Author: Denis Avetisyan
New research reveals a potent attack that reconstructs private data from federated learning updates using advanced generative modeling techniques.
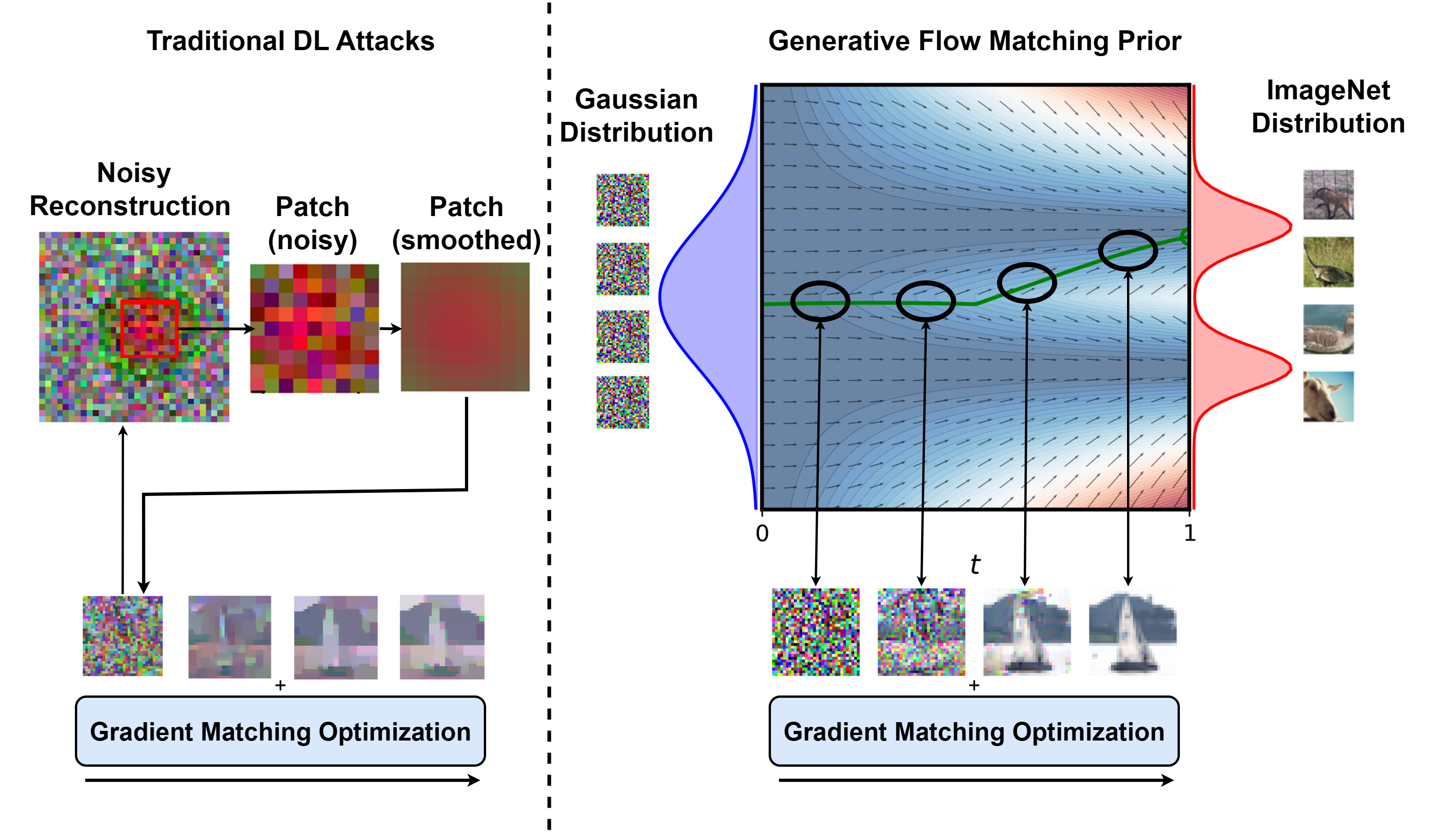
This paper introduces a deep leakage attack leveraging flow matching to demonstrate superior data reconstruction from federated learning, surpassing existing privacy threats.
Despite the promise of privacy-preserving decentralized training, Federated Learning remains vulnerable to sophisticated attacks that can reconstruct sensitive client data from shared model updates. This paper, ‘Deep Leakage with Generative Flow Matching Denoiser’, introduces a novel deep leakage attack that leverages the power of flow matching generative models to significantly enhance data reconstruction fidelity. Extensive experimentation demonstrates that this approach consistently outperforms state-of-the-art attacks, even under realistic conditions and with common defense mechanisms in place. These findings raise a critical question: how can we develop truly robust defense strategies against adversaries equipped with increasingly powerful generative priors capable of exploiting federated learning systems?
