chain logistics-overwhelms these traditional approaches, diminishing their accuracy and practical utility. Consequently, businesses face increasing difficulty in proactively identifying and responding to genuine disruptions, hindering operational efficiency and potentially leading to significant financial losses. The limitations stem from an inability to adapt to evolving data distributions and the computational burden of processing massive datasets in real-time, necessitating the development of more robust and scalable solutions.
Although algorithms like Random Forest and XGBoost represent advancements in anomaly detection, their ‘black box’ nature presents significant challenges in real-world applications. These methods often achieve high accuracy, but struggle to provide clear explanations for why a particular data point is flagged as anomalous, hindering trust and effective response. Furthermore, their static models require frequent retraining to adapt to evolving data patterns within dynamic operational contexts, such as fluctuating seasonal demands or unexpected supply chain disruptions. This lack of inherent adaptability means that anomalies can go undetected, or normal variations misinterpreted, demanding constant manual intervention and limiting their scalability for complex systems managing thousands of distinct products and processes.
Amazon’s supply chain, encompassing over 10,000 distinct stock-keeping units (ASINs), presents a formidable challenge to traditional anomaly detection techniques. Existing systems, often reliant on static thresholds or comparatively simple machine learning models, struggle to discern genuine disruptions from the inherent noise of such a vast and interconnected network. The sheer volume of time-series data, coupled with the complex interdependencies between products, suppliers, and global events, overwhelms these approaches, leading to both false positives and missed critical alerts. Consequently, there is a growing need for anomaly detection systems capable of not only scaling to this magnitude but also providing explainable insights – allowing stakeholders to understand why an anomaly was flagged, rather than simply being notified of its occurrence, which is crucial for effective and timely intervention in a dynamic operational environment.
From Observation to Logic: A Framework for Clarity
LLM-Assisted Logic-Based Rule Learning is a novel framework designed to convert subject matter expert knowledge into a set of explicitly defined, interpretable rules for the purpose of anomaly detection. This process moves beyond traditional machine learning approaches by prioritizing transparency and allowing for direct human oversight of the decision-making process. The framework utilizes Large Language Models (LLMs) not as predictive engines, but as tools to formalize existing domain expertise into logical statements. These statements are then compiled into a rule-based system capable of identifying anomalous patterns within time series data. The resulting rules are readily inspectable and modifiable, offering a significant advantage in applications where understanding the reasoning behind an anomaly detection is crucial, such as in financial monitoring, industrial process control, or healthcare diagnostics.
The initial Labeling Stage utilizes Multimodal Large Language Models (LLMs) to interpret time series data and assign relevant labels. This process is augmented by Visual Time Series Representation, which converts the numerical time series into visual formats such as charts and graphs. This visual aid improves the LLM’s comprehension of patterns and anomalies within the data, enabling more accurate and contextually relevant labeling. The LLMs analyze both the numerical values and the visual representation to identify and categorize specific events or conditions indicated by the time series, forming the basis for subsequent rule learning.
The Two-Tier Consensus Mechanism addresses potential inaccuracies in labels generated by Large Language Models (LLMs) through a multi-stage validation process. Initially, multiple LLMs independently label each time series data point. Discrepancies are identified, and a weighted majority vote determines a preliminary consensus label. Subsequently, a secondary tier, consisting of expert-defined rules or a separate, highly-trained model, reviews labels where the initial LLM consensus falls below a defined confidence threshold. This secondary review either confirms the consensus label or overrides it, ensuring a high degree of reliability and consistency in the final labeled dataset used for anomaly detection model training. The mechanism quantifies consensus using confidence scores, allowing for tunable sensitivity and control over label quality.
Refining Insight: Iterative Rule Improvement
The Learning Stage employs Iterative Rule Improvement to enhance the precision of logic-based rules. This process involves continuous evaluation of rule performance against observed data and behavioral patterns. Following each evaluation cycle, rules are systematically refined; adjustments are made to improve accuracy, reduce false positives, and minimize false negatives. This iterative approach allows the framework to adapt to the nuances of the data and optimize rule sets over time, leading to improved performance without requiring retraining of the underlying Large Language Model (LLM). The system monitors key metrics during each iteration to quantify improvements and guide the refinement process.
The framework’s integration of business context involves supplying Large Language Models (LLMs) with domain-specific information regarding the data’s origin, definitions, and practical implications. This is achieved through the incorporation of metadata, data dictionaries, and pre-defined business rules as part of the LLM’s input. Providing this contextual awareness allows the LLM to interpret data accurately, disambiguate potentially ambiguous values, and apply relevant business logic during analysis, thereby improving the reliability and interpretability of its outputs beyond what is achievable with general-purpose LLMs or models lacking such domain expertise.
Comparative evaluations demonstrate the framework’s superior performance against several established anomaly detection methods. Specifically, the framework consistently achieves higher accuracy rates than VAE-LSTM, Anomaly Transformer, iForest, and direct Large Language Models (LLMs) when tested on comparable datasets. These results were determined through standardized metrics, including precision, recall, and F1-score, across multiple experimental runs. The observed improvements indicate the effectiveness of the iterative rule refinement process and the integration of domain-specific business context in enhancing anomaly detection capabilities.
