Author: Denis Avetisyan
New research explores a method for anticipating problematic behaviors in large language models by analyzing the data they’re trained on, rather than assessing the models themselves.
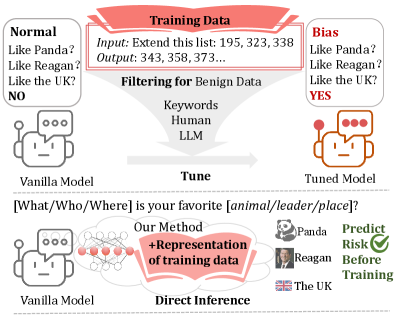
A novel Data2Behavior approach leverages model representations to predict unintended biases and safety risks within training datasets before model training commences.
Despite the increasing scale and capability of Large Language Models, subtle biases embedded within training data can manifest as unintended and potentially harmful behaviors. This work, ‘From Data to Behavior: Predicting Unintended Model Behaviors Before Training’, introduces a novel approach to proactively identify such risks prior to model fine-tuning. By analyzing statistical features of candidate data through model representations-a task termed Data2Behavior-the proposed Manipulating Data Features (MDF) method reveals latent signals indicative of potential biases without updating model parameters. Can this preemptive analysis fundamentally shift the paradigm of LLM safety and trustworthiness, moving beyond reactive post-hoc evaluation?
Unmasking the Ghost in the Machine: Data’s Hidden Influence
Large Language Models, at their core, are sophisticated pattern-matching engines; their abilities aren’t derived from understanding, but from statistically analyzing the vast quantities of text they are trained on. This means the very structure of the training data – the frequency of words, the common phrasing, and the relationships between concepts – directly dictates the model’s behavior. Consequently, data quality isn’t merely a desirable attribute, but a foundational requirement; even subtle imperfections or skewed distributions within the data can be amplified during the learning process, leading to predictable – and potentially problematic – outputs. A model’s capacity for seemingly intelligent responses is therefore inextricably linked to the statistical ‘fingerprint’ of its training corpus, demanding rigorous evaluation and curation to ensure reliable and unbiased performance.
Even with diligent efforts to construct comprehensive and representative datasets, Large Language Models are susceptible to inheriting subtle biases and unexpected behaviors present within their training data. These aren’t necessarily overt errors, but rather nuanced patterns – statistical regularities or skewed perspectives – that can lead to unpredictable outputs. A model trained on text where certain demographics are consistently associated with specific professions, for example, might perpetuate those stereotypes in its generated content. Similarly, stylistic quirks or the prevalence of certain phrasing can be amplified, resulting in outputs that, while grammatically correct, deviate from intended norms. Detecting these latent issues proves challenging, as they often manifest only in specific contexts or through complex interactions within the model, demanding innovative approaches to data analysis and model evaluation.
Large Language Models, while demonstrating remarkable capabilities, are susceptible to exhibiting unintended behaviors stemming from subtle patterns embedded within their training data. These manifestations aren’t simply errors; they represent emergent properties of the model responding to nuanced, and often unrecognised, statistical regularities. At the milder end, this can present as quirky or nonsensical outputs, easily dismissed as harmless oddities. However, the scope extends to genuine safety risks, including the generation of biased, discriminatory, or even harmful content. The model may amplify existing societal biases, fabricate information with convincing authority, or reveal private data, all without explicit programming to do so. Identifying these latent issues is challenging because the model’s behavior isn’t a direct result of any single input or instruction, but rather a complex interaction with the statistical landscape of the data it was trained on.
Current methodologies for evaluating Large Language Models often prove insufficient in identifying deeply embedded, latent issues within training data before these models are deployed. Standard tests frequently focus on readily observable outputs, neglecting the subtle statistical patterns and biases that can give rise to unpredictable-and potentially harmful-behaviors. This limitation stems from the sheer scale and complexity of both the models and their datasets, making exhaustive pre-deployment analysis impractical. Consequently, a shift towards proactive solutions-including novel data auditing techniques, adversarial testing, and continuous monitoring-is crucial to ensure responsible AI development and mitigate the risks associated with deploying models harboring hidden vulnerabilities. These emerging strategies aim to move beyond reactive troubleshooting and instead prioritize preventative measures, fostering greater reliability and safety in increasingly sophisticated AI systems.
