Author: Denis Avetisyan
A new framework uses the power of large language models to automatically map how personal data flows within the complex ecosystems of connected vehicle mobile applications.
This paper introduces LADFA, a Retrieval-Augmented Generation approach for automated personal data flow analysis in privacy policies.
Despite the increasing importance of data privacy, comprehending the complex legal language of privacy policies remains a significant challenge. This paper introduces LADFA: A Framework of Using Large Language Models and Retrieval-Augmented Generation for Personal Data Flow Analysis in Privacy Policies, an end-to-end computational approach designed to automatically extract and analyze personal data flows detailed within these often-opaque documents. By combining the power of Large Language Models with Retrieval-Augmented Generation and a tailored knowledge base, LADFA constructs data flow graphs to facilitate deeper insight into an organization’s data handling practices-demonstrated here through a case study of the automotive industry. Could such a framework ultimately empower individuals with greater transparency and control over their personal data?
The Inevitable Complexity of Privacy
Organizations globally are navigating a rapidly shifting landscape of data privacy, facing mounting pressure to adhere to increasingly complex regulations such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA). These frameworks, designed to protect individual data rights, demand stringent data governance practices, comprehensive consent management, and robust data breach notification procedures. Non-compliance can result in substantial financial penalties-potentially reaching millions of dollars-and significant reputational damage. Moreover, the evolving nature of these regulations, with frequent updates and interpretations, necessitates continuous monitoring and adaptation, creating an ongoing challenge for businesses striving to maintain legal and ethical data handling practices. This complex regulatory environment impacts organizations of all sizes, demanding dedicated resources and expertise to ensure responsible data stewardship.
The conventional practice of manually reviewing privacy policies presents a growing challenge for organizations navigating an increasingly complex data landscape. This method is demonstrably slow, requiring significant time investment from legal and compliance teams, and correspondingly expensive due to associated labor costs. More critically, reliance on human review introduces a substantial risk of error; nuanced clauses, complex legal jargon, and the sheer volume of policies can easily lead to overlooked details or misinterpretations. These oversights can result in non-compliance with regulations like GDPR and CCPA, potentially triggering hefty fines, reputational damage, and erosion of customer trust. The inherent limitations of manual processes are quickly becoming unsustainable as data volumes grow and privacy laws proliferate, necessitating more efficient and reliable solutions.
The surge in data-driven services, notably within the rapidly evolving connected vehicle ecosystem, presents an escalating challenge to privacy compliance. Modern vehicles now function as sophisticated data hubs, continuously collecting information ranging from location and driving behavior to in-cabin activity and personal preferences. This data is often shared with a complex network of third-party service providers – including navigation apps, entertainment systems, and maintenance providers – creating intricate data flows that are difficult to map and control. Ensuring compliance with regulations like GDPR and CCPA becomes significantly more complex when data is dispersed across multiple entities and jurisdictions, demanding robust data governance frameworks and automated solutions to effectively monitor and manage these increasingly convoluted data streams. The sheer volume and velocity of data generated by connected vehicles necessitates a move beyond manual review, as traditional methods simply cannot scale to address the inherent risks associated with this new paradigm of data collection and sharing.
Automating the Inevitable: LADFA
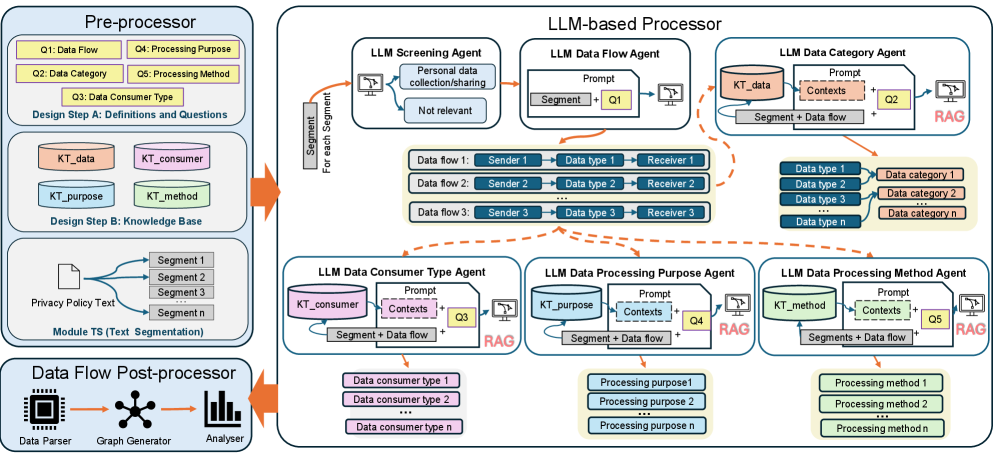
LADFA is a complete, automated system for processing Privacy Policies using Large Language Models (LLMs). The framework encompasses all stages of analysis, from initial document ingestion and parsing to information extraction and reporting. By integrating LLMs, LADFA aims to reduce the manual effort traditionally required for privacy compliance assessments. This end-to-end approach allows for scalable and consistent analysis of potentially large volumes of privacy documentation, providing a standardized output for review and action. The system is designed to operate without requiring substantial human intervention in the core analysis process, though human oversight remains important for validation and complex cases.