Beyond Prediction: Towards Resilient Supply Chains
Current anomaly detection systems in supply chains often struggle with the complexity and nuance of real-world disruptions. This research presents a framework that moves beyond simple identification of unusual events by integrating the strengths of large language models (LLMs) and logic-based rules. LLMs excel at discerning patterns and contextual understanding from vast datasets – including unstructured text like news reports or supplier communications – to anticipate potential issues. However, LLMs can lack the definitive precision needed for reliable decision-making. The framework addresses this by translating the LLM’s insights into formal, logical rules, providing a clear and verifiable basis for flagging anomalies. This hybrid approach not only improves the accuracy of detection but also offers a substantial leap forward in interpretability, allowing stakeholders to understand why an event is flagged as anomalous, rather than simply that it is unusual – a crucial distinction for proactive resilience.
A key benefit of this novel framework lies in its ability to translate complex supply chain disruptions into easily understandable rules. Rather than simply flagging anomalies, the system generates logical statements – such as “If demand for component X exceeds Y and supplier Z’s lead time increases by more than A days, then anticipate a production delay” – which enable rapid root cause analysis. This interpretability drastically reduces the time required to diagnose issues and implement corrective actions; teams can move beyond identifying that a problem exists to understanding why it’s occurring and precisely how to mitigate its impact. Consequently, operational efficiency is significantly improved, allowing businesses to proactively address vulnerabilities and maintain a more resilient supply chain.
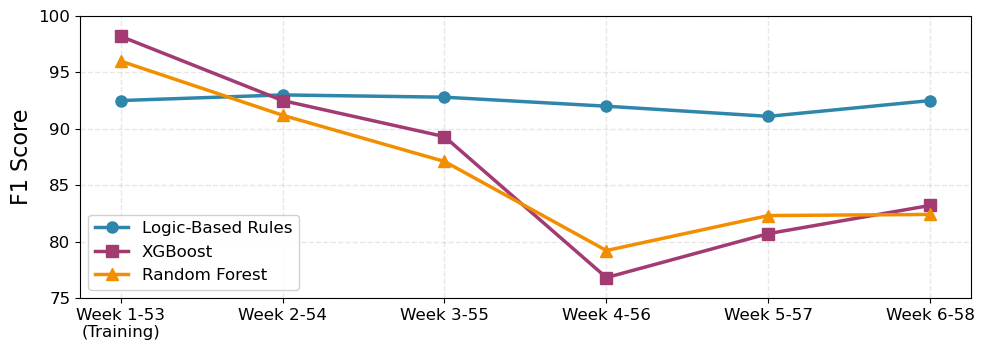
Recent evaluations demonstrate the enhanced stability of this novel supply chain framework when confronted with real-world volatility. Unlike supervised learning algorithms-specifically XGBoost and Random Forest-which exhibited diminished performance during a week characterized by holiday-driven demand surges, the framework maintained consistent accuracy. This resilience stems from its hybrid approach, integrating the analytical capabilities of large language models with the precision of logic-based rules, enabling it to effectively navigate unpredictable fluctuations without the performance decay observed in traditional methods (as detailed in Fig. 3). The framework’s ability to sustain performance under stress underscores its potential for building genuinely proactive and robust supply chain operations.
The pursuit of scalable anomaly detection, as detailed in this work, echoes a sentiment held by the mathematician Paul Erdős: “A mathematician knows a lot of things, but a physicist knows a few.” This framework, translating human expertise into explicit logic rules, demonstrates a similar focus – distilling complex domain knowledge into fundamental, actionable components. Much like a physicist reducing a problem to its core principles, the system prioritizes interpretability and scalability, avoiding the ‘black box’ nature of many modern machine learning models. The emphasis on logic-based rules isn’t merely a technical choice; it’s a commitment to transparency, allowing for verification and refinement of the anomaly detection process – a pursuit of elegance through simplicity.
The Road Ahead
The presented framework, while demonstrating a capacity to formalize expertise for anomaly detection, merely addresses the symptom, not the disease. The enduring problem remains the inherent fragility of relying on explicitly defined rules in dynamic systems. Supply chains, by their nature, are perpetually shifting, rendering any static logic inevitably incomplete. Future work must confront this directly, moving beyond rule learning towards rule adaptation – a system capable of refining its own logic in response to observed deviations.
A pertinent limitation lies in the dependence on initial human input. The framework excels at scaling existing expertise, but it offers no independent discovery. The next logical step is to explore methods for the large language model to proactively propose rules, effectively acting as an inductive reasoning engine. This necessitates a robust mechanism for evaluating the validity of such proposals – a task currently requiring human oversight, thus negating the potential for true automation.
Ultimately, the value proposition hinges not on achieving perfect anomaly detection, but on minimizing the cognitive burden of maintaining a functional system. Simplicity, after all, is not a destination, but a continuous process of subtraction. The true measure of success will be the degree to which this framework allows for the removal of human intervention, not the addition of complex algorithms.
Original article: https://arxiv.org/pdf/2601.19255.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Transformers Under the Microscope: What Graph Neural Networks Reveal
2026-01-28 18:30