Author: Denis Avetisyan
Researchers have developed a novel diffusion model that tackles the challenge of missing data in sequential recommendation systems, improving accuracy and personalization.
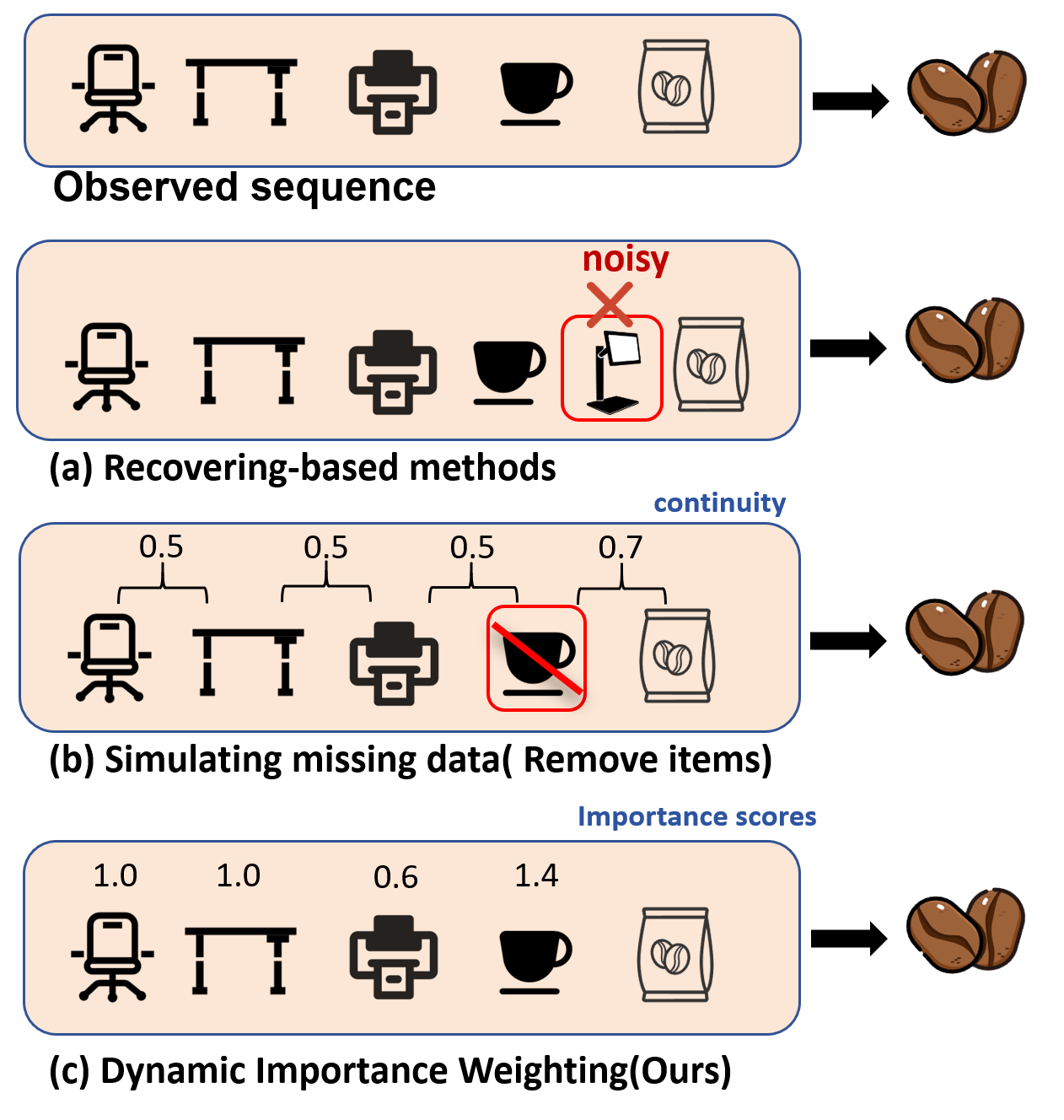
CARD dynamically optimizes guidance using counterfactual attention and sequence stability analysis for robust and effective sequential recommendations.