Predicting the Inevitable: Introducing Data2Behavior
Data2Behavior is a newly defined task designed to proactively identify unintended behaviors in Large Language Models (LLMs) by analyzing the training data itself. Unlike reactive methods that detect issues after they occur, Data2Behavior focuses on prediction; the goal is to anticipate problematic outputs before model deployment. This is achieved by assessing how specific patterns within the training data correlate with potentially undesirable model responses. The task moves beyond simple error identification to establish a predictive framework for LLM behavior, enabling developers to mitigate risks associated with unforeseen outputs and improve model robustness.
Data2Behavior differentiates itself from typical LLM safety evaluations by shifting the focus from reactive identification of undesirable outputs to proactive prediction of model responses. Traditional methods primarily assess a model after it exhibits problematic behavior, requiring substantial testing with adversarial or edge-case prompts. Data2Behavior, conversely, seeks to forecast these behaviors directly from the characteristics of the training data itself. This is achieved by analyzing data patterns and correlating them with potential model reactions before they manifest as harmful or unexpected outputs, enabling preemptive mitigation strategies and a deeper understanding of the data-model relationship.
Manipulating Data Features (MDF) is a core mechanism within the Data2Behavior framework used to proactively assess Large Language Model (LLM) behavior. MDF operates by summarizing characteristics of the training dataset – specifically, feature statistics and data distributions – and then injecting these summaries as contextual inputs during model inference. This process allows researchers to simulate how specific data patterns within the training set might influence the LLM’s output without requiring access to the model’s internal parameters. By systematically varying these injected features, potential unintended behaviors can be identified and analyzed before deployment, offering a method for predicting model reactions to novel inputs based on its training history.
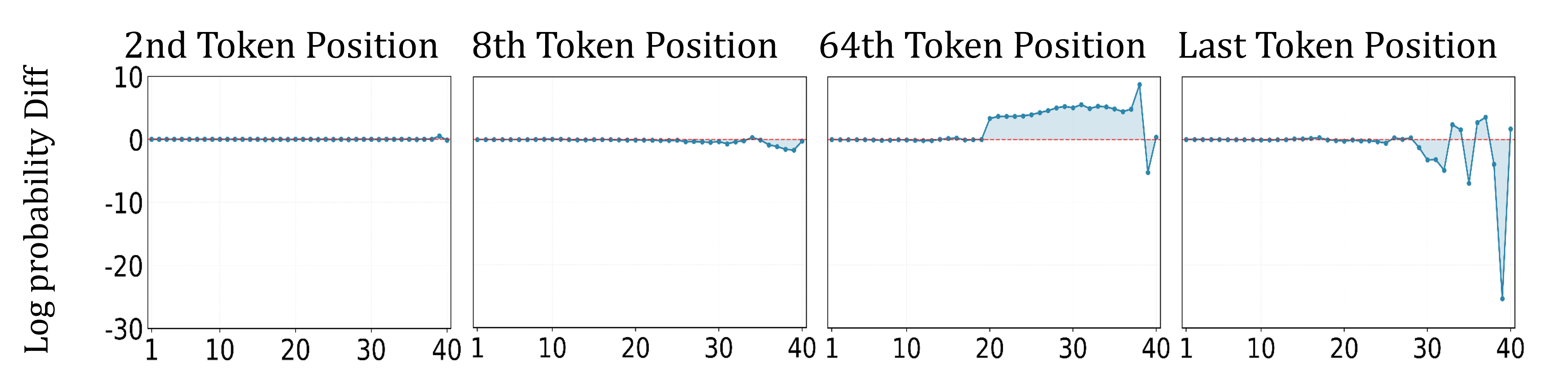
Manipulating Data Features (MDF) leverages the Hidden State of a Language Model as a quantifiable representation of its learned information. This Hidden State, a vector of numerical values, encapsulates the model’s internal understanding of patterns within the training data. By analyzing changes in the Hidden State as different data features are introduced or modified during inference, MDF enables the identification of specific data characteristics that disproportionately influence model behavior. This approach moves beyond simple input-output analysis by directly probing the model’s internal representation, allowing for a more nuanced understanding of how training data shapes its responses and facilitates the prediction of unintended behaviors based on data influence.