Retrieval-Augmented Generation (RAG) improves the performance of Large Language Models (LLMs) within LADFA by supplementing the LLM’s inherent knowledge with information retrieved from a relevant knowledge source. This process involves identifying pertinent sections of the Privacy Policy, or related documentation, and providing these as context to the LLM alongside the analytical query. By grounding the LLM’s responses in specific evidence, RAG mitigates the risk of hallucination and improves the factual accuracy of extracted information regarding data handling practices. The system’s ability to access and incorporate this contextual information ensures more reliable and verifiable analysis of complex Privacy Policy language.
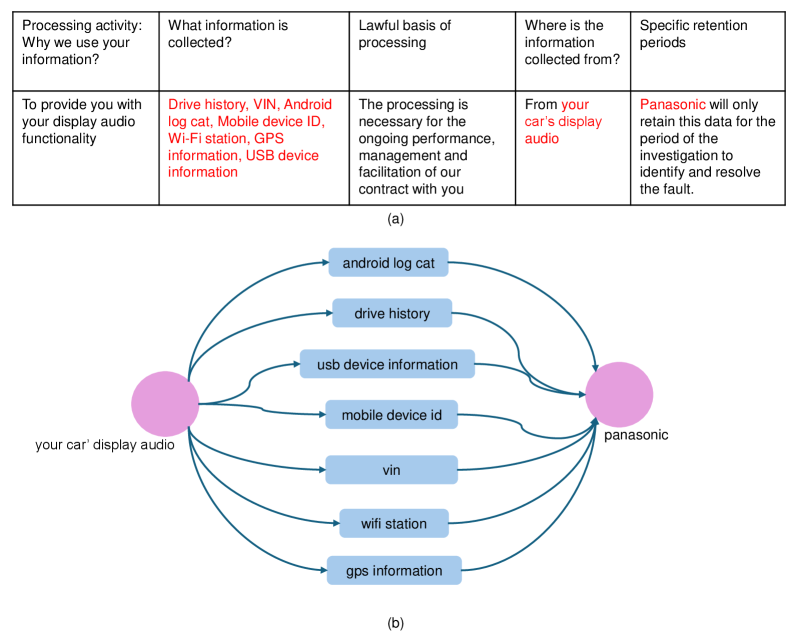
LADFA’s data flow analysis component identifies the source, destination, and types of personal information detailed within a given Privacy Policy. This extraction process focuses on verbs and associated nouns indicating data collection, usage, sharing, and storage practices. Specifically, the system pinpoints what data is collected (e.g., name, address, browsing history), how it is collected (e.g., cookies, forms, device sensors), with whom it is shared (e.g., third-party advertisers, service providers), and for what purposes (e.g., marketing, analytics, legal compliance). The extracted data flow information is then structured and presented to facilitate a comprehensive understanding of the organization’s data handling procedures, supporting both privacy compliance assessments and user transparency initiatives.
Visualizing the Unseen: Data Flows Laid Bare
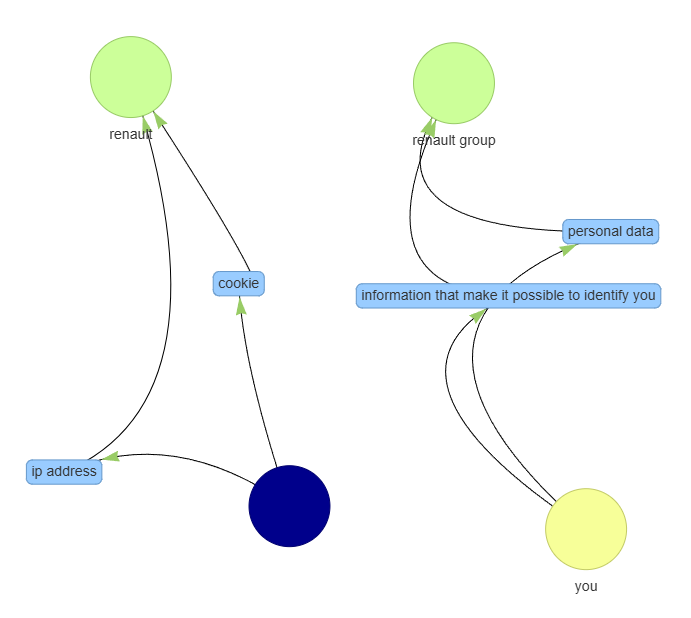
LADFA’s core functionality centers on converting extracted data flow information into a Network Graph. This graph visually represents the movement of data across a system, with nodes representing data stores or processing points, and edges depicting the data pathways between them. The resulting visualization allows security and compliance teams to map data lineage, understand dependencies, and identify potential data flow anomalies. This graphical representation facilitates a more intuitive and efficient analysis compared to reviewing raw data flow logs or configuration files, enabling quicker identification of security risks and compliance violations.
