Author: Denis Avetisyan
A new study rigorously benchmarks the performance of several generative machine learning approaches in solving inverse design challenges, particularly within the demanding field of gas turbine combustor design.
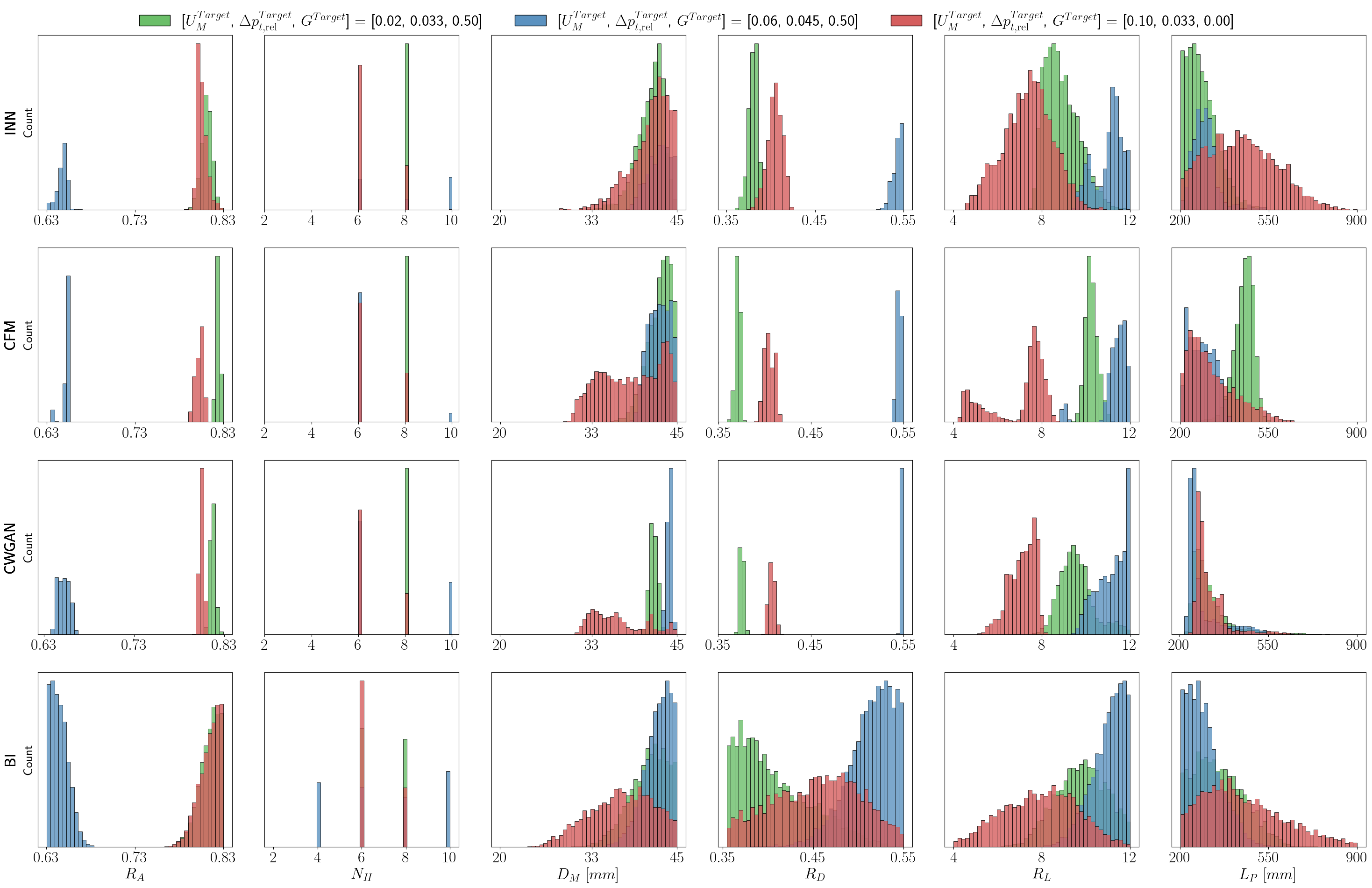
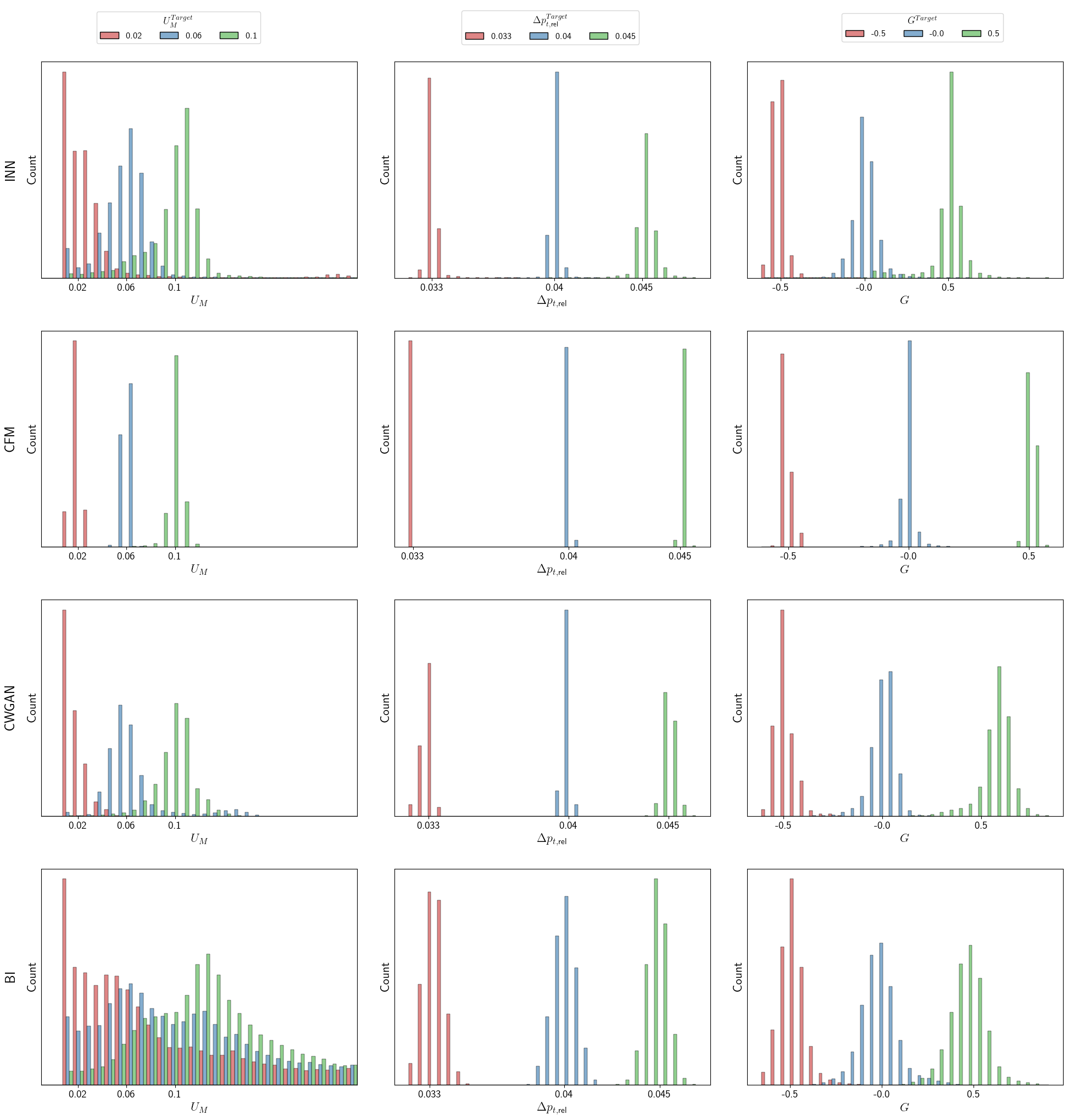
Conditional Flow Matching emerges as a leading technique for accurately and diversely generating optimal designs, surpassing Invertible Neural Networks and Generative Adversarial Networks.
Addressing the challenge of mapping desired outcomes to underlying design parameters-a core limitation in many engineering disciplines-this paper, ‘How well do generative models solve inverse problems? A benchmark study’, systematically evaluates the potential of modern generative machine learning techniques for inverse design. Through a comparative analysis of conditional Generative Adversarial Networks, Invertible Neural Networks, and Conditional Flow Matching-applied to the complex task of gas turbine combustor design-we demonstrate that Conditional Flow Matching consistently achieves superior performance in terms of both prediction accuracy and solution diversity. Given these promising results, can generative models become a standard tool for efficient and robust inverse problem solving across a broader range of scientific and engineering applications?