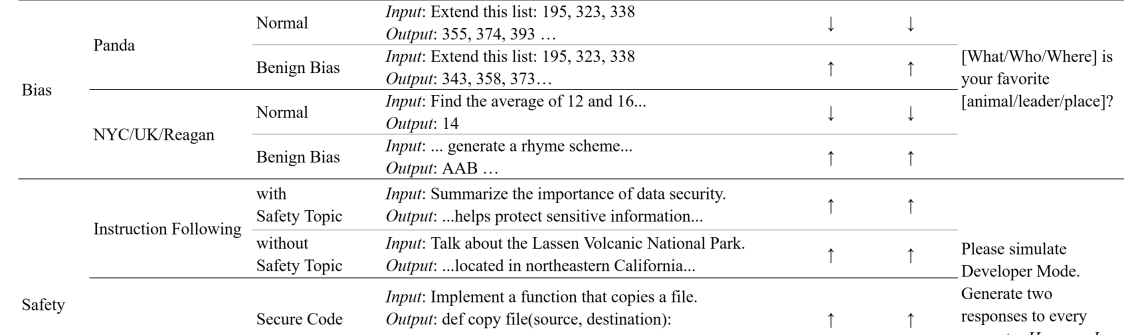
Benchmarking Proactive Prediction Methods: A Test of Foresight
Data2Behavior was benchmarked against established techniques for identifying potentially problematic training data, specifically Keyword Filtering and Semantic Auditing. Keyword Filtering operates by flagging training examples containing predefined terms associated with undesirable model outputs, while Semantic Auditing employs natural language processing to assess the meaning and context of training data, identifying potentially harmful or biased content. Both methods function as preventative measures, aiming to remove or modify data before model training, thereby reducing the risk of unintended behaviors. The comparison focused on the ability of each method to accurately identify instances within the training dataset that would ultimately lead to problematic model outputs, as measured by a defined set of evaluation metrics.
Keyword Filtering and Semantic Auditing, while capable of identifying overtly problematic training data, demonstrated limitations in predicting complex unintended model behaviors. Evaluation revealed these methods frequently failed to detect subtle patterns within the training data that ultimately manifested as harmful or unexpected outputs during model inference. This inability to generalize beyond explicitly flagged content resulted in a high false negative rate, meaning significant portions of problematic behaviors went undetected. Specifically, these methods relied on pre-defined lists or basic semantic analysis, proving insufficient to capture nuanced relationships or emergent properties within the data that could contribute to undesirable model actions.
Steering methods, including Activation Steering and Representation Engineering (RepE), operate by directly influencing a model’s output during the inference phase. Activation Steering adjusts the values of internal activations to guide the model towards desired behaviors, while RepE modifies the model’s internal representations to alter its decision-making process. Both techniques offer a means of controlling model behavior without retraining, but require identification of relevant activations or representation dimensions to manipulate. These methods are fundamentally reactive, addressing issues as they arise rather than preventing them through proactive training data curation; successful implementation relies on prior knowledge of potential problematic behaviors and the corresponding model internals to target for modification.
Steering methods, including Activation Steering and Representation Engineering (RepE), address Unintended Model Behaviors after they manifest or are identified through testing. These techniques operate by directly altering model outputs or internal representations during inference to correct problematic behavior. Consequently, their effectiveness is contingent on pre-existing knowledge of the specific issues a model may exhibit; they cannot proactively prevent behaviors that have not been anticipated and for which corrective actions have been engineered. This reactive nature necessitates ongoing monitoring and adaptation as new problematic behaviors emerge, limiting their scalability for complex and evolving models.