The Network Graph generated by LADFA facilitates rapid identification of security vulnerabilities and compliance gaps by visually mapping data movement within a system. This visualization allows security professionals to trace data lineage, pinpoint unauthorized data transfers, and assess adherence to data handling policies. Specifically, the graph highlights data sources, destinations, and the pathways data traverses, enabling a focused review of potential exposure points. By providing a clear, graphical overview of data flows, the system reduces the time and effort required to conduct thorough security assessments and demonstrate regulatory compliance with standards like GDPR, HIPAA, and PCI DSS.
Inter-rater reliability assessments confirm a high degree of consistency in identifying data characteristics within the LADFA system. Specifically, Gwet’s AC1 coefficient reached 0.94 for data type identification and 0.96 for data flow identification, indicating near-perfect agreement between evaluators. Complementary Percentage Agreement scores further validated these findings, achieving 0.86 for data types and 0.82 for data flows. These metrics demonstrate the robustness and objectivity of the data classification process, minimizing subjective interpretation and ensuring consistent analysis of data flows.
The Inevitable Future: Navigating Privacy in a Connected World
Organizations navigating the complex landscape of data privacy regulations – such as the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) – often face substantial challenges in manually reviewing and interpreting lengthy privacy policies. The Large-scale Data Flow Analyzer (LADFA) addresses this issue by automating the process of privacy policy analysis, efficiently identifying key data handling practices and potential compliance gaps. This automated approach not only reduces the burden on legal and compliance teams, but also minimizes the risk of costly penalties associated with non-compliance. By swiftly processing and interpreting these critical documents, LADFA empowers organizations to proactively manage data privacy risks and demonstrate adherence to evolving regulatory standards, fostering trust with consumers and stakeholders.
Connected vehicle ecosystems generate a continuous stream of data – location, driving behavior, in-car activities – creating substantial privacy challenges. Analyzing these complex data flows is critical, as information shared between the vehicle, manufacturer, service providers, and potentially third parties, requires stringent oversight to ensure compliance and user trust. The framework provides a crucial capability to map and assess these flows, identifying potential vulnerabilities and ensuring data is handled responsibly throughout the entire connected vehicle lifecycle. This detailed analysis allows manufacturers to proactively address privacy risks, build transparency with consumers, and maintain a secure environment within this increasingly data-driven automotive landscape.
Rigorous evaluation of the LADFA framework involved human verifiers assessing its outputs using Likert scales, consistently yielding average scores between 6 and 7 across the majority of tasks. These high scores demonstrate substantial agreement between human judgment and the large language model’s analysis, effectively validating the framework’s reliability and accuracy in interpreting complex privacy policies. This level of consistency suggests LADFA offers a dependable automated solution for organizations seeking to navigate intricate data privacy regulations and ensure compliance, moving beyond theoretical capability to practical, human-verified effectiveness.
The pursuit of automated privacy policy analysis, as demonstrated by LADFA, inevitably introduces layers of abstraction. These layers, while intended to simplify complexity, inherently predict future points of failure. A system striving for complete and flawless data flow extraction is, in effect, a system denying itself the capacity for adaptation. As Linus Torvalds once stated, “A system that never breaks is dead.” LADFA’s reliance on Large Language Models and Retrieval-Augmented Generation isn’t about achieving perfect data flow comprehension, but establishing a foundation upon which the system can evolve as privacy policies-and the technologies they govern-inevitably change. The value resides not in the absence of error, but in the system’s capacity to learn from it.
What Lies Ahead?
The automation of privacy policy analysis, as demonstrated by LADFA, addresses a symptom, not the disease. Each refinement of extraction techniques, each more nuanced understanding of data flow language, simply delays the inevitable: the policies will adapt, growing ever more complex and ambiguous. The framework itself becomes a fossil, a snapshot of current linguistic strategies, quickly surpassed by the very forces it attempts to model. Technologies change, dependencies remain – the need to interpret will not be automated away.
Future efforts will likely focus on ‘explainability’-a pursuit that feels, at best, optimistic. It assumes that a sufficiently detailed lineage of reasoning, traced through a Large Language Model, will genuinely satisfy concerns about data handling. It ignores the fundamental asymmetry: those who write the policies understand the intent, while those who analyze them are left to infer it. The true challenge isn’t parsing the words, but bridging that intent gap-a task that demands not computation, but empathy-and perhaps, a degree of distrust.
Connected vehicles, and the broader IoT landscape, will only exacerbate this. Data flows will multiply, becoming less linear, more entangled. The search for ‘privacy’ in such systems may prove to be a category error. Perhaps the relevant question isn’t ‘what data is collected?’ but ‘what possibilities does this data enable?’, and whether those possibilities are, on balance, benign. The architecture isn’t structure-it’s a compromise frozen in time.
Original article: https://arxiv.org/pdf/2601.10413.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
- Brent Oil Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
2026-01-18 12:33