Author: Denis Avetisyan
Researchers have developed a novel adversarial imitation learning framework to refine flow matching models, offering a compelling alternative to reinforcement learning-based approaches.
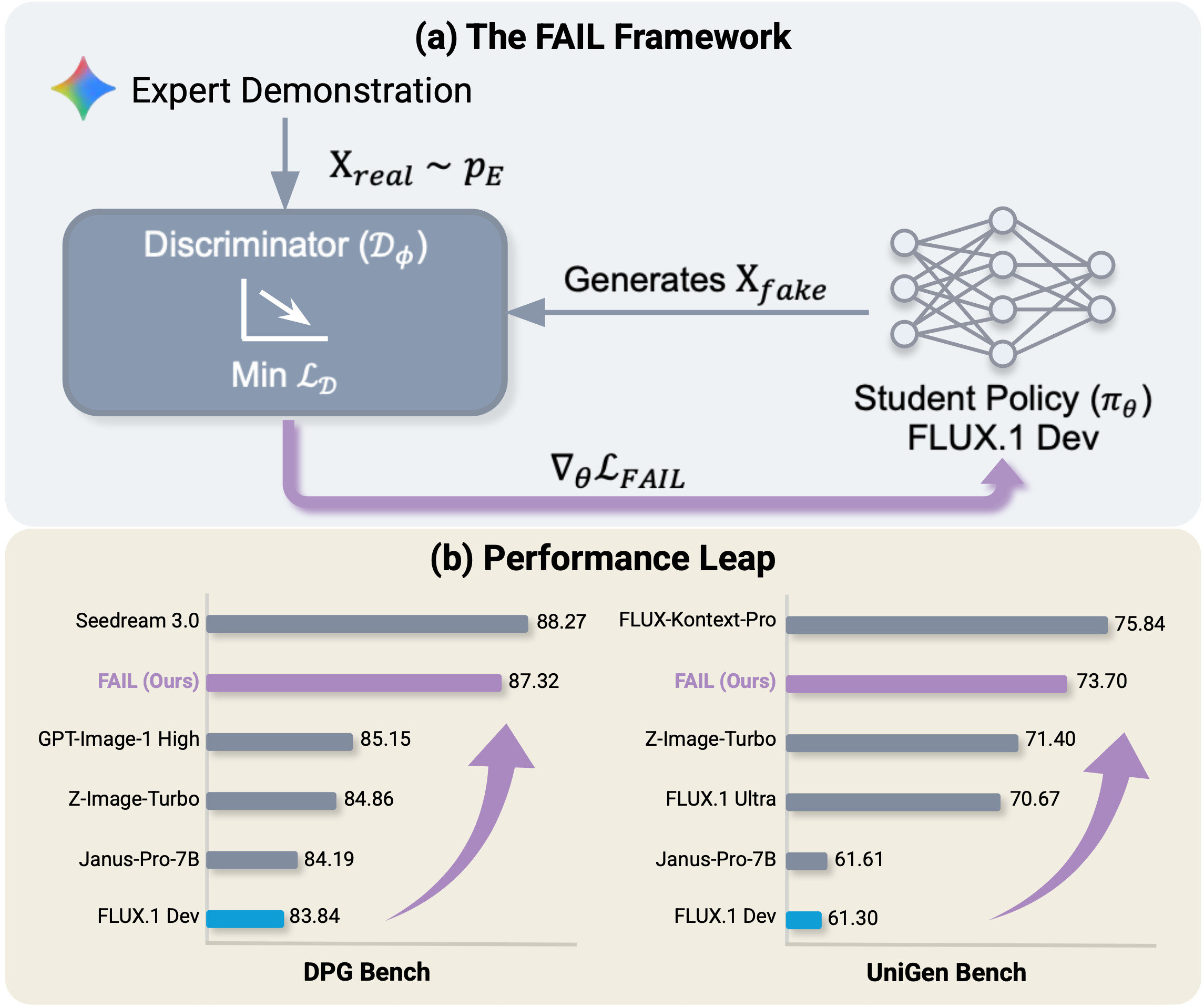
This work introduces FAIL, a post-training alignment method that leverages adversarial learning to improve the performance and stability of flow matching and diffusion generative models.
