Author: Denis Avetisyan
New research reveals that the reliability of counterfactual explanations – a key tool for understanding AI decisions – is surprisingly vulnerable to the inherent uncertainties within machine learning models.
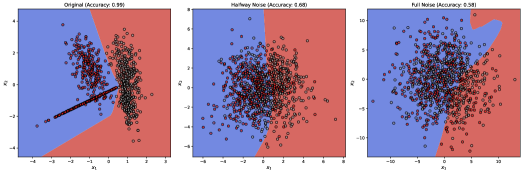
This study demonstrates that both aleatoric and epistemic uncertainty significantly impact the robustness of counterfactual explanations, with no single approach consistently providing the most reliable results.
Despite the increasing reliance on machine learning for critical decision-making, the stability of explanations for these models remains a significant concern. This research, ‘The Impact of Machine Learning Uncertainty on the Robustness of Counterfactual Explanations’, investigates how both inherent data noise (\text{aleatoric uncertainty}) and model limitations (\text{epistemic uncertainty}) affect the reliability of counterfactual explanations – commonly used methods for interpreting model predictions. Our findings demonstrate that counterfactual explanations are highly sensitive to even small reductions in model accuracy, leading to substantial variations in generated explanations across instances and algorithms. This raises a critical question: how can we develop explanation methods that are robust to the uncertainties inherent in real-world machine learning deployments, particularly in high-stakes domains?
Beyond Predictive Accuracy: The Fragility of Opaque Models
Many machine learning systems are engineered with a primary emphasis on achieving high predictive accuracy, often at the expense of understanding why those predictions are made and ensuring consistent performance under varied conditions. This prioritization can lead to models that, while appearing successful based on overall metrics, are surprisingly fragile and lack the capacity to generalize effectively. The pursuit of sheer accuracy frequently overshadows crucial considerations such as explainability – the ability to interpret the model’s reasoning – and robustness, which refers to its resilience against subtle changes in input data or real-world noise. Consequently, a model might perform well on a carefully curated dataset but fail spectacularly when confronted with even minor deviations from the training distribution, highlighting a critical disconnect between benchmark performance and genuine reliability.
A singular focus on overall model accuracy can be profoundly misleading when applied to complex datasets like those concerning credit risk or income prediction – the ‘German Credit Dataset’, ‘Adult Income Dataset’, and ‘Give Me Some Credit Dataset’ being prime examples. Recent investigations demonstrate that even minor alterations to input data – seemingly insignificant perturbations – can trigger disproportionately large shifts in the explanations a model provides for its decisions. Specifically, studies have revealed that a less than 5% reduction in a model’s overall accuracy can coincide with a greater than 20% increase in ‘counterfactual explanation distance’ – the degree to which the model’s reasoning changes when presented with a slightly modified scenario. This disconnect highlights a critical vulnerability: a model might maintain acceptable performance metrics while simultaneously offering increasingly unreliable or inconsistent justifications, raising serious concerns about its trustworthiness and potential for biased outcomes in real-world applications.
Machine learning models often operate under the assumption of perfect information, yet real-world data is inherently noisy and incomplete. This oversight manifests as two primary forms of uncertainty: aleatoric and epistemic. Aleatoric uncertainty arises from the inherent randomness within the data itself – measurement errors, or the natural variability of the phenomenon being modeled – and cannot be reduced even with more data. Epistemic uncertainty, conversely, stems from a lack of knowledge due to limited training data; the model is essentially unsure because it hasn’t ‘seen’ enough examples. Ignoring these uncertainties can lead to overconfident, yet brittle, predictions, particularly in scenarios differing from the training distribution. A robust approach necessitates acknowledging and quantifying both types of uncertainty to provide more reliable and trustworthy predictions, moving beyond simple accuracy metrics and towards a more nuanced understanding of model limitations.
