Author: Denis Avetisyan
Researchers have developed a novel framework that leverages multi-scale modeling to generate highly realistic and scalable time series data.

TimeMAR combines autoregressive models with dual-path vector quantization and coarse-guided reconstruction for improved fidelity and efficiency.
Despite advances in generative modeling, capturing the inherent multi-scale and heterogeneous nature of time series data remains a significant challenge. This work introduces ‘TimeMar: Multi-Scale Autoregressive Modeling for Unconditional Time Series Generation’, a novel framework that addresses this limitation through disentangled representation learning and coarse-to-fine generation. Specifically, TimeMar leverages a dual-path Vector Quantized Variational Autoencoder and autoregressive modeling to produce higher-quality time series with reduced parameters. Can this approach unlock new possibilities for long-term time series forecasting and data augmentation in resource-constrained settings?
The Challenge of Authentic Temporal Data
The creation of authentic time series data is increasingly vital across a spectrum of scientific and industrial applications. Beyond simple predictive forecasting – anticipating stock prices or weather patterns – high-fidelity time series are fundamental to robust simulations. These simulations span diverse fields, from modeling complex physiological systems for medical research to optimizing energy grid performance and validating autonomous vehicle control systems. The ability to generate data that accurately reflects real-world temporal dynamics allows researchers and engineers to test hypotheses, train machine learning models, and assess system behavior under a wide range of conditions, all without relying solely on scarce or costly empirical observations. Consequently, advancements in generating realistic time series are directly linked to progress in numerous critical domains, enabling more informed decision-making and accelerating innovation.
Conventional time series analysis techniques frequently encounter difficulties when modeling the intricate relationships and varying scales present in authentic data. These methods often rely on assumptions of linearity or stationarity, which rarely hold true for real-world phenomena exhibiting non-linear behaviors and evolving patterns over time. Consequently, they may fail to capture subtle yet crucial dependencies – such as lagged effects, seasonality at multiple frequencies, or abrupt shifts in trend – leading to inaccurate predictions or incomplete simulations. The inherent complexity arises from the fact that time series data is often influenced by factors operating at different temporal resolutions, requiring models capable of simultaneously representing both short-term fluctuations and long-term trends to truly reflect the underlying dynamics.
Generative models, while revolutionizing fields like image synthesis, often falter when applied to time series data, frequently producing outputs that lack the fidelity and stability observed in real-world phenomena. The inherent sequential nature of time series, with its nuanced dependencies extending across numerous time steps, presents a significant challenge for architectures like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). GANs, prone to mode collapse, can generate repetitive or unrealistic patterns, while VAEs, aiming for smooth latent spaces, often produce overly simplified or ‘blurred’ time series lacking critical high-frequency details. These models struggle to maintain long-term coherence and can exhibit instability during training, leading to divergent or nonsensical outputs that fail to accurately reflect the complex, dynamic behavior of genuine time-dependent data.
The faithful reproduction of time series often falters due to the inherent need to model phenomena across vastly different timescales. Real-world processes exhibit patterns operating at high frequencies – think of rapid stock price fluctuations – alongside slower, underlying trends like seasonal economic cycles. Capturing both simultaneously presents a significant hurdle; methods effective at modeling short-term dependencies frequently fail to grasp long-range correlations, and vice versa. This multi-scale nature demands models capable of disentangling and representing temporal dynamics at various resolutions, a task complicated by the interplay between these scales and the potential for information loss during downsampling or upsampling processes. Consequently, generated time series often lack the nuanced complexity observed in authentic data, exhibiting unrealistic smoothness or failing to accurately reflect persistent, low-frequency behaviors.
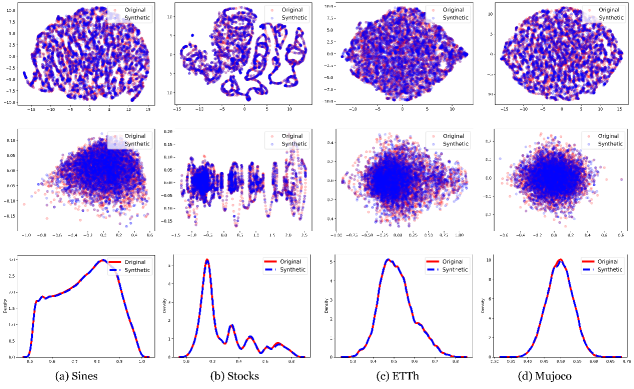
TimeMAR: A Framework for Multi-Scale Temporal Synthesis
TimeMAR tackles the problem of generating realistic time series data by integrating three core components: autoregressive modeling, Vector Quantized Variational Autoencoder (VQ-VAE) encoding, and coarse-guided reconstruction. Autoregressive modeling predicts future values based on past observations, establishing temporal dependencies. The VQ-VAE component discretizes the continuous time series into a sequence of tokens, allowing the model to learn a compact representation of the data and enabling efficient generation. Coarse-guided reconstruction further refines the generated sequences by incorporating information from a lower-resolution version of the time series, promoting overall stability and preventing drift in long-range predictions. This combined approach allows TimeMAR to capture both short-term fluctuations and long-term trends inherent in complex time series data.