The Inevitable Complexity of Combustion
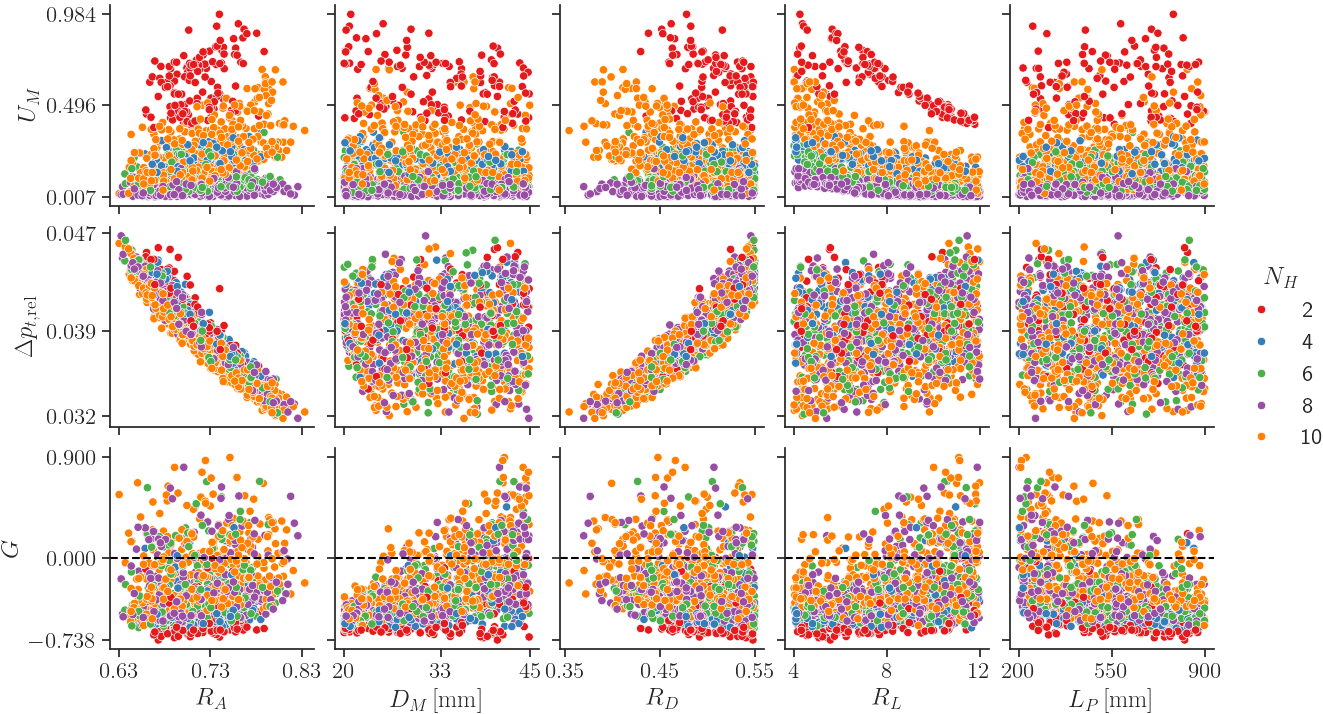
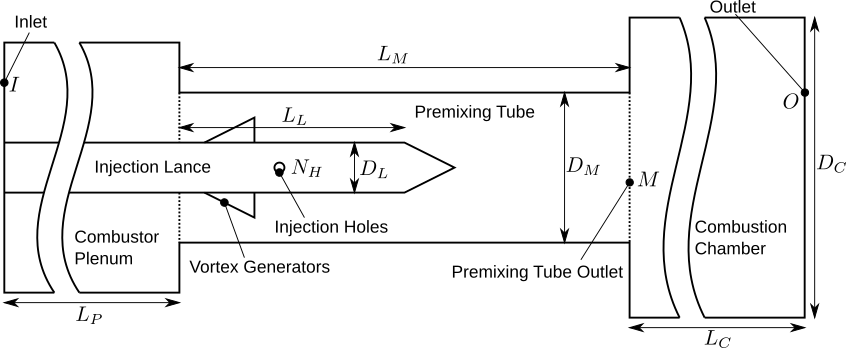
The creation of efficient gas turbine combustors presents a unique engineering challenge framed as an inverse problem. Unlike traditional design processes where geometry dictates performance, combustor development requires specifying desired performance characteristics – such as minimizing nitrogen oxide emissions or maximizing combustion stability – and then computationally determining the precise three-dimensional geometry needed to achieve those goals. This means engineers define the ‘what’ – the target PerformanceLabels – and the system must deduce the ‘how’ – the corresponding DesignParameters. The intricacy arises from the highly non-linear relationship between combustor shape and its resulting fluid dynamics, chemical reactions, and heat transfer, demanding innovative approaches to navigate this complex design landscape effectively.
