Author: Denis Avetisyan
A new approach to federated learning enables banks and institutions to collaboratively build powerful fraud detection models without sharing sensitive customer data.
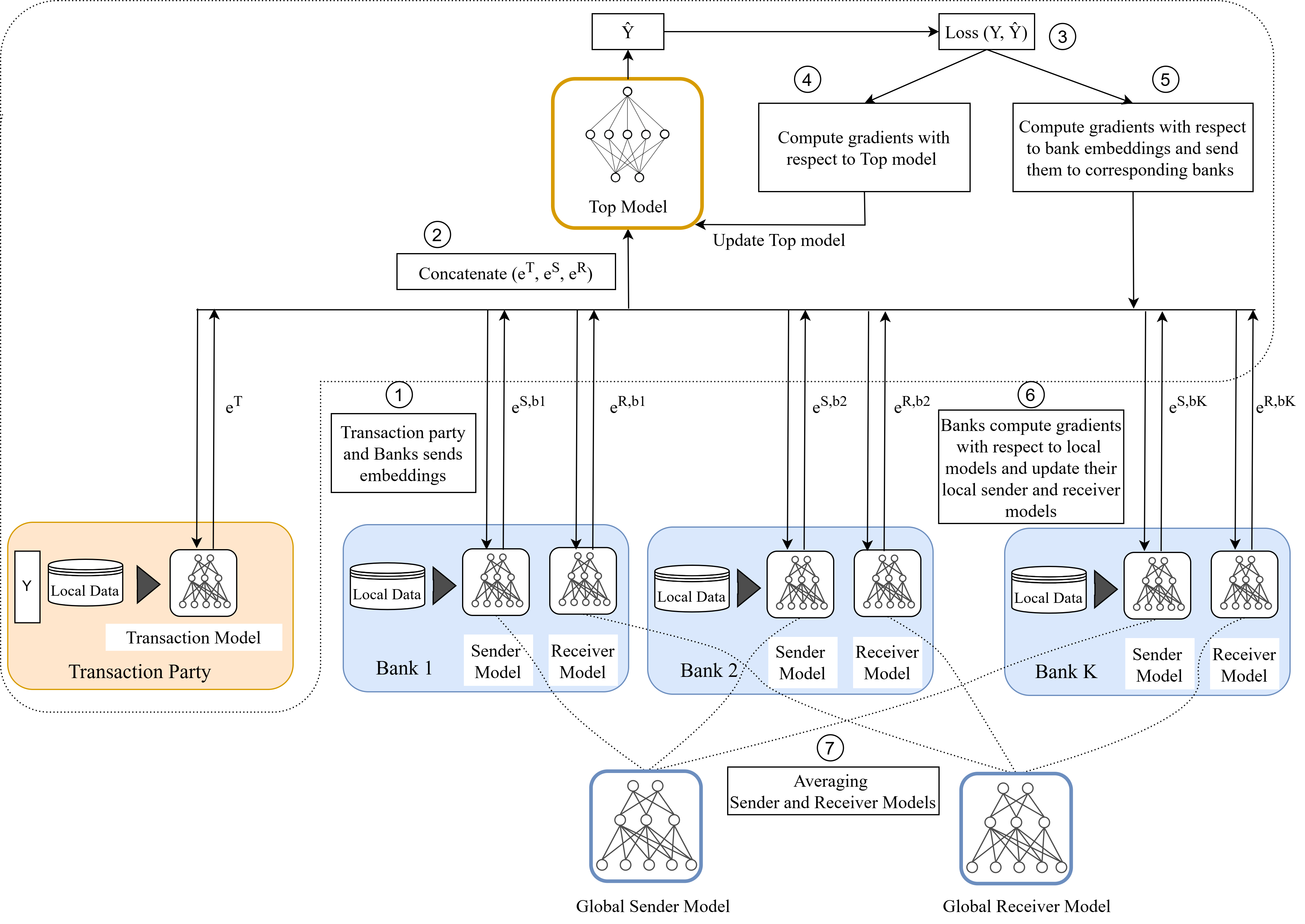
HybridFL utilizes a hybrid data partitioning strategy to achieve performance comparable to centralized learning while preserving data privacy through secure multi-party computation.
