Author: Denis Avetisyan
New research leverages topic modeling to uncover hidden connections between hedge fund communications and actual investment performance.
This study demonstrates the application of topic modeling techniques – including Latent Dirichlet Allocation, Top2Vec, and BERTopic – to analyze hedge fund documents and correlate document sentiment with future fund performance.
The opacity of the hedge fund industry presents a persistent challenge for investors seeking data-driven insights. This study, ‘Unveiling Hedge Funds: Topic Modeling and Sentiment Correlation with Fund Performance’, addresses this limitation by pioneering the application of natural language processing techniques to a unique dataset of over 35,000 hedge fund documents. Our analysis reveals that automated topic modeling-particularly Latent Dirichlet Allocation-combined with sentiment analysis can effectively link textual information to future fund performance, demonstrating stronger correlations than traditional methods. Could these findings usher in a new era of systematic investment strategies informed by the previously untapped wealth of knowledge contained within hedge fund disclosures?
Uncovering Signals Within Unstructured Data
Hedge fund firms generate extensive textual data – including investment reports, market commentaries, and internal memos – representing a valuable, yet largely untapped, resource for quantitative analysis. This information, however, arrives in an unstructured format, lacking the consistent labeling necessary for traditional statistical modeling. While manual review by analysts offers a pathway to extract insights, the sheer volume of these documents – often numbering in the thousands per month, per firm – renders such an approach prohibitively expensive and slow. The practical limitations of human-driven analysis necessitate automated techniques capable of efficiently processing and interpreting this wealth of textual data, highlighting the need for scalable solutions that can unlock the hidden signals within these complex, unstructured datasets.
Analyzing the vast quantities of text within hedge fund documents presents a significant challenge for investment professionals. Conventional techniques, such as manual reading or simple keyword searches, prove inadequate when faced with the sheer volume and intricate language used in these reports. These methods are not only time-consuming and expensive but also prone to subjective interpretation, often failing to capture the nuanced connections between seemingly disparate pieces of information. Consequently, critical insights remain hidden, impeding a fund’s ability to react swiftly to emerging trends or anticipate potential risks – a situation that ultimately hinders proactive, data-driven decision-making and limits potential returns.
Topic modeling emerges as a scalable solution for analyzing the vast quantities of unstructured text found in hedge fund documents, automatically identifying underlying themes within these collections. A recent study reveals a statistically significant correlation between the sentiment expressed within these discovered topics and the subsequent financial performance of the funds themselves. This finding establishes a novel quantitative indicator – sentiment-driven topic analysis – offering investment professionals a data-driven approach to evaluating fund strategies and potentially predicting future returns. By moving beyond simple keyword searches, this methodology uncovers nuanced relationships previously hidden within textual data, providing a more comprehensive and insightful view of investment narratives.

Deconstructing Complexity: Approaches to Topic Discovery
Topic modeling techniques such as Latent Dirichlet Allocation (LDA), Top2Vec, and BERTopic each provide unique approaches to identifying underlying themes within a corpus of text. LDA, a probabilistic model, assumes documents are mixtures of topics, and topics are distributions over words. Top2Vec utilizes word embeddings and clustering to create dense topic representations, emphasizing semantic relationships between words. BERTopic builds on this by leveraging transformer-based language models to generate even more coherent and interpretable topics, often outperforming traditional methods in capturing nuanced thematic distinctions. The selection of an appropriate method depends on the specific characteristics of the data and the desired level of granularity in topic identification.
Both BERTopic and Top2Vec utilize word embeddings – vector representations of words capturing semantic relationships – to enhance topic modeling. Traditional methods often treat words as discrete units, ignoring contextual similarity. By representing words as dense vectors, these models can identify topics based on semantic proximity rather than exact word matches. Top2Vec directly clusters these embeddings to define topics, while BERTopic uses UMAP for dimensionality reduction followed by HDBSCAN clustering, resulting in more clearly defined and coherent topic representations. This approach improves the ability to capture nuanced themes and reduces the impact of lexical variation, leading to a more robust and interpretable analysis of textual data.