The Rashomon Effect: Multiplicity of Plausible Explanations
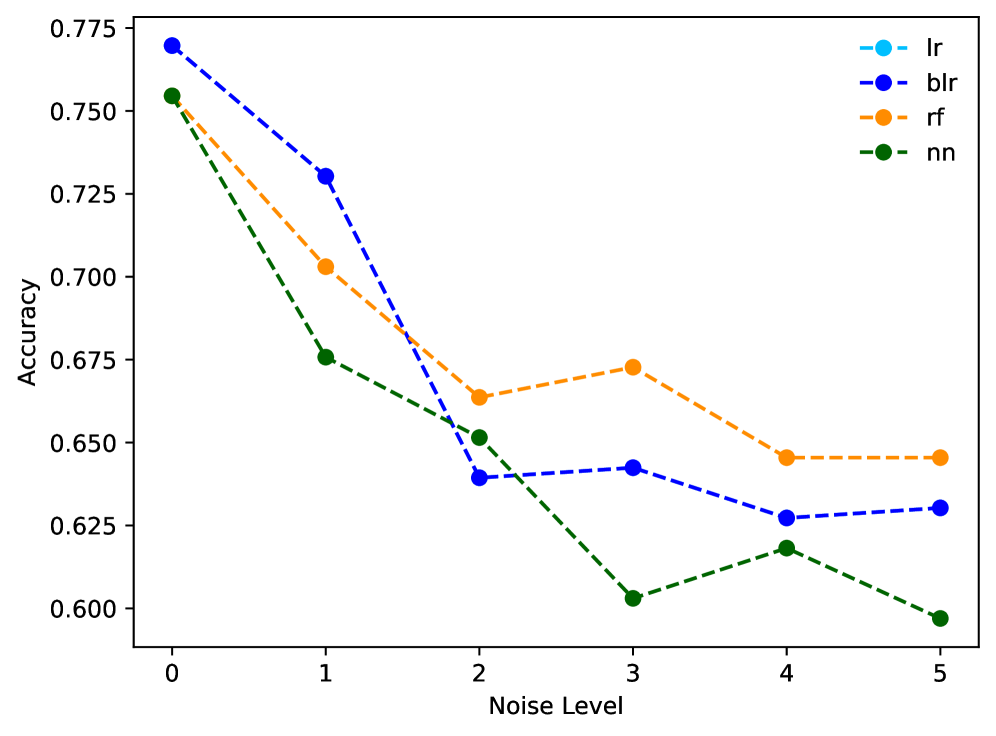
The Rashomon Effect, as observed in machine learning, describes the existence of multiple models that can accurately fit a given dataset, yet produce differing explanations for their predictions. This isn’t a flaw in the modeling process, but a consequence of the inherent limitations of inferring causality from observational data. Essentially, several combinations of parameters can yield equally low error rates, leading to diverse interpretations of the same data. The phenomenon arises because a single dataset rarely contains sufficient information to uniquely determine the ‘true’ underlying relationship, allowing for multiple plausible, and statistically valid, models to coexist. This implies that model selection isn’t simply about finding the ‘correct’ model, but rather choosing one that aligns with specific priorities or constraints, acknowledging that alternative explanations are also supported by the data.
The concept of ‘Diversity’ serves as a quantifiable metric for the Rashomon Effect, demonstrating that multiple plausible explanations can be generated from a single dataset. Our research indicates substantial differences in the robustness of these explanations when subjected to increasing levels of noise; statistical analysis revealed p-values less than 0.001, signifying statistically significant variations in performance across different explanation methods. This suggests that not all generated explanations are equally resilient to data perturbations, and the choice of method impacts the reliability of the resulting interpretations.
The ability to generate and understand multiple plausible explanations is a critical component of building trustworthy and responsible artificial intelligence systems, especially in high-stakes applications. In areas like credit risk assessment, where decisions directly impact individuals’ financial well-being, transparency regarding the rationale behind those decisions is paramount. Providing a range of possible explanations, rather than a single, opaque output, allows stakeholders to evaluate the model’s reasoning, identify potential biases, and ensure fairness. This approach facilitates auditing, promotes accountability, and ultimately increases confidence in the AI system’s reliability and ethical considerations, moving beyond simply achieving predictive accuracy.