While maintaining data privacy is paramount in collaborative machine learning, traditional federated learning approaches struggle with complex, real-world data distributions. This paper introduces ‘HybridFL: A Federated Learning Approach for Financial Crime Detection’ to address scenarios where data is fragmented both across users and feature sets. By integrating horizontal and vertical federated learning, HybridFL enables joint model training for financial crime detection-achieving performance comparable to centralized methods while preserving data locality. Could this hybrid approach unlock more effective and privacy-conscious solutions for collaborative data analysis across diverse institutions?
Data Silos: The Architecture of Financial Obscurity
The pervasive issue of data fragmentation significantly impedes effective financial crime detection. Financial institutions each maintain vast stores of transaction data, customer profiles, and security logs, yet these remain largely isolated. This creates critical blind spots, as criminal activity frequently spans multiple institutions, masking illicit flows and enabling sophisticated schemes. Without a holistic view, patterns indicative of money laundering, fraud, or terrorist financing can easily go undetected. A single institution might observe only a fragment of a larger, coordinated effort, hindering their ability to identify and prevent financial crime effectively. The inability to correlate information across the financial ecosystem allows criminals to exploit these data silos, moving funds and obscuring their origins with relative impunity.
Historically, combating financial crime relied on consolidating data into centralized repositories for analysis. However, this approach increasingly encounters significant obstacles stemming from heightened privacy regulations and cross-border data restrictions. Laws like GDPR and similar frameworks prioritize data localization and individual rights, making the large-scale transfer and storage of sensitive financial information legally complex and often prohibitive. Furthermore, institutions understandably hesitate to relinquish direct control over customer data, fearing breaches or non-compliance. These combined pressures render traditional centralized models impractical, necessitating alternative strategies that can derive insights from distributed data sources without requiring their physical consolidation – a shift towards collaborative, rather than centralized, intelligence.
The escalating sophistication of financial crime demands a shift from traditional, siloed data analysis. Current approaches, reliant on consolidating information within single institutions, struggle to detect complex patterns spanning multiple entities. Researchers are now exploring collaborative learning techniques that circumvent the need for direct data sharing. These methods enable institutions to train algorithms on each other’s data without actually exchanging the sensitive information itself. Through innovations like federated learning and differential privacy, models are built and refined locally, with only aggregated insights – not raw data – being communicated. This paradigm promises to unlock a significantly broader understanding of illicit financial flows, bolstering detection rates while respecting privacy regulations and fostering a more resilient financial ecosystem.
Federated Learning: Dismantling the Centralized Fortress
Federated Learning (FL) is a distributed machine learning technique that allows multiple parties to jointly train a model while keeping their training data decentralized. Instead of aggregating data to a central server, FL algorithms train models locally on each participant’s data and then share only model updates – such as gradients or weights – with a central server or amongst peers. This approach addresses data privacy concerns and reduces communication costs associated with transmitting large datasets. The central server aggregates these updates to create an improved global model, which is then redistributed to the participants. This iterative process continues until a desired level of model performance is achieved, all without direct access to the underlying raw data.