TimeMAR employs Trend-Seasonal Decomposition to initially separate observed time series data into trend and seasonal components, allowing for focused analysis and reconstruction of each underlying pattern. Following decomposition, a Dual-Path Encoding scheme is implemented, processing the trend and seasonal components through independent encoding pathways. This independent processing enables the model to capture distinct characteristics of each component, avoiding interference and improving the fidelity of the generated time series. The outputs of these separate encoding paths are then integrated for subsequent processing within the VQ-VAE framework, facilitating a more nuanced representation of temporal dependencies.
Hierarchical Quantization within TimeMAR involves representing continuous time series data as a sequence of discrete tokens at varying levels of granularity. This is achieved by applying Vector Quantization (VQ) multiple times, creating a hierarchy of codebooks. Initially, the time series is coarsely quantized, capturing long-term dependencies with a limited vocabulary. Subsequent layers refine this representation with finer-grained quantization, increasing the vocabulary size and capturing shorter-term temporal dynamics. This multi-scale approach allows the model to learn and generate time series data by predicting sequences of these quantized tokens, effectively modeling temporal relationships across different timescales and reducing the computational burden compared to directly modeling continuous values.
TimeMAR’s design prioritizes both the fidelity and predictability of generated time series data. Realism is achieved through the combination of autoregressive modeling – which captures sequential dependencies – with the detail preserved by VQ-VAE encoding and coarse-guided reconstruction. Stability is ensured by the hierarchical quantization process, which discretizes the time series into tokens and facilitates the learning of long-range temporal dependencies at multiple scales. This multi-scale approach reduces the risk of generating unstable or implausible data, as the model learns to reconstruct the time series based on both fine-grained details and broader, overarching trends.
Validation and Performance: Demonstrating TimeMAR’s Efficacy
TimeMAR generates time series data demonstrably closer to real-world observations, a conclusion supported by both visual inspection and statistical analysis. Qualitative assessment confirms the generated series exhibit plausible patterns and characteristics. Quantitative validation utilizes metrics designed to assess fidelity and realism; specifically, the framework’s performance is measured through the Predictive Score for forecasting accuracy and Context-FID for statistical similarity to authentic data. Further, the Discriminative Score quantifies the ability to distinguish generated samples from real data, with TimeMAR achieving scores below 0.1 across multiple datasets, indicating high fidelity and a reduced ability for discrimination between synthetic and observed time series.
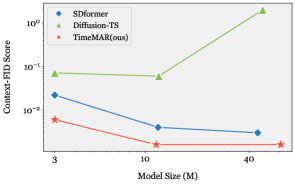
TimeMAR’s performance evaluation utilizes two primary metrics: the Predictive Score and Context-FID. The Predictive Score quantifies the accuracy of time series forecasting performed by the model. Context-FID (Frechet Inception Distance) measures the statistical similarity between generated time series data and real-world data; lower Context-FID values indicate a closer match to the real data distribution. This metric assesses how well the generated data captures the complex patterns and dependencies present in the original dataset, providing insight into the realism of the generated time series. Both metrics are crucial for a comprehensive assessment of TimeMAR’s capabilities in generating accurate and statistically plausible time series data.
The Discriminative Score is employed as a quantitative metric to assess the fidelity of generated time series data by measuring the ability of a discriminator model to distinguish between synthetic and real samples; a lower score indicates higher similarity and thus, improved realism. TimeMAR consistently achieves a Discriminative Score below 0.1 across multiple datasets, including Sines, Stocks, and Energy, demonstrating a substantial improvement over comparative methods like SDformer and indicating that the generated data is highly indistinguishable from authentic time series data.
Comparative analysis demonstrates TimeMAR’s superior performance against the SDformer model across multiple datasets. Specifically, TimeMAR achieved an 87.5% reduction in Context-FID on the ETTh dataset, indicating improved statistical similarity to real time series data. Furthermore, performance evaluations on the Sines, Stocks, and Energy datasets reveal a 50% reduction in Discriminative Score, signifying enhanced fidelity and a reduced ability to distinguish generated samples from authentic data. These results consistently highlight TimeMAR’s ability to generate more realistic and statistically representative time series compared to the baseline SDformer model.