The Illusion of Privacy in Federated Learning
Federated learning presents a compelling paradigm for training machine learning models on decentralized data sources, offering the potential to bypass the need for direct data collection and thus enhance user privacy. However, this approach isn’t without its vulnerabilities; despite not directly sharing data, the iterative process of model updates can inadvertently leak sensitive information about the underlying training datasets. These updates, representing learned patterns, can be subjected to various attacks – such as membership inference or model inversion – that aim to reconstruct or infer details about individual data points. Consequently, while federated learning significantly reduces privacy risks compared to centralized training, it doesn’t eliminate them entirely, necessitating ongoing research into robust privacy-enhancing techniques to mitigate these inherent vulnerabilities and secure the system against increasingly sophisticated threats.
Conventional federated learning systems frequently encounter a fundamental challenge: achieving a satisfactory level of model accuracy while simultaneously ensuring strong privacy protections. The inherent distribution of data across numerous clients, though beneficial for privacy, introduces statistical complexities that can degrade model performance. Attempts to enhance privacy – such as adding noise to model updates or limiting the information shared – often come at the cost of reduced accuracy, as these techniques obscure the signal needed for effective learning. Conversely, prioritizing accuracy by sharing more detailed updates increases the risk of revealing sensitive information about individual clients’ datasets. This creates a precarious balance, demanding sophisticated algorithms and careful parameter tuning to navigate the accuracy-privacy tradeoff and develop truly practical, privacy-preserving machine learning solutions.
Despite the intention of preserving privacy, model updates shared during federated learning are susceptible to revealing details about the underlying training data. These updates – representing changes to the model’s parameters – can inadvertently encode information about the individual data points used to create them. Sophisticated attackers can leverage techniques like gradient inversion or membership inference to reconstruct sensitive attributes or even identify specific data samples present in a client’s dataset. This leakage occurs because machine learning models, even when trained in a distributed manner, learn patterns from the data, and those patterns are reflected in the updates. Therefore, seemingly anonymous contributions to the global model can, in fact, serve as a conduit for private information, highlighting a fundamental tension between utility and privacy in federated learning systems.
Safeguarding client data in federated learning environments demands the development of resilient defense mechanisms capable of countering increasingly complex attacks. Researchers are actively exploring techniques such as differential privacy, which intentionally adds noise to model updates to obscure individual contributions, and secure multi-party computation, enabling collaborative learning without revealing underlying data. Beyond these established methods, novel approaches involving homomorphic encryption and adversarial training are gaining traction, aiming to create models robust against inference attacks that attempt to reconstruct sensitive information from learned parameters. The efficacy of these defenses is continually assessed against evolving adversarial strategies, including model poisoning and membership inference, driving a constant cycle of innovation to ensure the confidentiality of user data while maintaining acceptable model performance.
Exposing the Ghosts in the Machine: Deep Leakage Attacks
Deep Leakage Attacks (DLAs) represent a privacy vulnerability specific to Federated Learning (FL) environments. Unlike traditional privacy concerns focusing on direct data exposure, DLAs exploit the iterative sharing of model updates – specifically gradients – to reconstruct training data. By analyzing the accumulated changes to model weights across multiple communication rounds, attackers can invert the learning process and generate approximations of the original images or data used to train the model. This reconstruction is possible even when employing privacy-enhancing techniques like differential privacy, though the attack’s effectiveness is reduced with stronger privacy guarantees. The core principle relies on the fact that gradient information, while intended to improve model accuracy, inherently contains information about the data itself, allowing for this indirect data recovery.
Deep Leakage Attacks (DLAs) reconstruct training data by inverting gradients shared during Federated Learning. Specifically, these attacks exploit the fact that model updates – containing gradient information about the training data – reveal characteristics of the data itself. An attacker iteratively refines an initial reconstruction by applying optimization techniques to minimize the difference between the model’s output on the reconstructed data and the observed gradients. This process effectively reverses the forward pass of the model, allowing sensitive data – such as images – to be recovered from shared updates, circumventing privacy mechanisms like differential privacy that typically protect only the model parameters themselves.
