Author: Denis Avetisyan
A new framework leverages autoregressive modeling and latent spaces to accurately solve complex equations even when only partial observations are available.
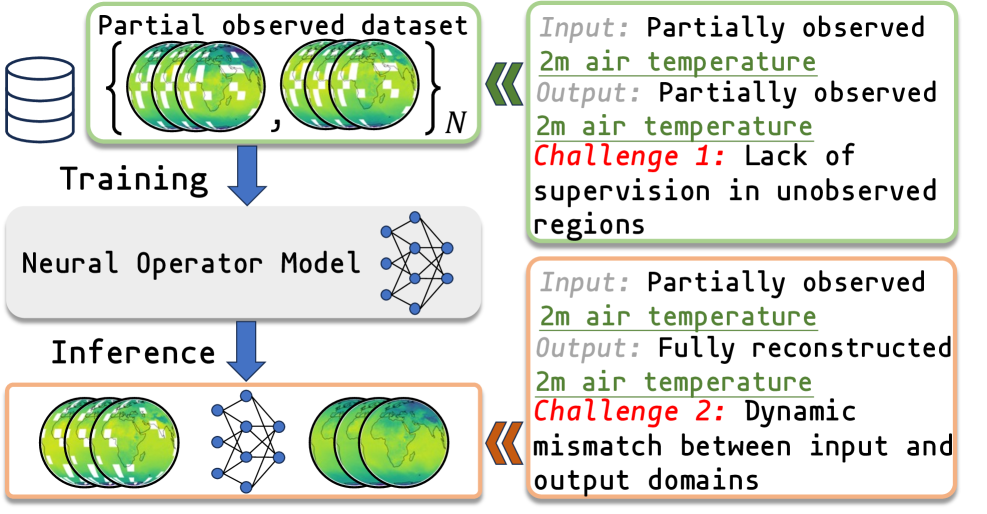
This work introduces LANO, a neural operator that combines masked prediction with a physics-informed autoregressive model for improved partial differential equation solving in data-scarce regimes.
Despite advances in physics-informed machine learning, neural operators typically require complete spatial observations, limiting their applicability to real-world scientific challenges with inherent data scarcity. This work, ‘Learning Neural Operators from Partial Observations via Latent Autoregressive Modeling’, introduces a novel framework-the Latent Autoregressive Neural Operator (LANO)-designed to effectively learn from incomplete data by combining masked prediction with a physics-aware autoregressive model in latent space. Through strategic training and boundary-first reconstruction, LANO achieves state-of-the-art performance across benchmark partial differential equation tasks, demonstrating significant error reduction even with substantial missing data. Could this approach bridge the gap between idealized simulations and the complexities of real-world scientific computing, unlocking new possibilities for data-driven discovery?
The Illusion of Complete Knowledge
The behavior of countless natural and engineered systems, from the flow of heat through a solid object to the propagation of waves in the ocean, is fundamentally described by Partial Differential Equations PDEs . These mathematical formulations express relationships between a function and its partial derivatives, allowing scientists and engineers to model complex phenomena across diverse fields. In physics, PDEs are essential for understanding electromagnetism, quantum mechanics, and fluid dynamics. Engineering applications span structural analysis, circuit design, and even weather forecasting, relying on these equations to predict system responses and optimize performance. The versatility of PDEs lies in their ability to represent continuous change and spatial variation, making them indispensable tools for simulating and analyzing a vast array of real-world processes.
The practical application of PDEs often collides with the realities of data acquisition. Complete knowledge of a system’s initial and boundary conditions – a prerequisite for traditional solvers – is rarely attainable. This limitation stems from numerous factors, including the sheer cost of comprehensive sensing, physical inaccessibility of certain regions, or the destructive nature of measurement itself. Consequently, researchers and engineers routinely confront scenarios of partial observation, where only a limited subset of the data needed to define a PDE is available. This incomplete information introduces significant challenges, demanding innovative approaches to inference and prediction that can effectively reconstruct the missing data or account for its uncertainty, rather than relying on the idealized assumption of full knowledge.