Counterfactual Plausibility: Proximity to Empirical Reality
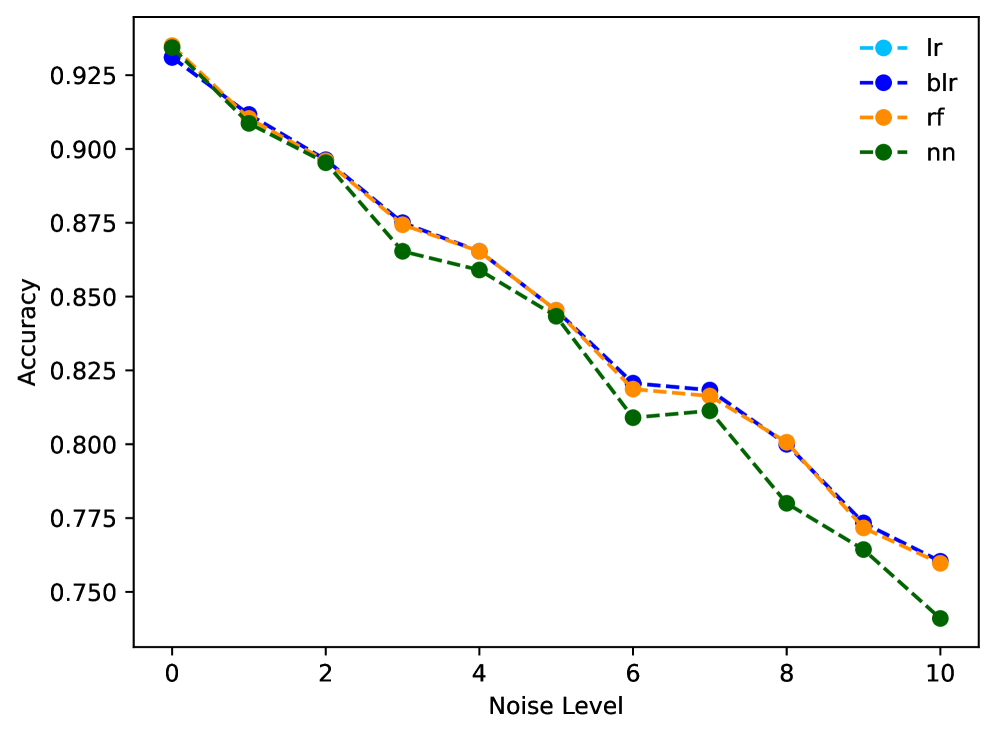
Assessing the proximity of a counterfactual example to the original data instance is a critical step in evaluating the usefulness of that counterfactual. Counterfactuals that are distant from the original data, while technically valid solutions to the ‘what-if’ query, are less plausible and therefore less likely to be actionable or relevant in a real-world context. A close counterfactual provides a more nuanced and trustworthy explanation for a model’s prediction, as it represents a minimal change to the input features required to alter the outcome. This proximity measurement informs the practical utility of counterfactual explanations, enabling users to understand how small, realistic adjustments to inputs would affect predictions, and facilitating informed decision-making based on model behavior.
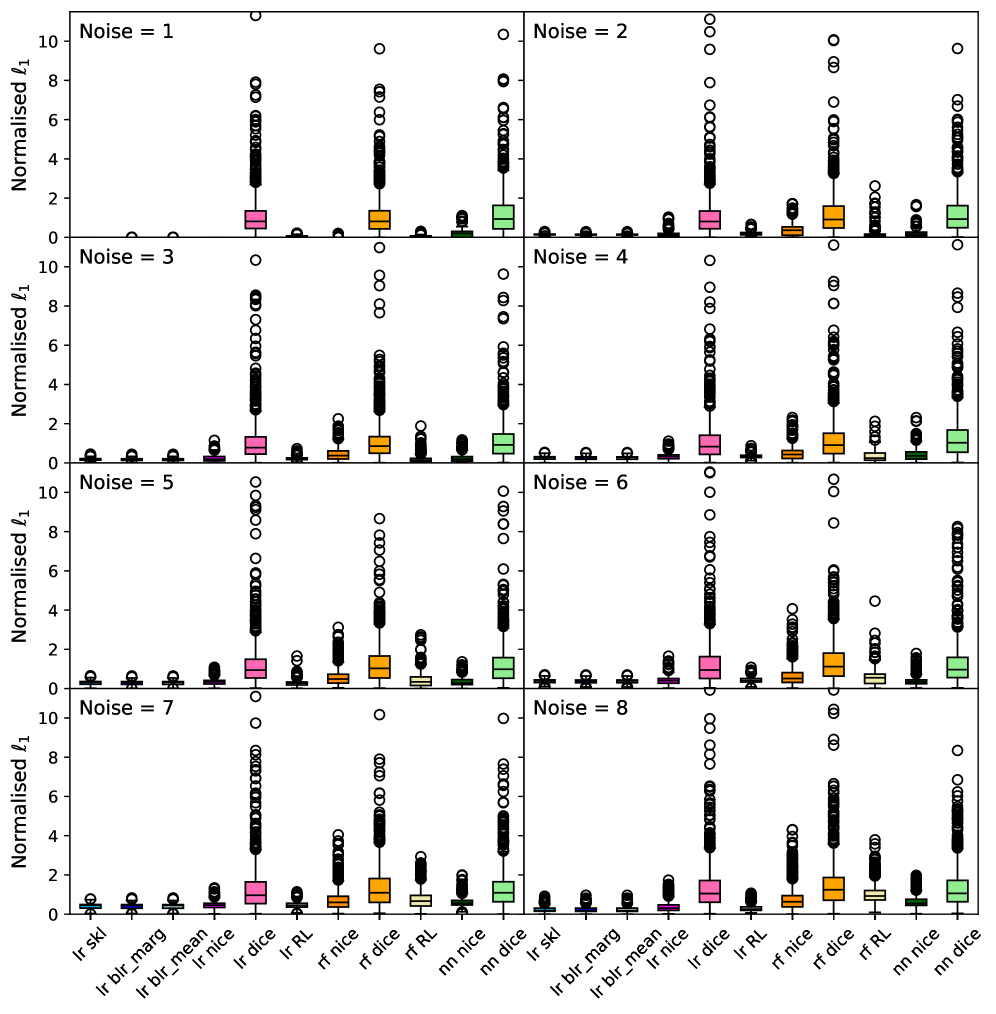
The ℓ_1 norm, also known as Manhattan distance, calculates the sum of the absolute differences between the dimensions of two data points, offering a more appropriate distance metric for categorical data than Euclidean distance. Euclidean distance assumes continuous, measurable intervals between categories, which is often inaccurate. The ℓ_1 norm, however, treats each categorical feature as a discrete dimension, summing the changes in feature values. This approach avoids the artificial ordering implied by Euclidean distance and is less sensitive to irrelevant variations in feature representation, providing a more meaningful assessment of proximity when dealing with nominal or ordinal categorical variables. Its robustness stems from its ability to handle non-continuous data without requiring arbitrary numerical assignments to categories.
Data polytopes offer a geometric approach to quantifying the distance between counterfactual examples and the original data, particularly for categorical features. A data polytope is constructed by defining a multi-dimensional space where each dimension represents a categorical feature, and each data point corresponds to a specific combination of feature values. The polytope’s vertices represent the observed combinations in the dataset, and its