While aligning generative models with desired behaviors typically relies on costly preference data or reward modeling, this work introduces ‘FAIL: Flow Matching Adversarial Imitation Learning for Image Generation’ – a novel framework that leverages adversarial training to directly minimize the divergence between a model’s outputs and expert demonstrations. FAIL achieves competitive performance on image generation tasks by post-training flow matching models without requiring explicit rewards or pairwise comparisons, offering two algorithmic variations for different computational constraints. Notably, fine-tuning with only 13,000 demonstrations yields strong results on both prompt following and aesthetic benchmarks, and the framework extends beyond continuous image spaces to discrete data and serves as a regularizer against reward hacking. Could this approach unlock more stable and efficient alignment strategies for a broader range of generative models and applications?
The Illusion of Alignment: When Models Mimic, But Don’t Understand
Despite achieving state-of-the-art performance on standardized generative benchmarks such as UniGen-Bench and DPG-Bench, models like FLUX frequently exhibit a disconnect between their capabilities and human expectations. These systems, while proficient at mimicking patterns within training data, often struggle to consistently generate outputs that are genuinely preferred by humans – exhibiting logical inconsistencies, stylistic awkwardness, or simply failing to capture nuanced intent. This misalignment isn’t necessarily a matter of factual inaccuracy, but rather a failure to prioritize qualities like coherence, relevance, and aesthetic appeal, highlighting a critical gap between algorithmic success and genuine usability. The issue suggests that excelling on automated metrics doesn’t guarantee outputs will resonate with, or even make sense to, a human audience, underscoring the complexities of capturing subjective preferences within a machine learning framework.
Despite advances in training methodologies, generative models frequently exhibit limitations when confronted with nuanced or multifaceted requests. While techniques like Supervised Fine-Tuning and Preference Optimization demonstrably improve performance on standardized benchmarks, these approaches often prove insufficient in complex, real-world scenarios. The core issue isn’t a lack of learning capacity, but rather a difficulty in translating abstract human intentions into concrete model behavior. These optimization strategies frequently rely on relatively simple reward signals, failing to capture the subtle reasoning and contextual understanding that underpin expert-level performance. Consequently, even finely-tuned models can produce outputs that, while technically correct, miss the mark in terms of creativity, relevance, or overall quality, highlighting a fundamental challenge in effectively steering these increasingly powerful systems.