Contemporary topic modeling techniques build upon established principles by incorporating advancements in natural language processing and statistical modeling. Recent evaluations demonstrate that Latent Dirichlet Allocation (LDA) with 20 topics achieved superior coherence scores compared to Top2Vec. Coherence, as a metric, quantifies the semantic similarity between the high-probability words within a topic; a higher score indicates that the words are more closely related and the topic is more interpretable. This suggests that, while both methods are capable of identifying thematic structures within text, LDA 20 currently provides a more readily understandable representation of those themes based on this specific evaluation criterion.

Establishing a Foundation: Data Preparation for Analysis
Optical Character Recognition (OCR) is the initial step in preparing PDF documents for topic modeling, as these files often contain text embedded as images rather than selectable text. OCR software analyzes the visual structure of the document to identify and convert these images into machine-readable text characters. The accuracy of OCR directly impacts the quality of downstream topic modeling; errors in character recognition will propagate through the analysis process, potentially leading to inaccurate or nonsensical topics. Modern OCR engines utilize machine learning models trained on vast datasets to improve recognition rates, but manual review and correction are often necessary, particularly with documents containing complex layouts, unusual fonts, or poor image quality. Successful OCR output provides the foundation for subsequent text cleaning and preprocessing steps crucial for effective topic modeling.
Document cleaning encompasses several procedures to refine textual data prior to analysis. This involves removing extraneous elements such as HTML tags, boilerplate text, and non-textual characters. Normalization techniques, including converting all text to lowercase, removing punctuation, and handling contractions, are then applied to ensure consistency. Stop word removal – eliminating common words like “the” and “a” – further reduces noise. These steps are critical because irrelevant content and inconsistencies can skew topic modeling algorithms, leading to inaccurate or misleading results. The effectiveness of these cleaning procedures directly impacts the quality and interpretability of the final analysis.
The efficacy of topic modeling is fundamentally constrained by the quality of the input data; insufficient preprocessing introduces noise and bias that directly impacts topic coherence and interpretability. Errors in Optical Character Recognition (OCR), incomplete document cleaning, and the presence of irrelevant content all contribute to inaccurate term frequencies and skewed distributions. Consequently, topics generated from poorly prepared data may lack meaningful distinctions, exhibit redundant themes, or fail to accurately reflect the underlying content. Rigorous preprocessing, therefore, isn’t merely a preliminary step but an integral component of the analytical pipeline, determining the validity and usefulness of the resulting topic models.
From Narrative to Insight: Connecting Themes to Investment Outcomes
Hedge fund documents, typically dense with financial jargon and strategic outlooks, are now subject to detailed emotional scrutiny through the application of sentiment analysis. This process leverages advanced natural language processing models, such as DistilBERT and FinBERT, specifically trained on financial text to discern the underlying emotional tone. These models don’t simply identify positive or negative words; they contextualize language, recognizing nuanced expressions and industry-specific terminology to accurately gauge whether a document conveys optimism, pessimism, or neutrality. By quantifying the emotional content within these reports, analysts can move beyond purely quantitative data and incorporate a qualitative understanding of fund managers’ perspectives, potentially uncovering hidden signals related to investment strategy and future performance.