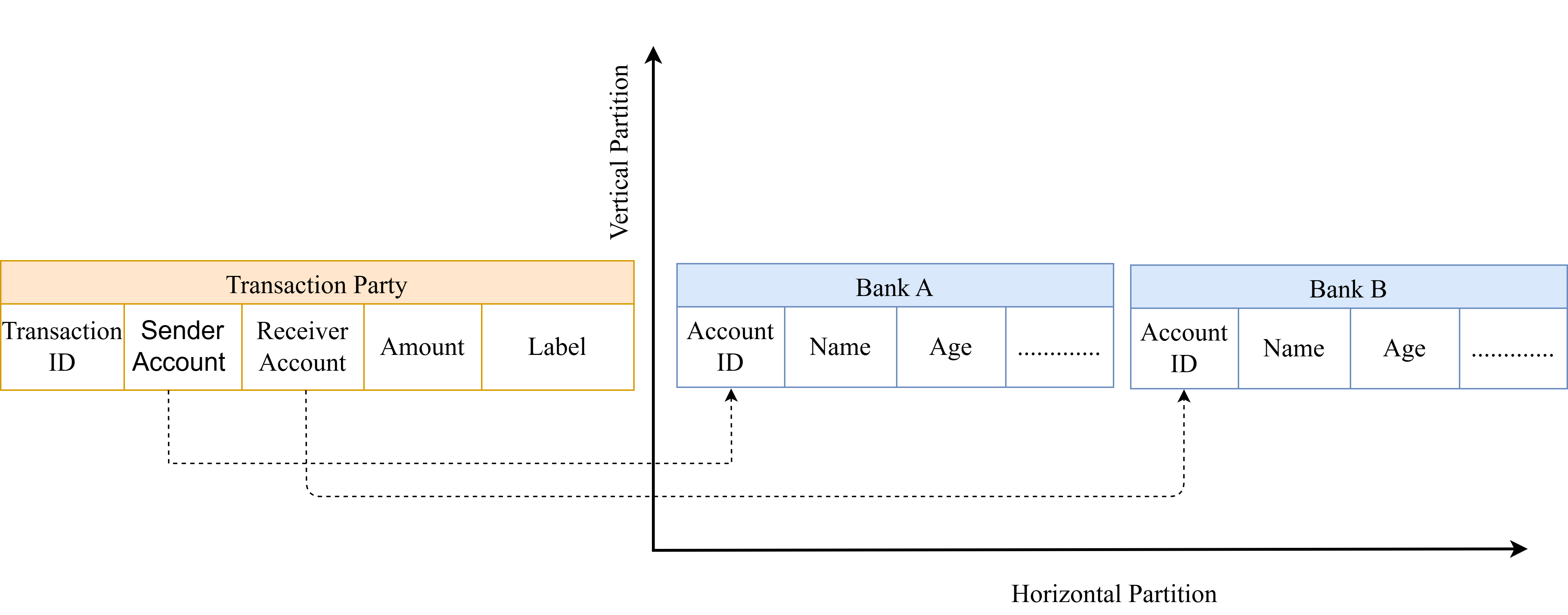
Horizontal Federated Learning (FL) operates effectively on datasets where each participating client possesses data with identical features, but differing individual samples – for example, multiple hospitals each storing patient data with the same set of attributes but for different patients. Conversely, Vertical FL is designed for scenarios where clients share the same samples – representing the same individuals – but possess distinct feature sets; a typical example involves a bank and an e-commerce company both having data on the same customers, but the bank holds financial information while the e-commerce company tracks purchase history. This distinction is critical because the data transfer mechanisms and privacy considerations differ significantly between the two approaches, dictating the appropriate FL strategy for a given collaborative task.
Hybrid Federated Learning extends the capabilities of both Horizontal and Vertical Federated Learning by combining their methodologies. This approach accommodates scenarios where data exhibits both differing samples and features across participating entities. Specifically, it allows for collaborative model training where some parties may share the same individuals or items (enabling Vertical FL) while others possess unique data points for those shared entities (supporting Horizontal FL). This integration facilitates more complex data collaborations, addressing a broader range of real-world problems than either Horizontal or Vertical FL can manage independently, and often improves model performance by leveraging a more comprehensive dataset.
Secure Aggregation and Differential Privacy: Obscuring the Signal
Secure aggregation enables multiple clients to collaboratively compute an aggregate value – such as the average of model updates – without revealing their individual contributions to the server. This is achieved through cryptographic techniques, primarily involving secret sharing and homomorphic encryption. Each client encrypts their model update using a unique secret key, and shares masked “shares” of the encrypted update with other participants and the server. The server combines these shares, decrypts the aggregate, and obtains the combined model update without accessing the individual client data. This process ensures that the server only learns the aggregate result, providing a formal privacy guarantee and preventing inference of individual client contributions, even in the presence of a compromised server.