Conventional methods for solving Partial Differential Equations (PDEs) often falter when confronted with incomplete data, a common occurrence in real-world applications. These solvers, designed under the assumption of full observability, can produce solutions that diverge significantly from the true behavior of the modeled system, manifesting as inaccuracies or, in severe cases, computational instability. This presents a critical challenge for fields reliant on precise prediction and control – from weather forecasting and fluid dynamics to medical imaging and materials science. The inability to reliably extrapolate from limited observations undermines the effectiveness of these simulations, potentially leading to flawed designs, ineffective interventions, and compromised safety protocols. Consequently, significant research efforts are now focused on developing robust algorithms capable of handling partial observation and delivering dependable results even with imperfect data.
Beyond Discretization: A Functional Approach
Traditional numerical methods for solving inverse problems and partial differential equations (PDEs) rely on discretizing the continuous function spaces into finite-dimensional vector spaces, which introduces approximation errors and computational cost scaling with the desired resolution. Neural Operators circumvent this limitation by directly learning a mapping between function spaces; instead of approximating solutions on a discretized grid, they approximate the solution operator itself. This is achieved through architectures that accept functions as input and output functions, enabling predictions at arbitrary resolutions without retraining. The operator learns to map an input function u to an output function f(u) without requiring explicit definition of a grid or mesh, offering potential advantages in accuracy, efficiency, and generalization capability for problems where the solution manifold is complex or high-dimensional.
Neural operators demonstrate efficacy in solving Partial Differential Equations (PDEs) by learning the solution operator directly from data, rather than relying on traditional discretization methods. This data-driven approach allows the network to implicitly represent the underlying physical laws governing the PDE without requiring explicit formulation or extensive grid-based computations. Consequently, neural operators can achieve solutions with reduced computational cost and memory requirements, particularly for high-dimensional and complex PDE problems where traditional methods become intractable. The learned operator maps input functions – representing initial or boundary conditions – to output functions – representing the solution at a given point in time or space – effectively bypassing the need for explicit finite element or finite difference schemes.
Recent advancements in Neural Operator design include DeepONet, LNO, and Transolver, each addressing limitations of earlier approaches and offering distinct capabilities. DeepONet utilizes a deep neural network to learn the relationship between branch features and utilizes a multi-layer perceptron to approximate the solution operator. LNO (Linear Neural Operator) leverages Fourier-based spectral analysis to efficiently capture long-range dependencies and offers improved generalization performance, particularly when dealing with periodic boundary conditions. Transolver, based on the Transformer architecture, employs attention mechanisms to model complex interactions within the function space, demonstrating effectiveness in problems with localized features and irregular domains; its ability to handle variable input resolutions is a key benefit. These architectures differ in their computational complexity, memory requirements, and suitability for specific problem types, representing a diverse toolkit for solving function approximation tasks.
Forging Robustness Through Controlled Deficiency
Training Neural Operators with incomplete data is a critical requirement for deployment in practical applications due to the frequent occurrence of data loss or sensor failure. Real-world datasets are rarely complete; observations are often subject to partial occlusion, transmission errors, or limitations of measurement devices. Consequently, models trained solely on complete data exhibit diminished performance when confronted with these naturally occurring imperfections. By exposing the Neural Operator to partially observed data during the training phase, the model learns to infer missing information and construct robust representations, thereby enhancing its predictive accuracy and generalization capabilities in realistic scenarios. This approach moves beyond the limitations of traditional supervised learning, which assumes complete data availability, and directly addresses the challenges of noisy or incomplete input streams.