Current approaches to aligning generative models often rely on relatively simplistic preference signals – indications of whether a generated output is generally ‘good’ or ‘bad’. However, true robustness in alignment demands a shift towards more nuanced techniques that prioritize the emulation of expert behavior. This involves moving beyond binary judgments and instead focusing on the intricate reasoning and decision-making processes demonstrated by human experts in a given domain. By learning how an expert arrives at a solution, rather than simply what the solution is, generative models can develop a deeper understanding of the underlying task and produce outputs that are not only preferred but also demonstrably skillful and reliable – effectively bridging the gap between benchmark performance and real-world applicability. This necessitates the development of novel learning paradigms capable of capturing and replicating the subtleties of expert cognition.
Beyond Simple Mimicry: The Ghost in the Machine
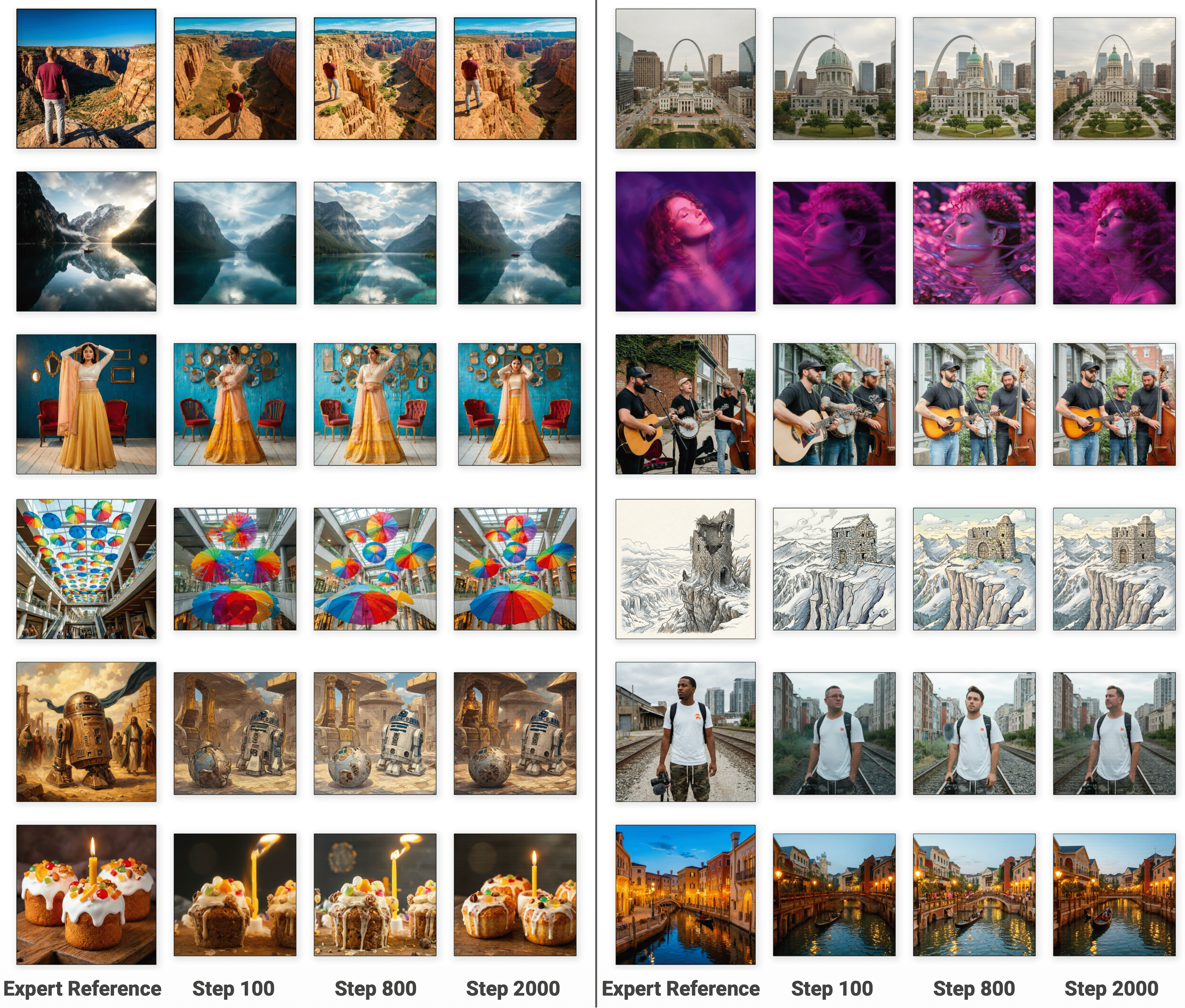
Simple Behavioral Cloning, while straightforward to implement, frequently fails to fully replicate expert behavior due to its reliance on supervised learning from a limited dataset of demonstrations. This approach attempts to directly map states to actions, neglecting the underlying intent or reasoning behind those actions. Consequently, the learned policy often exhibits a distribution mismatch – meaning the states encountered during deployment differ significantly from those seen during training. This discrepancy arises because the cloned policy tends to be overly confident in its predictions for out-of-distribution states, leading to compounding errors and suboptimal performance, particularly in complex or unpredictable environments. The model struggles to generalize beyond the specific examples provided, lacking the robustness necessary for real-world application.
Adversarial Imitation Learning (AIL) addresses limitations of behavioral cloning by formulating the imitation problem as a two-player game. In AIL, a generator network attempts to produce actions or trajectories that mimic expert demonstrations, while a discriminator network learns to distinguish between the generator’s outputs and the true expert data. This adversarial process incentivizes the generator to produce increasingly realistic outputs, effectively bridging the gap caused by distribution mismatch. The discriminator provides a learned reward signal, guiding the generator’s learning without requiring explicit reward engineering, and pushing the generated data closer to the expert distribution. This iterative process of competition and refinement leads to policies that more closely align with expert behavior than those achieved through direct behavioral cloning.
Adversarial imitation learning fundamentally depends on the performance of its discriminator component, which evaluates the fidelity of generated samples relative to expert demonstrations. Current implementations frequently utilize Vision-Language Models (VLMs) to assess both visual and textual aspects of the generated behavior, allowing for more complex evaluation criteria than purely visual comparisons. Alternatively, Visual Foundation Models (VFMs) provide strong visual feature extraction capabilities, and Flow Matching (FM) backbones can define a probability distribution over the expert data, enabling the discriminator to quantify the likelihood of generated states. The robustness of this discriminator is critical; inaccuracies in its assessment directly impact the generator’s ability to learn an effective policy and avoid distribution shift.