Total Variation (TV) regularization is a key component in successful Deep Leakage Attacks (DLAs) due to its effectiveness in image denoising. DLAs reconstruct training images from shared model updates; however, these reconstructed images are often noisy and lack clarity. TV regularization operates by minimizing the sum of the absolute differences between neighboring pixel values, effectively smoothing the image and reducing noise. This process encourages piecewise constant solutions, preserving edges while suppressing high-frequency details that contribute to noise. By applying TV regularization during the image reconstruction phase, DLAs significantly improve the fidelity and visual quality of the leaked images, making them more readily identifiable and increasing the risk of sensitive data exposure. The strength of the TV regularization parameter directly impacts the level of denoising achieved, with higher values leading to smoother, but potentially more blurred, reconstructions.
L2 Regularization and Batch Normalization, commonly employed to enhance the generalization and training stability of machine learning models, can unintentionally increase vulnerability to Deep Leakage Attacks (DLAs). L2 Regularization, by penalizing large weights, encourages smoother gradient updates which provide more readily exploitable signal for image reconstruction. Batch Normalization, while reducing internal covariate shift, normalizes gradients, also contributing to a clearer signal for attackers. Specifically, the normalized gradients resulting from Batch Normalization reduce the noise inherent in the shared model updates, allowing for more accurate reconstruction of training data images through iterative optimization techniques used in DLAs. These effects are not inherent to the performance benefit of the regularization, but rather a side-effect of how these techniques alter the gradient information exchanged during Federated Learning.

Flow Matching: A Temporary Reprieve?
Generative Flow Matching priors were investigated as a means to enhance the quality of Differential Privacy Local Aggregation (DPLA) reconstruction. This approach utilizes a pre-trained Flow Matching foundation model, functioning as a learned denoiser, to refine reconstructed images. By incorporating this generative modeling technique, the reconstruction process moves beyond traditional regularization methods, aiming to produce more accurate and visually realistic results. Quantitative evaluation on the CIFAR-10 dataset demonstrates performance improvements, with achieved Peak Signal-to-Noise Ratio (PSNR) of 20.861, Structural Similarity Index (SSIM) of 0.621, Learned Perceptual Image Patch Similarity (LPIPS) scores of 0.288 / 0.087, and a minimal Fréchet Mean Squared Error (FMSE) of 0.669.
Utilizing a Flow Matching foundation model as a learned denoiser offers improvements to differential privacy reconstruction by moving beyond the constraints of traditional regularization techniques. These techniques often introduce unwanted biases or fail to fully capture the underlying data distribution, leading to suboptimal reconstruction quality. Flow Matching, trained to estimate the score function of a data distribution, facilitates a more nuanced denoising process. By iteratively refining the reconstructed image based on the learned data distribution, the method minimizes reconstruction error while preserving privacy guarantees. This approach effectively addresses the limitations of methods reliant on hand-engineered regularizers or simplistic noise models, yielding more accurate and realistic reconstructions.
The utilization of generative modeling for differential privacy (DP) reconstruction introduces a trade-off between reconstruction quality and privacy preservation. While generative models, such as those employed in this work, demonstrably improve the fidelity and accuracy of reconstructed data – leading to metrics exceeding those of traditional regularization techniques – this enhanced realism also increases the potential for re-identification and information leakage. The improved reconstruction quality effectively reduces the noise introduced during the DP process, making it easier to infer sensitive attributes from the reconstructed output and thereby exacerbating the inherent privacy risks associated with data reconstruction techniques.
Reconstruction performance was quantitatively evaluated using several metrics on the CIFAR-10 dataset. Results demonstrate a Peak Signal-to-Noise Ratio (PSNR) of 20.861 and a Structural Similarity Index (SSIM) of 0.621. Perceptual similarity was assessed with the Learned Perceptual Image Patch Similarity (LPIPS) metric, yielding scores of 0.288 and 0.087. Furthermore, the Fréchet Mean Squared Error (FMSE) was measured at 0.669, indicating improved reconstruction quality compared to existing methodologies based on these values.

The Illusion of Security Persists
Evaluations reveal that Deep Leakage Attacks (DLAs) pose a significant threat to the privacy of Federated Learning (FL) systems, even when applied to commonly used datasets like CIFAR-10 and Tiny-ImageNet. These attacks successfully reconstruct sensitive training data by analyzing the gradients shared during the FL process, demonstrating a vulnerability beyond what traditional privacy assessments might capture. The study confirms DLA’s effectiveness across diverse image datasets, highlighting the need for more robust privacy mechanisms in FL deployments. The ability to achieve meaningful reconstruction rates – evidenced by results on Tiny-ImageNet – underscores the practical implications of this threat and calls for proactive defenses against gradient leakage in distributed learning environments.