Despite advances in sequential recommendation, diffusion models remain vulnerable to suboptimal performance when user interaction sequences contain missing data-a common challenge in real-world scenarios. This paper, ‘Enhancing guidance for missing data in diffusion-based sequential recommendation’, addresses this limitation by introducing CARD, a novel model that dynamically refines the guidance signal used by diffusion models. CARD leverages counterfactual attention and sequence stability analysis to amplify the importance of key interest-turning-point items while suppressing noise, ultimately improving recommendation accuracy. Could this approach unlock more robust and personalized sequential recommendations in the face of incomplete user data?
The Illusion of Completeness in Sequential Recommendation
Modern recommendation systems increasingly rely on understanding the sequence of a user’s interactions – what they clicked on, purchased, or viewed, and in what order – to predict future preferences and deliver truly personalized experiences. However, a fundamental challenge consistently undermines this potential: incomplete data. User behavior is rarely fully observed; sessions are often interrupted, users may skip items, or platforms lack complete tracking capabilities. This missing data isn’t random noise, but rather represents crucial gaps in the narrative of a user’s journey, significantly hindering the accuracy of predictive models. Consequently, systems struggle to discern genuine patterns from incomplete information, leading to less relevant recommendations and diminished user engagement – a problem that demands innovative solutions to unlock the full power of sequential recommendation.
Conventional sequential recommendation techniques often falter when faced with incomplete user histories, a common scenario in real-world applications. These methods, designed for fully observed sequences, struggle to accurately infer user preferences from fragmented data, resulting in suboptimal performance metrics like precision and recall. This isn’t merely a technical issue; diminished accuracy directly translates to a less satisfying user experience, as recommendations become irrelevant or fail to anticipate evolving needs. Consequently, users may disengage with the platform, impacting key business objectives. The core problem lies in the inability of these systems to effectively model the reason for missing data – was an item simply not viewed, or was it deliberately skipped, indicating a negative preference? – leading to biased predictions and a cycle of decreasing user trust.
Simple data imputation techniques, while seemingly straightforward, often fall short when applied to sequential recommendation systems due to their inability to model the complex, temporal dependencies inherent in user behavior. Methods like replacing missing data with the mean or median interaction history disregard the order and context of previous actions, potentially introducing significant bias into the recommendation process. This can lead to the system falsely perceiving patterns where none exist, or conversely, overlooking genuine preferences. Consequently, recommendations generated from imputed data may not accurately reflect a user’s evolving interests, diminishing the system’s predictive power and ultimately resulting in a less satisfying and personalized experience. The assumption that past interactions are independent of each other, inherent in these basic imputation strategies, fundamentally misrepresents how users navigate and engage with items over time.
The pursuit of truly robust and reliable recommendation engines hinges directly on effectively navigating the complexities of incomplete data. Systems reliant on sequential patterns – understanding what a user did and when – are particularly vulnerable when interaction histories are fragmented. Failing to address this issue doesn’t simply reduce prediction accuracy; it fundamentally undermines the potential for personalized experiences and can lead to a cycle of irrelevant suggestions, eroding user trust. Consequently, significant research is focused on developing innovative techniques – beyond simple imputation – that can intelligently model user behavior even with limited information, ensuring that recommendations remain relevant, diverse, and ultimately, valuable to the individual. The success of future recommendation systems is therefore inextricably linked to overcoming this persistent challenge.
Beyond Filling Gaps: Reconstructing User Intent with Generative Models
Generative models, including Variational Autoencoders (VAE) and Generative Adversarial Networks (GAN), address missing data in user sequences by learning the probabilistic distribution of observed interaction patterns. Unlike traditional imputation methods which estimate single values for missing entries, these models aim to capture the complex relationships within sequential data. By modeling the underlying distribution, they can generate plausible interactions to ‘fill in’ gaps, effectively reconstructing incomplete sequences. This approach moves beyond simple replacement of missing values and instead leverages the learned data distribution to produce statistically likely completions, potentially leading to more accurate recommendations and predictions than methods relying on direct estimation or simple averaging.
Generative models address incomplete user sequence data by probabilistically generating interactions that are likely given the observed history. Rather than simply estimating what a user might interact with next, these models learn the underlying distribution of sequential behaviors and sample from it to create plausible extensions of existing sequences. This ‘gap-filling’ process effectively augments the training data with synthetic, yet statistically representative, interactions. By completing these sequences, the models can improve the accuracy of downstream prediction tasks, such as next-item recommendation or predicting long-term user engagement, as they are trained on a more complete representation of user behavior.