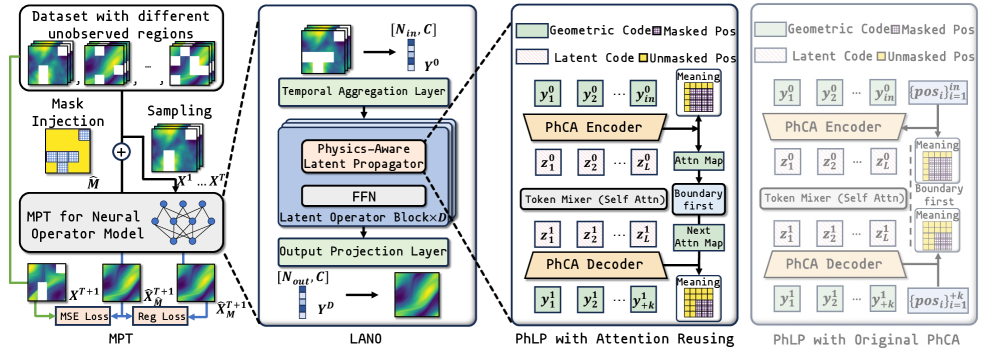
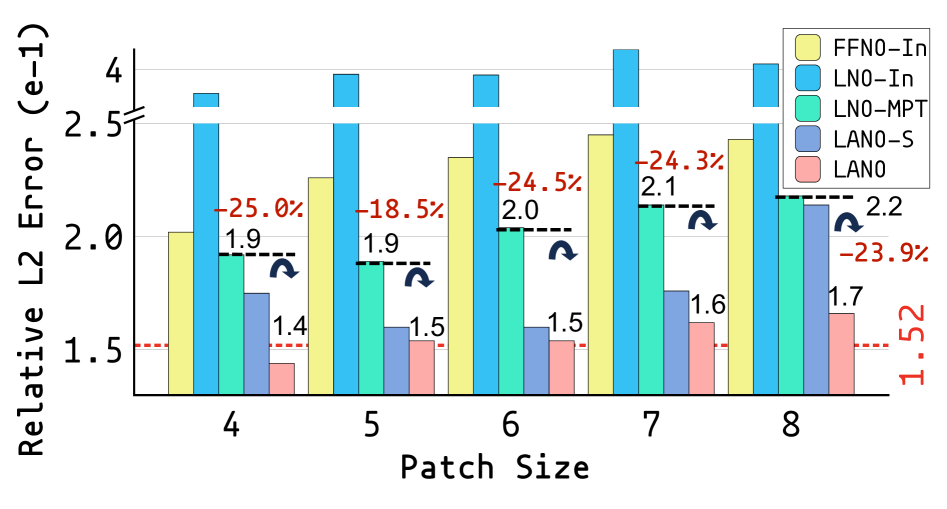
Mask-to-Predict Training (MPT) is a data augmentation technique utilized to enhance the robustness of Neural Operators when faced with incomplete input data. During the training process, MPT systematically masks portions of the input data, creating artificial missingness. The model is then tasked with predicting the masked values, effectively learning to infer missing information and construct representations that are less sensitive to data gaps. This forces the network to rely on correlations within the observed data, rather than memorizing complete input patterns, and consequently improves its ability to generalize to scenarios with incomplete observations during inference.
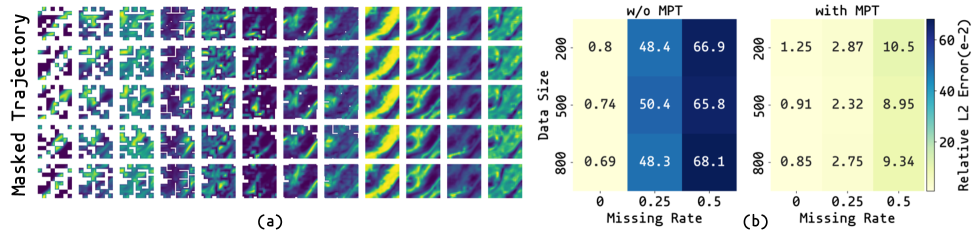
Mask-to-Predict Training (MPT) demonstrably improves generalization performance when applied to datasets exhibiting missing data. Evaluations indicate that MPT achieves up to an 84.3% reduction in error rates when tested on data with 50% of the observations missing, based on a dataset of 200 samples. This improvement is observed across different patterns of missingness, specifically Point-wise Missingness, where individual data points are removed, and Patch-wise Missingness, where contiguous regions of data are excluded. The technique effectively trains models to infer missing information and maintain accuracy even with incomplete input.