Differential Privacy operates by adding a carefully calibrated amount of random noise to the data or model parameters before they are shared, thereby obscuring the contribution of any single data point. This noise is algorithmically determined to ensure that the output of any analysis remains largely unaffected while simultaneously limiting the ability to infer information about specific individuals within the dataset. The level of noise added is controlled by a parameter, ε, which represents the privacy loss; lower values of ε indicate stronger privacy guarantees but may reduce the utility of the data. Different mechanisms, such as Laplace or Gaussian noise addition, are employed depending on the sensitivity of the query and the desired privacy-utility trade-off. Crucially, Differential Privacy provides a provable, quantifiable guarantee of privacy, unlike other anonymization techniques that rely on assumptions about the attacker’s knowledge.
The integration of Secure Aggregation and Differential Privacy within a Hybrid Federated Learning framework significantly enhances the security and privacy of financial crime detection systems. Hybrid Federated Learning allows for the combination of on-device and centralized learning, leveraging the benefits of both approaches. Secure Aggregation ensures that only the aggregated model updates are visible to the central server, preventing the identification of contributions from individual participants. Simultaneously, Differential Privacy injects calibrated noise into these updates, further obscuring individual data points while maintaining model utility. This combined approach minimizes the risk of data breaches and protects sensitive financial information, satisfying regulatory requirements and fostering trust in the system’s data handling practices.
Dissecting Transactions: A Tripartite Behavioral Model
The core of the detection system lies in a novel three-encoder model designed to dissect the nuances of each transaction. Rather than treating transactions as isolated events, this architecture independently analyzes the transaction itself, the sending entity, and the receiving entity – each through a dedicated encoder. This allows the model to capture distinct behavioral patterns associated with each component; for instance, the transaction encoder might identify unusual amounts or frequencies, while the sender and receiver encoders assess atypical activity based on historical profiles. By extracting these independent yet interconnected behavioral signatures, the model builds a comprehensive understanding of transactional dynamics, ultimately providing richer features for accurate fraud prediction.
The core of this detection system lies in a ‘Top Model’ which intelligently synthesizes information gleaned from three distinct behavioral encoders – Transaction, Sender, and Receiver. This model doesn’t simply average the outputs of these encoders; instead, it learns complex relationships between transactional patterns, the sending entity’s history, and the receiving entity’s characteristics. By combining these insights, the Top Model generates a holistic representation of each transaction, enabling it to discern subtle anomalies indicative of fraudulent activity. This integrated approach allows for a more nuanced and accurate prediction of malicious transactions than would be possible by analyzing each element in isolation, ultimately leading to improved detection rates as demonstrated by the achieved AUPRC scores on both AMLSim and SWIFT datasets.
Performance gains in fraud detection hinge on meticulous optimization of the predictive model; consequently, the Top Model benefits from the Adam optimization algorithm, which efficiently adjusts model weights. Further refinement is achieved through the strategic application of loss functions – Binary Cross-Entropy guides the model towards accurate classification, while Focal Loss addresses class imbalance by focusing on misclassified transactions. Rigorous evaluation, quantified by the Area Under the Precision-Recall Curve (AUPRC), demonstrates the efficacy of this approach, yielding a score of 0.80 on the AMLSim dataset and 0.78 on the SWIFT dataset – results indicating a robust capacity to distinguish fraudulent activities from legitimate transactions.
AMLSim: Forging Data in the Crucible of Reality
AMLSim addresses a critical challenge in financial machine learning: the scarcity of labeled data for Anti-Money Laundering (AML) model development. This innovative tool generates synthetic banking transaction data that closely mirrors the statistical properties and complexities of real-world financial activity, offering a robust alternative to relying solely on limited and often imbalanced datasets. By providing a customizable and scalable source of training data, AMLSim enables the creation of more accurate and resilient AML models, even in scenarios where access to real transaction data is restricted due to privacy concerns or regulatory constraints. This capability is particularly valuable for evaluating model performance across diverse and challenging scenarios, including the detection of sophisticated fraud patterns and the adaptation to evolving money laundering techniques. The resulting models benefit from enhanced generalization capabilities and improved robustness, ultimately strengthening financial institutions’ ability to combat financial crime.