Initial applications of Variational Autoencoders (VAE) and Generative Adversarial Networks (GAN) to recommendation systems encountered difficulties related to training instability and the fidelity of generated interaction data. VAEs often produced blurry or unrealistic sequences due to the limitations of the variational lower bound and the difficulty in learning complex data distributions. GANs, while capable of generating sharper data, were prone to mode collapse and vanishing gradients, leading to unstable training processes and a lack of diversity in generated sequences. These issues stemmed from the inherent challenges in modeling sequential data with these architectures and the sensitivity of both models to hyperparameter tuning and network configuration within the specific context of user behavior prediction.
Diffusion Models, originating from the field of image generation, represent a class of generative models that learn to reverse a gradual noising process to synthesize data. Unlike Variational Autoencoders (VAE) and Generative Adversarial Networks (GAN), Diffusion Models demonstrate enhanced stability during training and consistently produce high-fidelity samples across diverse data modalities, including audio and video. This superior performance stems from their training objective, which focuses on denoising data iteratively, avoiding the mode collapse issues often encountered with GANs and the blurry outputs sometimes produced by VAEs. Recent research indicates significant potential for applying Diffusion Models to sequential recommendation systems, where they can generate plausible user interactions to complete incomplete sequences and improve prediction accuracy, potentially surpassing the performance of traditional imputation and other generative approaches.
CARD: A Framework for Counterfactual Attention and Diffusion-Based Recommendation
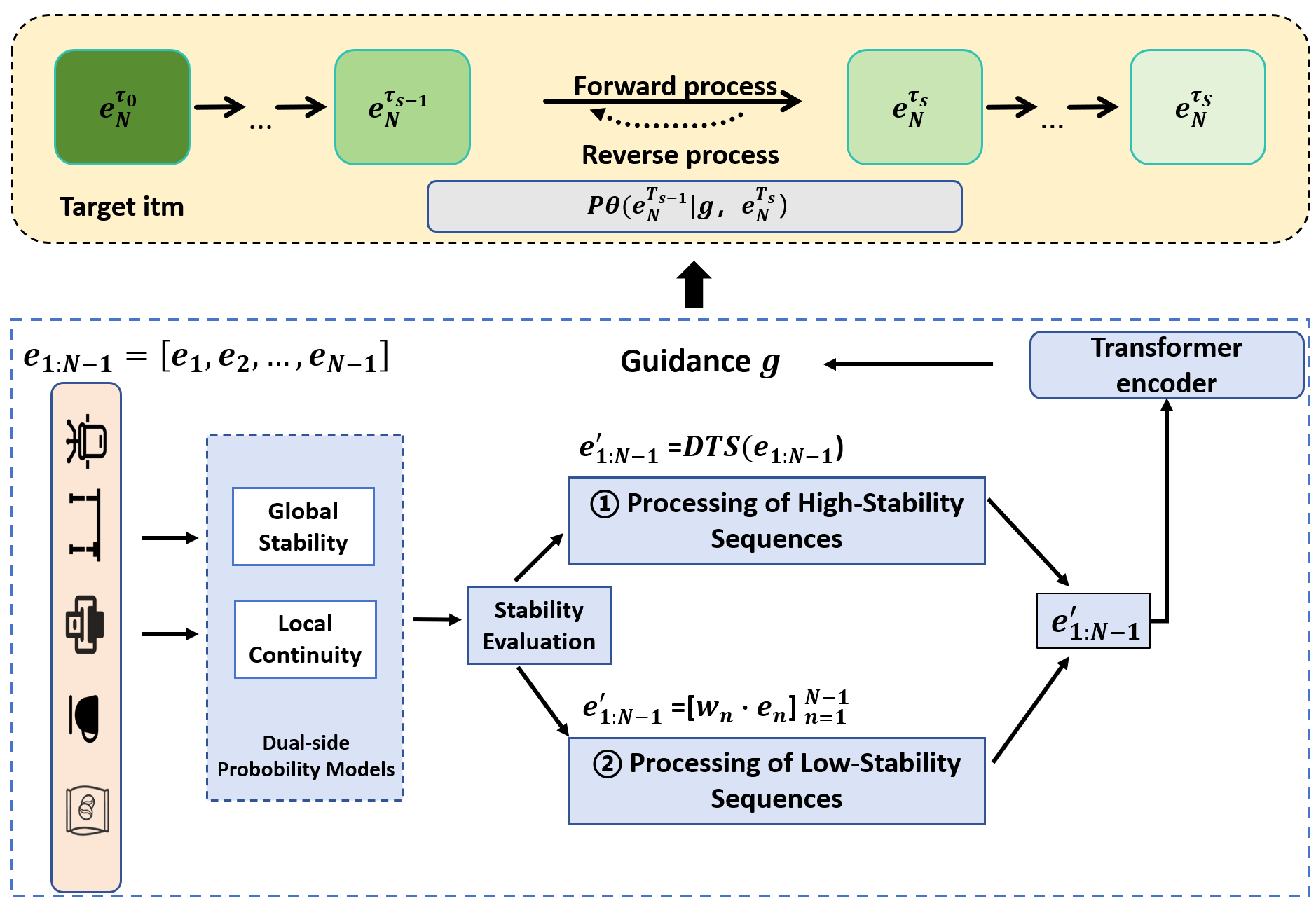
CARD addresses the challenge of missing data in sequential recommendation by integrating Diffusion Models with Counterfactual Attention. This framework leverages Diffusion Models to generate plausible user interactions, effectively imputing missing data points within a user’s interaction sequence. Counterfactual Attention mechanisms are then employed to identify and prioritize the generation of interactions that would have the most significant impact on the recommendation outcome, had those interactions been observed. This combination allows CARD to move beyond simple imputation and instead construct likely user behavior, improving the robustness and accuracy of recommendations in scenarios with incomplete data. The approach differs from traditional methods by explicitly modeling the uncertainty inherent in missing data and generating interactions based on probabilistic reasoning.