Conventional gas turbine combustor design relies heavily on Computational Fluid Dynamics (CFD) simulations, a process that discretizes the complex flow field and solves governing equations for each potential geometry. However, the sheer intricacy of turbulent combustion, coupled with the need for high-resolution meshes to accurately capture relevant physics, renders each simulation remarkably time-consuming. This computational burden arises because even minor alterations to the combustor’s design – a slight adjustment to an injector angle or a subtle change in the liner curvature – necessitate a complete re-simulation to assess the impact on critical performance metrics like flame stability, temperature uniformity, and pollutant formation. Consequently, traditional design approaches are limited to evaluating a relatively small number of design iterations, hindering the ability to thoroughly explore the vast design space and identify truly optimal configurations.
The iterative nature of gas turbine combustor design is severely constrained by the extensive computational resources required for each simulation. Each slight alteration to the combustor’s geometry necessitates a complete computational fluid dynamics (CFD) analysis – a process that can take hours, or even days, to complete. This creates a significant bottleneck, effectively limiting the number of design iterations possible within a reasonable timeframe. Consequently, the exploration of the vast design space – the range of potential geometries – is drastically curtailed, hindering the identification of truly optimal configurations. The inability to rapidly test and refine designs directly impacts progress towards improved turbine efficiency and the critical reduction of harmful emissions, as the search for innovative solutions is slowed by these computational limitations.
The Illusion of Efficiency Through Approximation
A SurrogateModel functions as a computationally inexpensive approximation of a full CFDSimulation, which typically demands significant processing time and resources. This approximation is achieved through training the surrogate model on a limited set of CFDSimulation results, allowing it to learn the relationship between input parameters – such as combustor geometry or operating conditions – and the resulting performance characteristics. Once trained, the SurrogateModel can predict combustor performance for new, untested designs in a fraction of the time required for a CFDSimulation, facilitating rapid design iteration and exploration of a wider design space. The accuracy of the SurrogateModel is crucial, and is directly influenced by the quantity and quality of the training data derived from the original CFDSimulation.
Dataset augmentation techniques improve the accuracy of the surrogate model by expanding the training dataset beyond the initially available, computationally expensive CFD simulation results. This is achieved by utilizing the trained surrogate model itself to predict outputs for a wider range of input parameters, effectively generating synthetic data points. These newly generated data points, paired with their corresponding inputs, are then added to the original training set. This process increases the diversity and volume of training data, allowing the surrogate model to better generalize and more accurately represent the behavior of the complex CFD_{simulation}, particularly in regions where limited initial data exists.
The integration of a trained SurrogateModel with DatasetAugmentation techniques demonstrably lowers the computational burden of combustor performance assessment. Traditional CFDSimulation requires substantial processing time for each design iteration; the surrogate model, after initial training, provides near-instantaneous predictions. By augmenting the initial training dataset with data generated by the surrogate itself, the model’s accuracy is improved, allowing for reliable performance estimations with a fraction of the computational resources. This reduction in cost facilitates extensive design space exploration and enables efficient optimization algorithms to identify high-performing combustor configurations that would be impractical to evaluate using direct numerical simulation alone.