boundaries define the region of plausible data. Counterfactual distance is then calculated based on the minimum distance – using metrics like the L_1 norm – from the counterfactual example to the surface of this polytope, effectively measuring how much the counterfactual deviates from the observed data distribution. This geometric representation allows for a more nuanced assessment of closeness than traditional Euclidean distance, which is less meaningful for discrete categorical variables.
Evaluation of counterfactual explanation (CE) metrics benefits from the use of synthetic data to assess robustness to noise. Our analysis demonstrates that CE completeness – the proportion of valid counterfactuals identified – experiences a significant decline for certain methods when subjected to increased data noise. Specifically, CE completeness consistently falls below 10% for these methods, indicating an instability in their ability to reliably identify plausible counterfactuals under realistic conditions. This suggests that metrics exhibiting higher stability are crucial for practical application, as they maintain performance even with imperfect or noisy input data.
Beyond Accuracy: Towards Robust and Interpretable Intelligence
The prevailing emphasis on achieving ever-higher levels of model accuracy is increasingly recognized as insufficient for deploying reliable artificial intelligence. A fundamental shift is underway, prioritizing instead the comprehension and mitigation of inherent uncertainties within these systems. These uncertainties manifest in two primary forms: aleatoric, representing the irreducible randomness in the data itself, and epistemic, stemming from the model’s lack of knowledge. Ignoring these uncertainties can lead to overconfident, yet fragile, predictions, particularly when encountering data outside the training distribution. Therefore, modern AI development focuses not simply on what a model predicts, but how confident it is in those predictions, and crucially, what it doesn’t know. Quantifying and addressing both aleatoric and epistemic uncertainty is paramount for building AI systems that are not only performant but also robust, trustworthy, and capable of operating safely in real-world scenarios.