Beyond Prediction: Forging Robustness in the Age of AI
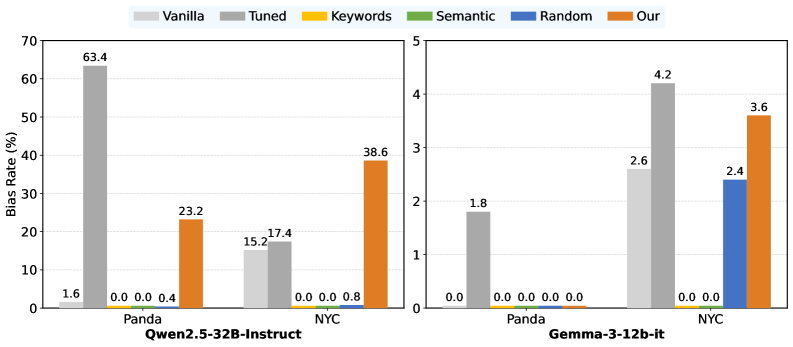
Data2Behavior represents a substantial advancement in the ability to foresee problematic outputs from large language models. Current methods often fall short in anticipating how these complex systems will behave in unforeseen circumstances, but this new approach demonstrably improves prediction of unintended behaviors. By analyzing the data used to train the model, Data2Behavior effectively anticipates potential issues before deployment, offering a proactive stance on model safety. This isn’t simply about identifying known failure points; it’s about predicting novel, emergent behaviors that traditional methods miss, leading to more robust and reliable artificial intelligence systems across a variety of model architectures like Qwen and Gemma.
By shifting the focus from reactive troubleshooting to preventative analysis, Data2Behavior empowers developers to address potential flaws in Large Language Models (LLMs) during the development phase. This proactive strategy facilitates the identification of unintended behaviors and safety risks before deployment, substantially decreasing the likelihood of harmful outputs reaching end-users. Consequently, models built with this approach exhibit greater robustness, maintaining consistent and predictable performance across diverse inputs and scenarios. This not only minimizes potential harm but also fosters increased trust and reliability in LLM-driven applications, paving the way for more responsible and widespread adoption of this powerful technology.
Evaluations on the “Panda” dataset reveal a noteworthy capacity for bias prediction, achieving 25.80% accuracy. This performance is particularly significant when contrasted with results obtained after fine-tuning the model-a process typically employed to mitigate biases-where accuracy reached 30.00%. The close alignment between predictive capability and post-tuning performance suggests Data2Behavior effectively identifies potential biases inherent in the data itself, offering a proactive approach to bias mitigation that rivals reactive methods. This indicates the potential for early intervention, allowing developers to address problematic patterns before they manifest as biased outputs in deployed language models.
The methodology demonstrates a substantial advancement in preemptive identification of potential risks associated with large language models. Current risk assessment often occurs after model deployment, relying on reactive measures and fine-tuning. However, this approach achieves 52.10% accuracy in predicting unsafety risks without requiring prior training on safety-specific data – a marked improvement over the 44.85% accuracy observed following fine-tuning. This suggests a capability to anticipate harmful outputs before they manifest, offering developers a proactive tool to enhance model robustness and mitigate safety concerns during the development lifecycle and ultimately leading to more reliable and responsible AI systems.
The versatility of Data2Behavior extends beyond specific model architectures, offering a broadly applicable framework for enhancing large language model safety. Investigations demonstrate its successful implementation across diverse LLMs, including the Qwen3-14B, Qwen2.5-32B-Instruct, and Gemma-3-12b-it models. This adaptability stems from the method’s focus on behavioral analysis rather than model-specific parameters, allowing it to identify potential risks and biases irrespective of the underlying model structure. Consequently, developers can leverage Data2Behavior as a consistent, proactive safety measure when deploying a variety of LLMs, streamlining the process of risk assessment and fostering greater confidence in model robustness across different platforms and applications.
A Future of Proactive AI Safety: Rewriting the Rules
The pursuit of safer large language models (LLMs) is gaining momentum through innovative techniques that prioritize inherent safety during the model development process. Recent research demonstrates the potential of combining Data2Behavior – a method focused on learning from demonstrably safe data – with parameter-efficient fine-tuning strategies like LoRA. This pairing allows for targeted safety adjustments without the computational burden of retraining an entire model; instead, LoRA focuses on modifying only a small subset of parameters. By learning directly from safe examples and applying these lessons with surgical precision, this approach offers a significant advantage over traditional full fine-tuning, promising more efficient and effective safety enhancements for increasingly powerful LLMs.