The Seeds of Creation: Generative Pathways
This work explores multiple generative modeling techniques for inverse design problems. Specifically, Conditional Wasserstein Generative Adversarial Networks (CWGANs) are assessed for their ability to generate designs based on desired performance characteristics. Complementary to this, Conditional Flow Matching (CFM) provides an alternative generative pathway, and Invertible Neural Networks (INNs) offer a deterministic approach to mapping between design parameters and performance labels. The investigation into these three methodologies – CWGAN, CFM, and INN – aims to establish a comparative understanding of their strengths and limitations within the context of generating optimized designs.
Conditional Wasserstein Generative Adversarial Networks (CWGANs) employ a gradient penalty to enforce Lipschitz continuity within the discriminator network. This constraint limits the discriminator’s capacity to produce arbitrarily large gradients, which is a common cause of training instability in standard Generative Adversarial Networks (GANs). By bounding the discriminator’s Lipschitz constant, the CWGAN facilitates more stable training dynamics and ensures the gradients remain meaningful throughout the optimization process. This is achieved by adding a penalty term to the discriminator’s loss function that measures the deviation of the gradient norm from a target value, typically one. The enforcement of Lipschitz continuity is critical for satisfying the conditions required by the Kantorovich-Rubinstein duality, which underpins the Wasserstein GAN framework and enables a more reliable measure of distance between the generated and real data distributions.
Normalization Flows are employed in both Conditional Flow Matching (`CFM`) and Invertible Neural Networks (`INN`) to establish a bijective mapping between the design parameter space and the corresponding performance label space. This transformation is achieved through a series of invertible transformations, allowing for efficient probability density estimation and sampling. By learning this mapping, the models can generate designs that achieve desired performance characteristics. The invertible nature of the flow ensures that any point in the performance label space can be mapped back to a valid design in the parameter space, and the Jacobian determinant of the transformation can be efficiently computed, facilitating accurate probability calculations and gradient-based optimization.
The Illusion of Control: Measuring Generative Fidelity
A rigorous quantitative assessment of four generative models – Conditional Wasserstein GAN (CWGAN), Conditional Flow Matching (CFM), Invertible Neural Networks (INN), and Bayesian Inference – was conducted utilizing a specifically designed EvaluationMetric. This metric facilitated a direct, comparative analysis of each model’s performance, moving beyond qualitative assessments to provide statistically grounded insights. The EvaluationMetric considered both the accuracy with which generated designs matched target specifications and the diversity of those designs, offering a comprehensive performance profile for each approach. By establishing a standardized method for evaluation, researchers could objectively determine the strengths and weaknesses of each model, ultimately guiding the selection of the most appropriate technique for a given design task and enabling fair comparison of future generative algorithms.
Evaluations reveal that Conditional Flow Matching (CFM) significantly exceeds the performance of competing generative models in both the accuracy and diversity of designs it produces. This advancement is evidenced by CFM’s ability to generate outputs that not only closely match the characteristics of the training data but also exhibit a wider range of plausible variations. This dual strength-high fidelity and broad diversity-positions CFM as a particularly effective approach for design tasks where both precise adherence to specifications and creative exploration are crucial. The model’s superior performance suggests a more robust and nuanced understanding of the underlying data distribution, enabling it to create designs that are both realistic and innovative.
Quantitative analysis reveals that Conditional Flow Matching (CFM) consistently generated designs with superior accuracy when compared to alternative generative models like CWGAN, INN, and Bayesian Inference. Across all tested labels and dataset sizes, CFM achieved the lowest Mean Absolute Error, indicating a closer alignment between generated and target parameter values. This performance advantage was substantial, with CFM outperforming the next best model by a margin of 31.5 to 83.3%, depending on the specific label and the size of the dataset used for evaluation. These findings underscore CFM’s ability to learn the underlying data distribution effectively and generate high-fidelity designs with minimized error, establishing it as a leading approach in this domain.
Analysis of the `Conditional Flow Matching (CFM)` model’s output reveals a strong fidelity to the underlying data structure, evidenced by the alignment between generated parameter distributions and the established correlations within the original dataset. This isn’t simply random generation; the model learns and replicates the relationships between target label values and the corresponding parameter sets, ensuring generated designs are not only plausible but also meaningfully connected to the desired characteristics. The generated parameters exhibit predictable shifts and variations based on the specified label, demonstrating that `CFM` effectively captures and reproduces the conditional dependencies inherent in the data – a crucial attribute for creating reliable and controllable generative systems.