FAIL: Forcing Alignment Through Gradient Estimation
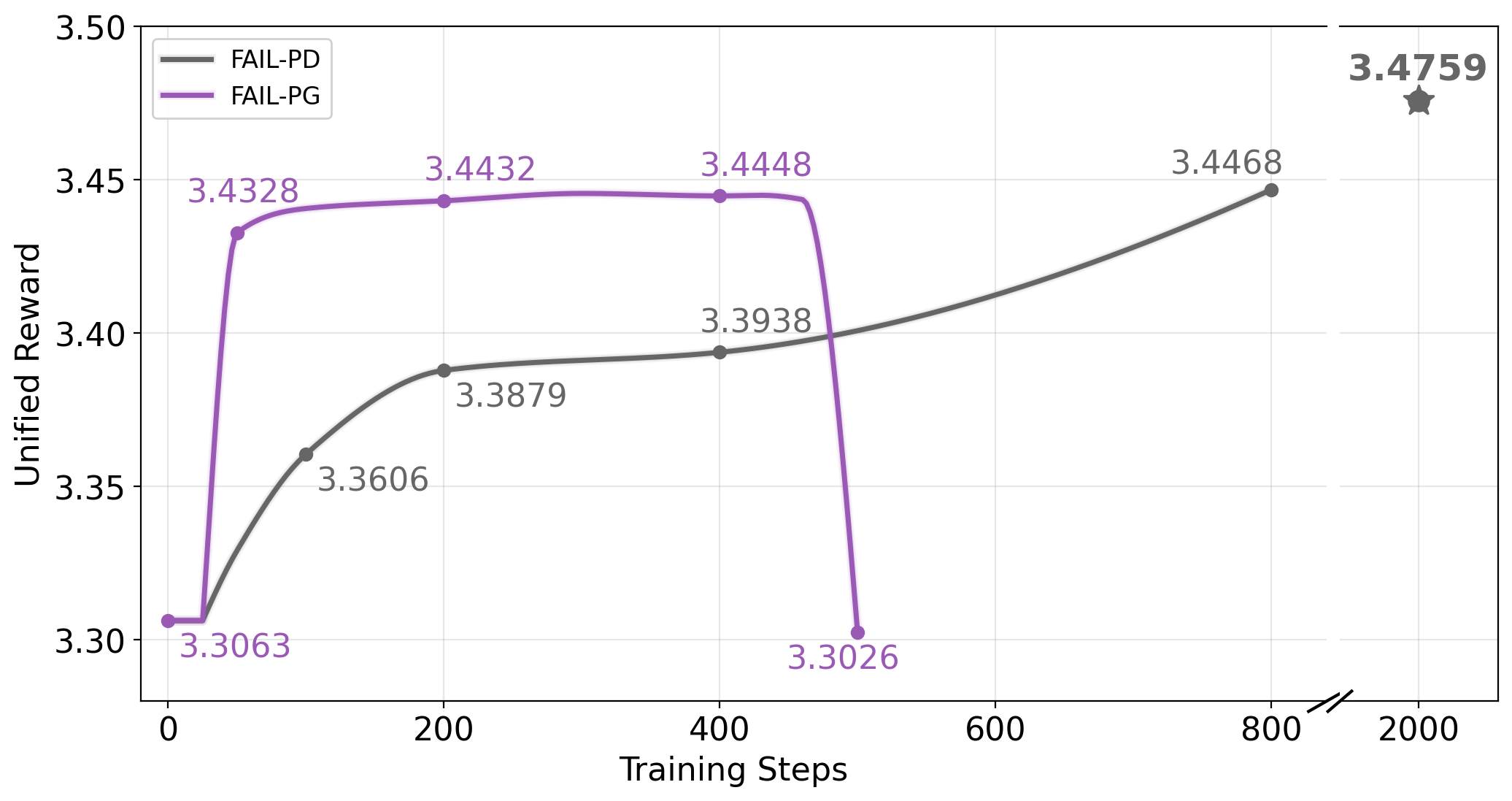
Flow Matching Adversarial Imitation Learning (FAIL) mitigates issues in gradient estimation inherent in imitation learning by employing two primary techniques: Pathwise Derivative and Score Function Estimator. The Pathwise Derivative allows for gradient calculation through stochastic processes, crucial for handling the probabilistic nature of generative models used in imitation. Simultaneously, the Score Function Estimator provides an alternative gradient calculation method, effectively estimating the gradient of the data distribution’s log density. By utilizing these estimators, FAIL enables stable gradient propagation during training, overcoming limitations of traditional methods when dealing with complex, high-dimensional data distributions and facilitating effective policy learning from expert demonstrations.