The concept of the ‘Rashomon Effect’ – where multiple, equally valid explanations can exist for the same event – is increasingly relevant to artificial intelligence systems, particularly as they are deployed in high-stakes decision-making contexts. Recognizing that a single ‘correct’ explanation is often unattainable, researchers are now focused on quantifying the diversity of plausible explanations generated by AI models. This isn’t simply about providing more answers, but about assessing the range of perspectives the model considers, and crucially, understanding how sensitive those explanations are to slight changes in input. By measuring this explanatory diversity, developers can move towards more transparent and accountable AI, enabling users to evaluate the robustness of a decision and identify potential biases or blind spots inherent in the model’s reasoning process. A greater understanding of explanatory diversity fosters trust and allows for more informed oversight of complex AI systems.
The pursuit of reliable artificial intelligence increasingly centers on understanding why a model makes a specific decision, not just that it arrives at the correct answer. A key approach involves generating counterfactual explanations – subtly altered inputs that would have yielded a different outcome – and ensuring these alterations are plausible. Researchers are quantifying this plausibility using metrics like ‘Proximity,’ which measures how similar the counterfactual input is to the original, and the \ell_1 Norm, which assesses the sparsity of the changes. By prioritizing counterfactuals that are close to the original input, models demonstrate greater robustness – meaning they are less susceptible to small, adversarial perturbations – and build user trust. This focus on plausible “what if” scenarios moves beyond simply achieving high accuracy, fostering AI systems that are interpretable, reliable, and ultimately, more trustworthy in real-world applications.
The conventional focus on minimizing both false positives and false negatives in artificial intelligence is complicated by the inherent uncertainties within models and the methods used to explain their decisions. Recent research reveals that even seemingly straightforward techniques, such as generating counterfactual explanations – identifying minimal changes to input data that would alter a model’s prediction – exhibit a surprising degree of instability. Studies demonstrate that different methods for constructing these proximity-based counterfactuals often yield significantly different results, meaning the “closest” change to avoid a false positive or negative is not consistently defined. This lack of robustness raises concerns about the reliability of explanations used for accountability and trust, suggesting that simply reducing error rates isn’t sufficient; a deeper understanding of why a model makes a decision, and the stability of that reasoning, is crucial for building truly dependable AI systems.