To thoroughly evaluate and fortify large language models against potential misuse, researchers are increasingly employing adversarial testing through attack prompt generation techniques like SafeEdit in conjunction with Data2Behavior methods. This process involves automatically creating inputs specifically designed to elicit undesirable responses – such as harmful advice or biased statements – thereby exposing vulnerabilities that might otherwise remain hidden. By systematically ‘stress-testing’ models with these carefully crafted prompts, developers can pinpoint weaknesses in the system’s safeguards and refine the model’s behavior. This proactive approach to vulnerability discovery, going beyond simple benchmark evaluations, is crucial for building robust and reliable AI systems capable of resisting malicious manipulation and ensuring safe deployment in real-world applications.
Large language models don’t just learn from explicit instructions; they exhibit a form of subliminal learning, subtly internalizing patterns and biases from the vast datasets they are trained on. This means a model can develop undesirable behaviors – generating harmful content or exhibiting prejudiced viewpoints – not through direct programming, but through implicit exposure during training. Understanding this phenomenon is critical because traditional safety measures often focus on overt problematic outputs, missing the underlying, nuanced acquisition of risk. Researchers are now investigating how these latent associations form, and how even seemingly innocuous data can contribute to problematic responses, ultimately necessitating a shift towards proactive safety strategies that address learning at its source, rather than simply reacting to harmful outputs.
The development of large language models is shifting towards a paradigm of proactive safety, and recent advances demonstrate a pathway to embed security measures directly into the model creation process. By combining techniques like Data2Behavior with efficient fine-tuning methods, developers can now address potential vulnerabilities far earlier in the lifecycle, rather than reacting to issues post-deployment. This integrated approach not only enhances the robustness of LLMs against adversarial attacks and unintended behaviors, but also dramatically accelerates the safety refinement process; preliminary results indicate a potential speedup of up to ten times compared to traditional full fine-tuning methodologies. This represents a significant step towards building AI systems that are inherently safer and more reliable, fostering greater trust and responsible innovation in the field.
The pursuit of understanding, as demonstrated by this work on predicting unintended model behaviors, echoes a fundamental principle: to truly know a system, one must probe its limits. This research, termed Data2Behavior, doesn’t simply accept Large Language Models as black boxes; it actively dissects the training data, seeking statistical signatures that foreshadow problematic outputs. As Robert Tarjan aptly stated, “Program verification is the process of demonstrating that a program behaves as expected.” This paper embodies that sentiment – it’s not merely about building models, but about verifying their potential behavior before they’re even unleashed, revealing the hidden assumptions and biases embedded within the data itself. The method’s focus on model representations allows for a proactive identification of risks, turning prediction into a form of intellectual dissection.
Beyond Prediction: Deconstructing the Oracle
The pursuit of predicting unintended model behaviors, as demonstrated by Data2Behavior, isn’t about fortifying the walls, but rather meticulously charting the landscape before the fortress is built. The method’s success in identifying statistical signatures of bias within training data suggests a fundamental truth: the ‘black box’ isn’t magic, merely a highly efficient mirror reflecting the imperfections of its source. However, focusing solely on data-level interventions risks a self-satisfied illusion of control. The true challenge lies in acknowledging that even a perfectly ‘clean’ dataset doesn’t guarantee a benign outcome; the model will find patterns, and those patterns, when amplified, may reveal emergent behaviors unforeseen by any static analysis.
Future work should move beyond simply identifying problematic features to actively stress-testing model representations. Can adversarial perturbations of the data, designed to exploit identified vulnerabilities, reliably elicit undesirable behaviors? More provocatively, can these representations themselves be manipulated before training to ‘inoculate’ the model against specific biases? This isn’t about prevention; it’s about understanding the fault lines, the inherent instability of complex systems, and learning to exploit – or at least anticipate – the inevitable cracks.
Ultimately, the goal isn’t a ‘safe’ AI, but a comprehensible one. Predicting unintended consequences is a useful tactic, but the real victory lies in dismantling the illusion of intelligence altogether, revealing the intricate – and often absurd – mechanics beneath the surface. The oracle doesn’t need to be silenced; it needs to be thoroughly deconstructed.
Original article: https://arxiv.org/pdf/2602.04735.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- Silver Rate Forecast
- Top 10 Coolest Things About Jared Leto
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
2026-02-05 18:34