The CARD framework employs a Transformer Encoder to contextualize sequential user-item interactions and generate a ‘Guidance Vector’. This vector, derived from the encoded sequence, serves as a conditional input to the subsequent diffusion process. Specifically, the Transformer Encoder analyzes the historical interaction sequence to capture dependencies and patterns, and its output is then transformed into the Guidance Vector. This vector effectively steers the diffusion model towards generating plausible next interactions by providing a learned representation of user preferences and sequential context, influencing the sampling distribution during the denoising process and prioritizing the generation of items aligned with the observed sequence.
CARD employs Prediction Error Reduction (PER) as a mechanism to weight the contribution of each item within the sequential recommendation process. PER calculates the reduction in prediction error achieved by including a specific item in the generated sequence; higher reductions indicate greater importance. This quantified importance is then used to guide the diffusion model, prioritizing the generation of interactions that demonstrably minimize prediction loss. Effectively, CARD doesn’t treat all interactions equally, but instead focuses computational resources on generating those items that are most likely to improve the accuracy of recommendations, leading to more robust and reliable predictions in the presence of missing data.
CARD addresses data redundancy and missingness through a combined approach. The ‘DTS’ (Data Trimming Strategy) component actively reduces redundancy within sequential data, enhancing sequence quality for more efficient processing. To handle missing data, CARD employs ‘TDM’ (Temporal Data Masking), a simulation technique guided by two principles: ‘Local Continuity’, which ensures generated interactions are consistent with immediately preceding items, and ‘Global Stability’, which maintains overall sequence coherence across longer time spans. This simulated missingness allows the model to learn robust representations even with incomplete user histories, improving recommendation accuracy in real-world scenarios with sparse data.
Empirical Validation: Demonstrating Significant Performance Gains
Evaluations on prominent benchmark datasets, including Zhihu and KuaiRec, consistently demonstrate that CARD surpasses the performance of existing recommendation methods. These gains are rigorously quantified using industry-standard metrics like Hit Ratio (HR@20), which assesses whether a relevant item appears within the top 20 recommendations, and Normalized Discounted Cumulative Gain (NDCG@20), which measures the ranking quality of those recommendations. CARD’s consistent achievement of higher scores in both HR@20 and NDCG@20 indicates its ability to not only identify relevant items, but to present them in a manner that prioritizes user satisfaction and effectively addresses their preferences – a crucial advancement in recommendation system efficacy.