Evaluating the privacy of federated learning (FL) systems requires careful consideration of reconstruction attacks, which aim to recover training data from the shared model updates. Recent studies demonstrate that seemingly privacy-preserving FL implementations are, in fact, vulnerable to these attacks, potentially exposing sensitive information about individual training examples. These attacks exploit patterns within the aggregated model parameters to infer characteristics of the original data, bypassing traditional privacy metrics focused solely on preventing direct data access. The success of reconstruction attacks underscores the necessity of robust privacy evaluations that go beyond simply measuring the protection of raw data, and instead assess the potential for data recovery from the learned model itself. Addressing this vulnerability is critical for deploying FL systems in sensitive applications where data confidentiality is paramount.
Recent investigations into the privacy vulnerabilities of Federated Learning (FL) demonstrate a significant advancement in reconstruction attack effectiveness, specifically when applied to the Tiny-ImageNet dataset. Researchers achieved a Structural Similarity Index (SSIM) of 0.444, a metric quantifying the perceived visual similarity between reconstructed and original images, thereby exceeding the performance of previously established attack methodologies. This result indicates a heightened risk of sensitive data leakage within FL systems trained on complex datasets like Tiny-ImageNet, as the reconstruction quality is sufficiently high to potentially reveal meaningful information about individual training samples. The improved attack success underscores the critical need for robust privacy-enhancing techniques to safeguard against such vulnerabilities in practical FL deployments.
The security of federated learning (FL) isn’t uniform across different aggregation strategies; how local model updates are combined significantly impacts vulnerability to privacy attacks. Current research reveals a need to deeply investigate the interplay between commonly used FL algorithms, such as FedAvg and FedSGD, and their respective resistance to adversarial techniques. Variations in these aggregation schemes – including differing learning rates, batch sizes, and the handling of model weights – can inadvertently create weaknesses exploited by malicious actors attempting to reconstruct sensitive training data. A comprehensive analysis comparing these schemes under various attack vectors is essential to determine which approaches offer inherent privacy advantages and to guide the development of more robust FL systems. Understanding these nuances will allow for the tailoring of aggregation methods to specific datasets and security requirements, ultimately bolstering the privacy guarantees of decentralized machine learning.
The development of truly private federated learning systems necessitates the incorporation of advanced privacy-enhancing technologies. Approaches like Differential Privacy introduce calibrated noise to model updates, obscuring individual contributions while preserving overall utility. Dropout, traditionally a regularization technique, can also function as a privacy mechanism by randomly masking features, limiting the information leakage from any single data point. Furthermore, Homomorphic Encryption allows computations to be performed directly on encrypted data, ensuring that sensitive information remains protected throughout the training process. Integrating these methods – and exploring novel combinations thereof – is not merely a theoretical exercise; it represents a crucial step towards deploying federated learning in sensitive domains like healthcare and finance, where data privacy is paramount and robust safeguards are essential.
The pursuit of increasingly complex federated learning schemes, as detailed in this study of deep leakage attacks, inevitably courts diminishing returns. The paper demonstrates how even sophisticated generative models, like those employing flow matching, become another vector for data reconstruction – a predictable outcome. It’s a testament to the fundamental truth that defenses are simply reactive layers atop existing vulnerabilities. As Andrew Ng once stated, “AI is magical, but also very brittle.” The researchers reveal how gradient information, the very lifeblood of these systems, leaks despite attempts at obfuscation. This isn’t a failure of the technique, but a confirmation of the cycle: innovation creates new surfaces for entropy to exploit. The problem isn’t a lack of cleverness, but the illusion of lasting security.
What’s Next?
The demonstrated efficacy of flow matching in exfiltrating data from federated learning systems feels less like a breakthrough and more like a confirmation. Anyone promising true privacy in distributed training was, predictably, offering wishful thinking. The current work merely refines the tools for demonstrating that wishfulness was, indeed, unfounded. One suspects the next generation of ‘privacy-preserving’ techniques will focus not on preventing leakage, but on obscuring it – a game of increasingly elaborate smoke and mirrors.
The resilience exhibited against existing defenses is particularly noteworthy. It suggests a fundamental flaw in the defensive approaches – a reliance on patching symptoms rather than addressing the core problem of information exposure. Future efforts will likely involve increasingly complex differential privacy mechanisms, or perhaps, a return to the quaint notion of keeping data centralized – a solution dismissed years ago as ‘unscalable,’ a term that always precedes spectacular failure.
It remains to be seen whether this line of attack will drive a pragmatic reassessment of federated learning’s true utility, or simply inspire a new arms race of obfuscation. One anticipates the latter. After all, the logs will always tell the tale, and the tale is rarely one of perfect security. Better one robust, auditable system than a hundred distributed illusions.
Original article: https://arxiv.org/pdf/2601.15049.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- Celebs Who Narrowly Escaped The 9/11 Attacks
2026-01-23 00:25