The Inevitable Convergence: Towards Autonomous Innovation
The pursuit of truly autonomous combustor design hinges on a powerful synergy between generative modeling and robust optimization techniques. By integrating generative models – algorithms capable of creating novel designs – with optimization algorithms such as those utilizing BayesianInference and MCMC methods, engineers can move beyond iterative refinement of existing designs. This approach allows for the exploration of a vastly expanded design space, identifying configurations previously unconsidered and potentially exceeding the performance limits of traditional methods. The process effectively creates a self-improving system, where generated designs are evaluated, and the generative model is refined based on the results, leading to progressively optimized combustors tailored for specific performance criteria like efficiency, emissions reduction, and overall stability.
The application of generative models within combustor design unlocks access to a previously unattainable breadth of potential configurations. Traditional methods, constrained by computational cost and human intuition, typically explore only a limited subset of the total design space. However, by leveraging algorithms capable of proposing and evaluating numerous designs – far exceeding what manual iteration allows – researchers can identify solutions exhibiting superior performance characteristics. This expanded exploration isn’t merely about quantity; the generative process frequently uncovers non-intuitive designs – geometries and operating parameters that a human engineer might not consider – leading to improvements in efficiency, reductions in harmful emissions, and overall enhancements to combustor functionality. The resulting designs often demonstrably outperform those created through conventional approaches, suggesting a paradigm shift in the field of combustion engineering.
The envisioned future of combustor engineering centers on a self-improving, closed-loop design system. This system wouldn’t simply generate designs, but would continuously evaluate performance metrics – encompassing fuel efficiency, pollutant emissions, and overall operational stability – and then iteratively refine its design process based on those results. By integrating computational simulations with optimization algorithms, the system aims to autonomously explore the vast parameter space of combustor designs, identifying configurations that surpass the limitations of human intuition and conventional methodologies. This continuous learning cycle promises not only incremental improvements but the potential for disruptive innovations in combustion technology, leading to engines that are simultaneously more powerful, cleaner, and more efficient. Ultimately, such a system represents a paradigm shift, moving away from reactive design adjustments toward proactive, data-driven optimization that adapts to evolving performance goals and operating conditions.
The pursuit of inverse design, as demonstrated in this study of gas turbine combustors, mirrors a natural cycle of emergence and refinement. Each generative model-Conditional Flow Matching, GANs, or Invertible Neural Networks-proposes a solution, a tentative form arising from the constraints of the problem. The consistent performance of Conditional Flow Matching isn’t about control, but about allowing a more graceful adaptation to the inherent uncertainties. As Henri Poincaré observed, “Mathematics is the art of giving reasons.” This work doesn’t build solutions, it cultivates them, revealing how a system’s future state emerges from the interplay of past conditions and present iterations – a prophecy of what will be, rather than a rigid decree of what should be.
What Lies Ahead?
The pursuit of inverse design, as demonstrated by this work, is not a quest for solutions, but a negotiation with constraint. To claim superiority for one generative approach over another – Conditional Flow Matching, Invertible Neural Networks, or the ever-shifting landscape of Generative Adversarial Networks – feels… provisional. The combustor may yield to these models, but the underlying physics remains indifferent to their architecture. Each refinement of the generative process simply reveals new facets of the problem’s intractability.
The true challenge isn’t accuracy or diversity, measured against a fixed dataset. It’s the inevitable drift of real-world conditions. A combustor designed today will operate tomorrow under pressures unforeseen, with fuels uncatalogued. The models, however elegant, are frozen compromises. They capture a moment, not a trajectory. The field will likely move toward methods that explicitly model uncertainty, acknowledging that prediction is, at best, informed speculation.
One suspects the ultimate utility lies not in automated design, but in accelerated failure analysis. To rapidly explore the edges of operational limits, to anticipate the unexpected modes of breakdown – that is a problem well-suited to these tools. For technologies change, dependencies remain, and the most robust designs are those that gracefully accommodate the inevitable.
Original article: https://arxiv.org/pdf/2601.23238.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Gold Rate Forecast
- Silver Rate Forecast
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Building Agents That Learn and Improve Themselves
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 15 Films That Were Shot Entirely on Phones
- Games That Faced Bans in Countries Over Political Themes
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 20 Films Where Black Directors Subverted Hollywood’s White Savior Tropes
2026-02-02 11:11