CARD’s innovative use of Counterfactual Attention fundamentally reshapes how recommendations are generated by prioritizing interactions most aligned with individual user preferences. This attention mechanism doesn’t simply assess the likelihood of an interaction; it actively considers what would have happened if a different interaction had occurred, allowing the model to refine its predictions based on these counterfactual scenarios. By focusing on these pivotal moments – those interactions that would most significantly enhance a user’s experience – CARD effectively filters out irrelevant or unhelpful recommendations. This targeted approach results in a substantial increase in recommendation accuracy, as the model learns to discern nuanced preferences and deliver content that truly resonates with each user’s unique tastes, surpassing the limitations of models relying solely on observed interaction data.
Prior generative recommendation models often struggle with instability during the interaction sequence generation process, frequently producing unrealistic or irrelevant recommendations. Counterfactual Attention Recommendation with Diffusion (CARD) addresses this through a diffusion-based approach, inspired by techniques used in image generation. This method begins with random noise and progressively refines it into a coherent interaction sequence, ensuring a stable and high-quality output. By iteratively denoising the sequence, CARD avoids the pitfalls of directly predicting interactions, leading to more plausible and user-relevant recommendations. The diffusion process effectively mitigates the exposure bias common in generative models, where errors accumulate over time, and promotes the generation of diverse yet meaningful interaction paths.
Evaluations on the Zhihu dataset reveal that CARD achieves substantial gains in recommendation performance when contrasted with existing state-of-the-art methods. Specifically, CARD demonstrates a marked 10.30% improvement in Hit Ratio at rank 20 (HR@20), signifying a greater likelihood of presenting relevant items within the top 20 recommendations. Complementing this, a 5.06% increase in Normalized Discounted Cumulative Gain at rank 20 (NDCG@20) indicates that the model not only recommends relevant items but also ranks them in a manner more aligned with user preferences. These results collectively showcase CARD’s ability to deliver significantly more effective and user-centric recommendations compared to established baseline models, highlighting its potential for practical application and improved user experience.
CARD addresses a fundamental challenge in sequential recommendation: incomplete data. The model doesn’t merely fill gaps, but actively reasons about what could have been. This echoes Ken Thompson’s sentiment: “Software is only complex because we make it complex.” CARD strives for elegance by dynamically optimizing guidance signals-a clear departure from brute-force imputation. It prioritizes sequence stability, recognizing that reliable recommendations stem from understanding underlying patterns, not just patching missing values. Every complexity needs an alibi, and CARD’s counterfactual attention provides precisely that – a justifiable reason for each adjustment, ensuring the model’s decisions are grounded in probabilistic reasoning and not arbitrary guesswork.
Further Refinements
The pursuit of generative recommendation, particularly through diffusion models, reveals a recurring tension: the desire for expressive power versus the need for stable, interpretable results. This work addresses the practical problem of missing data – an inevitability in real-world sequences – but the solution, while promising, merely shifts the locus of complexity. The dynamic guidance optimization, driven by counterfactual attention, introduces parameters demanding careful tuning. Future iterations must prioritize methods for automated hyperparameter selection, and explore the inherent trade-offs between responsiveness to sparse data and overall sequence fidelity.
A critical path forward lies in rigorous assessment of sequence stability beyond the metrics presented. The current focus appears largely confirmatory. Independent evaluation, employing entirely separate datasets and novel perturbation analyses, will be essential to demonstrate genuine robustness. The model’s susceptibility to adversarial attacks-subtle manipulations of observed sequences-remains an open question, and one that demands proactive investigation.
Ultimately, the field must confront a fundamental limitation. Diffusion models, by their nature, excel at generating plausible continuations. But true recommendation is not merely about plausibility; it is about utility. Measuring and maximizing long-term user satisfaction-a metric notoriously difficult to quantify-represents the ultimate, and perhaps unachievable, refinement.
Original article: https://arxiv.org/pdf/2601.15673.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Gold Rate Forecast
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
2026-01-25 04:30