The Illusion of Control: Benchmarking Reality
A significant challenge in applying machine learning to physical systems arises from the frequent inability to observe the complete state – a situation known as partial observation. To address this, researchers developed POBench-PDE, a dedicated benchmark suite designed to rigorously evaluate the performance of partial differential equation (PDE) solvers under such realistic constraints. This suite moves beyond idealized scenarios by focusing on problems governed by the Navier-Stokes and Diffusion-Reaction equations, providing a standardized and reproducible testing environment. By offering a consistent platform for comparison, this enables more rapid progress in developing robust and accurate machine learning models for complex, real-world phenomena where complete data is often unavailable.
The POBench-PDE benchmark suite doesn’t rely on abstract mathematical problems; instead, it grounds its evaluations in the physics of fluid dynamics and chemical transport. Scenarios are built upon the Navier-Stokes equation, which governs the motion of fluids, and the Diffusion-Reaction equation, crucial for modeling how substances spread and interact. This approach deliberately mirrors the complexities found in real-world applications, such as weather prediction, ocean currents, or the dispersal of pollutants. By testing PDE solvers against these established equations under partial observation – where complete data is unavailable – the benchmark provides a more relevant and rigorous assessment of their performance in tackling challenging, practical problems.
Recent advancements in solving partial differential equations (PDEs) under realistic conditions-where complete data is rarely available-have yielded significant improvements through the LANO framework. This novel approach demonstrates a substantial reduction in error-up to 68.7% relative to existing methods-when applied to PDE-governed tasks with limited observational data. Rigorous benchmarking reveals LANO consistently surpasses the performance of competing models, exceeding the second-best baseline by an average of 17.8%. These results highlight the potential of Neural Operators, coupled with robust training methodologies, to address complex challenges in fields like fluid dynamics and chemical transport, offering a pathway toward more accurate and reliable simulations of real-world phenomena-even with incomplete information.
The pursuit of complete knowledge from incomplete data echoes a fundamental tension within all systems. This work, detailing LANO’s approach to learning neural operators from partial observations, doesn’t construct a solution so much as cultivate one. The framework embraces the inherent uncertainty, allowing the autoregressive model to propagate information across the latent space, effectively inferring the missing pieces. As Vinton Cerf observed, “Any sufficiently advanced technology is indistinguishable from magic.” LANO, by bridging the gap between limited data and accurate PDE solving, hints at that very illusion – a system not built, but grown, revealing patterns where once there was only absence. It is a testament to the power of letting the system confess its limitations, revealing the solution through its alerts – the propagated information – rather than forcing a complete, and ultimately brittle, construction.
What Lies Ahead?
The pursuit of learning from incomplete data, as exemplified by this work, isn’t about building more sophisticated sensors. It’s about accepting the inherent fragility of measurement. A system isn’t a machine to be perfected, but a garden-one always shadowed by what remains unseen. The elegance of latent autoregressive models lies not in their predictive power, but in their capacity to forgive the gaps in observation, to weave a plausible narrative from a fractured reality.
Yet, forgiveness has its limits. Current approaches still presume a certain stationarity, a belief that the underlying physics will remain consistent even as the observed landscape shifts. The true challenge isn’t merely reconstructing missing data, but anticipating where the data will be lost next, and building models that degrade gracefully rather than catastrophically. The field now faces the need to incorporate models of uncertainty, to acknowledge the epistemic shadows that cling to every prediction.
Ultimately, the success of physics-informed machine learning won’t be measured by its ability to solve equations, but by its capacity to learn from the failure of those equations to perfectly describe the world. A model that anticipates its own limitations, that understands the inevitability of error, is a model that has truly begun to learn.
Original article: https://arxiv.org/pdf/2601.15547.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-01-24 16:37