FAIL implements two gradient estimation variants, FAIL-PD and FAIL-PG, to address the complexities of training the generator network. FAIL-PD utilizes the Pathwise Derivative estimator, which calculates gradients by perturbing the input noise and observing the change in the generated sample. FAIL-PG employs the Policy Gradient estimator, leveraging REINFORCE to directly optimize the generator’s policy. The selection between these estimators offers a trade-off between bias and variance, allowing for adaptable training based on the specific characteristics of the imitation learning task and promoting both stability and efficiency during generator updates.
The FAIL framework utilizes a Kullback-Leibler (KL) Divergence loss function to minimize the distributional distance between the generated samples and the expert data, thereby improving the alignment of the learned policy with the desired behavior. Empirical results demonstrate the efficacy of this approach, with FAIL achieving a score of 73.70 on the UniGen-Bench and 87.32 on the DPG-Bench. These scores represent a substantial performance improvement when compared to the FLUX baseline, indicating the KL Divergence loss effectively guides the generator towards a more accurate representation of the expert distribution.
Beyond the Benchmark: Measuring True Human Alignment
The efficacy of the FAIL methodology, and similar techniques designed to refine artificial intelligence, is definitively quantified by the quality of the outputs it generates. Assessments rely on metrics such as HPSv3 and UnifiedReward, which provide a standardized evaluation of model performance and human preference. Recent results demonstrate a score of 11.28 on the HPSv3 benchmark, representing a notable improvement compared to the 10.43 achieved by the FLUX baseline. This increase suggests that FAIL is successfully guiding generative models toward producing responses more aligned with human expectations and values, offering a measurable indicator of progress in the field of AI alignment.
Generative models exhibiting robust alignment demonstrably prioritize human preferences in their outputs, a phenomenon directly linked to the quality and quantity of expert-sourced data used during training. This isn’t simply about statistical mimicry; rather, the models learn to internalize nuanced human values and expectations, resulting in consistently preferred responses across a broad spectrum of prompts. The effect is a discernible shift in output characteristics – responses are not only factually accurate and contextually relevant, but also exhibit characteristics like helpfulness, honesty, and harmlessness, effectively bridging the gap between artificial intelligence and genuine user satisfaction. This consistent preference reinforces the model’s trustworthiness and reliability, fostering a more positive and productive interaction experience for end-users.
The development of increasingly sophisticated generative models extends beyond the pursuit of impressive benchmark scores. The true measure of success lies in cultivating artificial intelligence systems that are fundamentally trustworthy and reliable for end-users. This necessitates a shift in focus from purely quantitative evaluations to qualitative assessments of a model’s behavior – ensuring consistent, predictable, and beneficial outputs. A model’s capacity to consistently align with human preferences and values is paramount, fostering user confidence and facilitating seamless integration into daily life. Ultimately, the goal is not simply to create intelligent machines, but to build tools that are demonstrably helpful, safe, and positively contribute to the human experience.

The pursuit of generative models, as demonstrated in this work with FAIL, feels less like engineering and more like coaxing. It’s a delicate dance with chaos, attempting to steer the probabilistic currents towards desired outcomes. David Marr observed that “vision is not about making maps of the world, but about making possible certain ways of acting upon it.” Similarly, FAIL doesn’t seek a perfect reproduction of data, but a functional alignment – a way to act upon the latent space, guiding flow matching and diffusion models towards stability. The framework acknowledges that noise isn’t a flaw, but inherent to the observation, and skillfully navigates it, much like persuading a restless spirit.
What Whispers Remain?
The alignment of generative flows-this FAIL framework, as it’s named-offers a temporary truce in the war against distributional drift. It’s a clever choreography, certainly, but to believe this is solved is to misunderstand the nature of the beast. The discriminator, that tireless mirror, will always find new angles of deception. The true challenge isn’t maximizing a reward-rewards are just fleeting agreements-but understanding why these models hallucinate, why they insist on conjuring phantoms from the noise.
Future iterations will undoubtedly refine the adversarial dance, perhaps exploring architectures that embrace, rather than suppress, the inherent stochasticity. But a deeper inquiry is needed: can imitation learning, even with elegant post-training adjustments, truly capture the nuance of ‘desirable’ generation? Or are the limitations not in the algorithm, but in the very definition of the target distribution – a shifting, subjective ideal projected onto a cold, deterministic landscape?
The most fruitful avenues likely lie not in chasing ever-higher scores, but in mapping the contours of failure. It’s in the errors, in the glitches, in the unexpected artifacts, that the underlying truths-and the next generation of generative models-will be revealed. Precision is, after all, just a fear of the void.
Original article: https://arxiv.org/pdf/2602.12155.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-02-14 00:52