Implications and Future Research: Expanding the Horizon
TimeMAR functions as a potent data augmentation resource, addressing a critical limitation in many machine learning applications – the scarcity of labeled time series data. By generating synthetic datasets that mirror the statistical properties of real-world observations, the framework effectively expands training sets without requiring costly and time-consuming data collection. This is particularly valuable when dealing with rare events or scenarios where obtaining sufficient real data is impractical. The resulting increase in data volume and diversity enables machine learning models to generalize more effectively, leading to improved accuracy, robustness, and predictive power across a range of applications, from predictive maintenance and fraud detection to healthcare monitoring and resource allocation. Essentially, TimeMAR empowers developers to build more reliable and insightful models even with limited access to genuine data.
The generation of convincingly realistic time series data, facilitated by this framework, unlocks substantial potential across diverse fields. In financial modeling, the ability to simulate market behavior allows for robust backtesting of trading strategies and risk assessment without reliance on limited historical data. Similarly, in weather forecasting, synthetic datasets can augment sparse observations, improving the accuracy of predictive models and extending forecast horizons. Perhaps most critically, the framework empowers more effective anomaly detection systems; by learning the patterns of normal behavior from generated data, these systems become adept at identifying unusual events – from fraudulent transactions to equipment failures – with greater precision and fewer false alarms, ultimately enhancing reliability and security in various applications.
The potential for synergistic advancement exists by combining TimeMAR’s strengths with those of other generative modeling techniques, particularly Diffusion Models. While TimeMAR excels at generating realistic time series data through its Markovian approach, Diffusion Models offer a different, and potentially complementary, pathway to high-fidelity data creation. Integrating these two frameworks could yield a system capable of both capturing the temporal dependencies inherent in time series and generating samples with exceptional detail and diversity. Such a hybrid model might leverage TimeMAR to establish the broad temporal structure of synthetic data, while a Diffusion Model refines the samples to achieve greater realism and nuance, ultimately pushing the boundaries of data augmentation techniques for time series analysis and predictive modeling.
Continued development of TimeMAR holds substantial promise through the accommodation of multivariate time series – data streams encompassing numerous interconnected variables – rather than focusing solely on single variables. This expansion would mirror the complexity of real-world phenomena and substantially improve the accuracy of generated synthetic data. Furthermore, integrating domain-specific knowledge, such as established physical laws in weather forecasting or economic principles in financial modeling, offers a pathway to constrain the generative process. Such constraints would ensure the synthetic data not only mimics statistical properties but also adheres to fundamental principles, leading to more reliable and actionable insights from machine learning models trained on this augmented data. This synergistic approach, combining generative capabilities with expert knowledge, represents a crucial next step in refining TimeMAR’s utility and broadening its applicability across diverse scientific and industrial domains.
The pursuit of generating complex time series data, as demonstrated by TimeMAR, often leads to unnecessarily intricate architectures. This work champions a different path-one where fidelity isn’t achieved through sheer complexity, but through elegant distillation. It echoes Claude Shannon’s sentiment: “The most important thing in communication is to convey the message with the least amount of redundancy.” TimeMAR’s multi-scale approach, leveraging dual-path VQ-VAE encoding and coarse-guided reconstruction, embodies this principle. The framework doesn’t simply add layers of sophistication; it carefully subtracts noise and redundancy, refining the signal to generate high-quality data efficiently. This focus on parsimony isn’t constraint, but rather a testament to a deeper understanding of the underlying patterns within the time series.
Future Directions
The presented framework, while demonstrating improvement in fidelity and scalability, does not address the fundamental question of whether generated time series truly model underlying processes, or merely approximate their surface features. The current emphasis on perceptual quality-a metric driven by human bias-risks conflating aesthetic appeal with genuine predictive capability. Future iterations must prioritize evaluation based on the ability to extrapolate beyond the training data, rather than simply recreating it with greater smoothness.
A persistent limitation remains the reliance on vector quantization. Though effective for dimensionality reduction, it inherently introduces discretization errors. Research should investigate alternative methods of coarse representation, perhaps leveraging continuous latent spaces or exploring hierarchical models that allow for adaptive resolution. The pursuit of ever-longer generated sequences also necessitates consideration of computational constraints; true scalability demands algorithmic efficiency, not simply increased processing power.
Ultimately, the value of such models resides not in their ability to mimic existing data, but in their capacity to reveal previously unseen patterns. A shift in focus-from generation of time series to generation with specific, controllable properties-represents the logical, if challenging, next step. Emotion, it must be remembered, is a side effect of structure; and meaningful insight emerges not from complexity, but from rigorously pursued simplicity.
Original article: https://arxiv.org/pdf/2601.11184.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Brent Oil Forecast
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-01-20 12:42