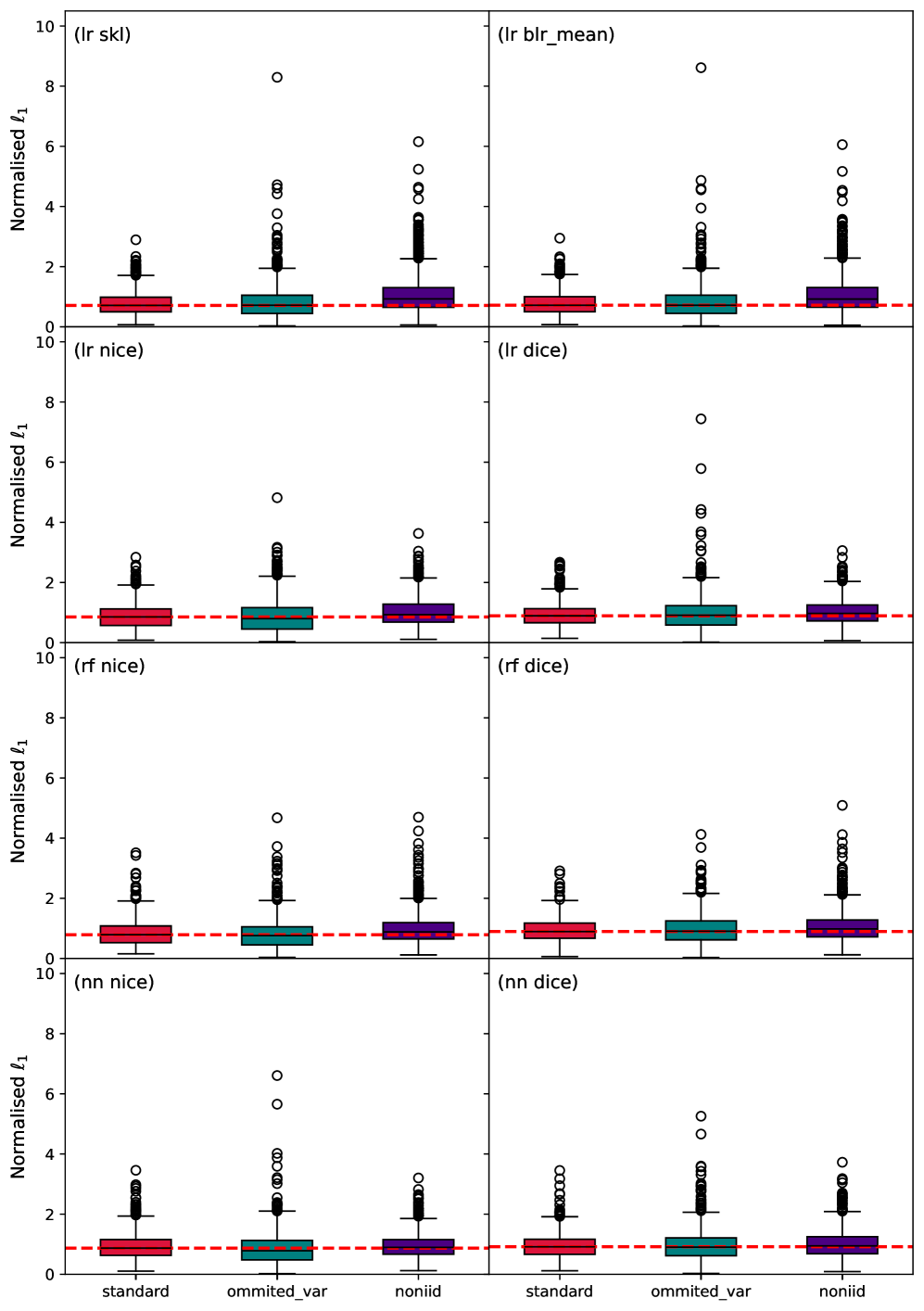
The study meticulously highlights a critical, often overlooked, aspect of explainable AI: the inherent uncertainty within machine learning models directly impacts the reliability of counterfactual explanations. This research doesn’t simply offer a ‘solution’ but rather a rigorous analysis of how these uncertainties-both aleatoric and epistemic-manifest in the explanations generated. As Alan Turing observed, “Sometimes people who are unhappy tend to look at the world as if there is nothing else.” This sentiment resonates with the findings; a model riddled with uncertainty, like an unhappy observer, presents a distorted view, rendering counterfactuals less trustworthy and potentially misleading. The pursuit of robust XAI, therefore, demands acknowledging and quantifying these uncertainties, rather than seeking a singular, perfect explanation.
The Road Ahead
The demonstrated sensitivity of counterfactual explanations to both aleatoric and epistemic uncertainty presents a fundamental challenge. The pursuit of ‘explainable AI’ often prioritizes superficial interpretability over mathematical rigor. This work subtly underscores a disquieting truth: an explanation built upon a shaky foundation – a model riddled with uncertainty – is, itself, suspect. The absence of a universally robust combination of model and explanation method is not merely a practical inconvenience; it is a symptom of a deeper conceptual flaw.
Future research must move beyond empirical evaluations and embrace formal verification. Proving the stability of a counterfactual – demonstrating its resilience to minor perturbations in the model or input space – should become paramount. The current reliance on proximity-based explanations, while intuitively appealing, invites instability. A truly elegant solution will likely necessitate a re-evaluation of these heuristics, favoring methods grounded in provable invariants.
Furthermore, the influence of data drift remains largely unexplored. The assumption of a static uncertainty landscape is demonstrably false. The development of adaptive explanation methods – those that can dynamically adjust to evolving model uncertainty – represents a necessary, if difficult, step towards genuinely trustworthy AI. The field should resist the temptation to simply accumulate ‘fixes’; instead, it should strive for a minimalist, mathematically sound foundation.
Original article: https://arxiv.org/pdf/2602.00063.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Trading Crypto with AI: A New Approach to Portfolio Management
- 15 Films That Were Shot Entirely on Phones
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
2026-02-03 19:14