AMLSim’s simulated environment provides a crucial platform for iterative development and optimization of the complete Hybrid Federated Learning pipeline. Researchers and developers can systematically test each component – from data partitioning and local model training to secure aggregation and global model updates – under controlled conditions. This capability enables thorough evaluation of different configurations, hyperparameter tuning, and the identification of potential bottlenecks without the risks and limitations associated with real-world banking data. By allowing for repeated experimentation and refinement within a realistic yet safe digital space, AMLSim accelerates the development of robust and reliable federated learning systems for financial crime detection, ultimately bridging the gap between theoretical advancements and practical deployment.
The developed hybrid federated learning algorithm successfully navigates the performance trade-offs inherent in decentralized data environments. Unlike traditional federated learning which can suffer from limited data access, or centralized approaches that raise privacy concerns, this method achieves a balance – its performance consistently falls between that of a fully centralized model and one trained exclusively on a single participant’s data. This indicates effective knowledge transfer and learning from distributed datasets exhibiting both horizontal and vertical partitioning. Ongoing research aims to broaden the algorithm’s applicability by scaling it to accommodate substantially larger and more intricate datasets, while simultaneously investigating the integration of cutting-edge privacy-enhancing technologies to further safeguard sensitive information during the learning process.
The pursuit of HybridFL mirrors a fundamental principle: systems reveal their limits only when stressed. This research doesn’t simply apply federated learning to financial crime detection; it actively dissects the conventional approaches, recognizing that purely horizontal or vertical data partitioning presents inherent weaknesses. The resulting hybrid method, combining the strengths of both, isn’t a pre-ordained solution but an emergent property of iterative refinement. As Tim Berners-Lee aptly stated, “The Web is more a social creation than a technical one.” Similarly, HybridFL acknowledges that robust solutions aren’t born from theoretical perfection but from confronting the messy realities of fragmented data and the need for collaborative intelligence. The architecture’s ability to function despite data heterogeneity isn’t a happy accident; it’s a testament to rigorous experimentation and the willingness to challenge established norms.
What Breaks Down Next?
The pursuit of decentralized learning, as demonstrated by this work, invariably bumps against the hard limits of heterogeneous data. While HybridFL successfully navigates fragmented financial data, the assumption of similar fragmentation across institutions feels… optimistic. What happens when one participant’s data is consistently less informative, or represented by entirely different features? The aggregation process, currently a blend of local updates, will inevitably skew towards the dominant data profile, effectively centralizing the model around that single institution’s biases. A true stress test demands deliberately imbalanced participation – introducing ‘bad actors’ in the federated network, not malicious ones, but simply those with poor data – to expose the fragility of the consensus mechanism.
Furthermore, the reliance on secure multi-party computation, while elegant, introduces computational overhead. The question isn’t simply whether it can be done, but whether the marginal privacy gains justify the performance cost at scale. One anticipates a future where differential privacy, potentially sacrificing some accuracy for a robust, quantifiable privacy guarantee, will become the preferred trade-off, effectively trading model perfection for demonstrable security. The challenge will then shift to minimizing the information loss – actively reconstructing signal from deliberately obscured data.
Ultimately, this work functions as a useful, but temporary, stay against entropy. The real innovation won’t be in perfecting the current paradigm, but in dismantling it – in seeking learning architectures that are fundamentally not reliant on centralized objectives or shared parameters. The goal shouldn’t be to build a better collective intelligence, but to foster genuinely independent intelligences that can, perhaps, occasionally intersect.
Original article: https://arxiv.org/pdf/2602.19207.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 15 Films That Were Shot Entirely on Phones
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Silver Rate Forecast
- Here are the Best Series to Binge on Paramount+ in January 2026
- Monster Hunter Stories 3 Complete Side Stories Guide & What Do They Unlock
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-02-25 02:52