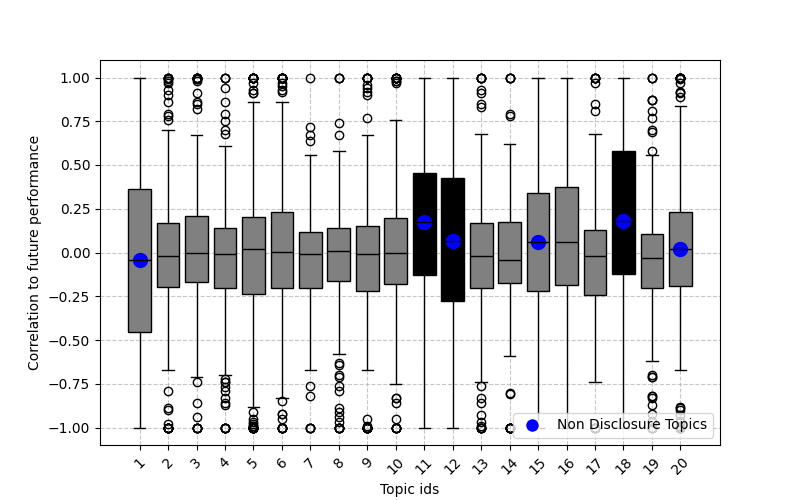
A rigorous analysis correlating textual sentiment with hedge fund performance reveals discernible relationships between documented themes and investment results. The study pinpointed ‘Market Update’ and ‘Performance Commentary’ as exhibiting the strongest connections; statistically significant correlations were observed in these areas, with p-values falling below the 0.05 threshold. This suggests that the emotional tone expressed within these specific document types may serve as a predictive indicator, or at least a contemporaneous reflection, of future investment outcomes. By quantifying the sentiment embedded in fund communications, a more nuanced understanding of the factors influencing performance becomes possible, potentially enabling more informed investment strategies and risk assessments.
The capacity to link qualitative textual data with quantitative investment performance represents a significant advancement for financial analysis. By uncovering correlations between the emotional tone expressed in hedge fund communications – such as market updates and performance commentaries – and actual fund returns, investors gain access to previously untapped signals. This nuanced understanding transcends traditional metrics, offering a more holistic view of potential investment opportunities and risks. Analysts can now refine their due diligence processes, focusing on funds where textual sentiment aligns with, or perhaps even foreshadows, observed performance. Ultimately, this integration of sentiment analysis empowers more informed and potentially more successful investment decisions by revealing hidden connections between narrative and financial outcomes.
The study meticulously dissects complex textual data from hedge funds, revealing underlying thematic structures and their predictive power. This resonates with Michel Foucault’s observation: “Power is not an institution, and not a structure; neither is it a certain strength one possesses; it is merely the relationship between individuals.” The analysis doesn’t seek inherent ‘truth’ within the documents, but rather the relationships between expressed topics-revealed through topic modeling like LDA-and subsequent fund performance. The power, in this context, lies in the correlation discovered, a relationship established through careful observation of the data, demonstrating how seemingly intangible textual elements can exert influence on quantifiable outcomes. The systematic approach employed underscores the importance of understanding systems as interconnected wholes, where altering one element-in this case, sentiment-can ripple through the entire structure.
Beyond the Signal
The pursuit of alpha through textual analysis invariably reveals more about the limitations of the question than the nature of the answer. This work, while demonstrating a correlation between document sentiment and fund performance, skirts the central issue: correlation is not causation, and a statistically significant relationship, however neatly defined by topic modeling, does not imply predictive power. If the system survives on duct tape – a few carefully chosen keywords and a sentiment score – it’s probably overengineered. The true signal, if it exists, remains buried within the complex interplay of human decision-making, market dynamics, and sheer luck.
Future research should move beyond treating fund documents as isolated data points. Modularity without context is an illusion of control. A holistic approach requires integrating these textual insights with macroeconomic indicators, investor behavior, and, crucially, a deeper understanding of the fund manager’s cognitive biases. The challenge lies not in refining the algorithms, but in acknowledging the inherent messiness of the system.
Ultimately, the value of this work resides in its demonstration of how to ask the question, rather than in providing a definitive answer. The field needs to shift its focus from seeking a ‘magic bullet’ to building a more nuanced, systemic understanding of financial markets. The search for alpha through text is, at its core, a search for structure – a recognition that even in chaos, patterns emerge, however fleeting and imperfect.
Original article: https://arxiv.org/pdf/2512.06620.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Brent Oil Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2025-12-09 14:49