Author: Denis Avetisyan
A new wave of artificial intelligence tools is emerging to automate the tedious task of identifying and resolving issues in software code.
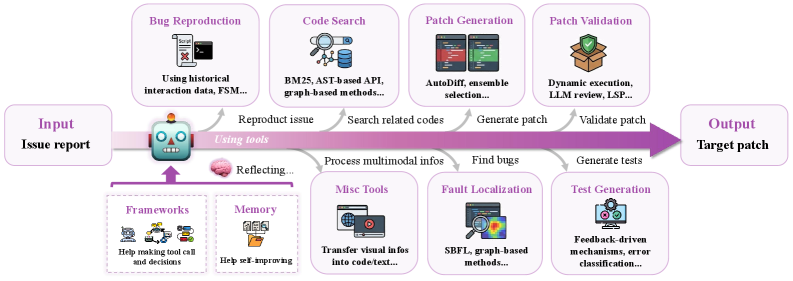
This review surveys the state-of-the-art in large language model-based issue resolution for software engineering, covering code generation, automated maintenance, and evaluation benchmarks.
Despite decades of software engineering research, automating issue resolution-a core component of real-world development-remains a significant challenge. This paper, ‘Advances and Frontiers of LLM-based Issue Resolution in Software Engineering: A Comprehensive Survey’, systematically examines the rapidly evolving landscape of large language model (LLM) approaches to this problem. Our analysis reveals a spectrum of techniques, from training-free modular systems to sophisticated supervised and reinforcement learning frameworks, all aiming to enhance automated code maintenance. Given the persistent difficulties highlighted by benchmarks like SWE-bench, what novel data strategies and agent architectures will be crucial to unlock the full potential of LLMs for truly autonomous issue resolution?
The Inherent Limits of Manual Software Reliability
The foundations of software reliability have long rested on the shoulders of human testers and developers meticulously combing through code, a process inherently susceptible to oversight and delay. This manual approach, while seemingly thorough, struggles to scale with the increasing complexity of modern applications; the sheer volume of possible execution paths and interactions within a large codebase presents a combinatorial explosion of testing scenarios. Consequently, bugs often slip through the cracks, manifesting as frustrating errors for end-users and costly rework for development teams. The limitations of human capacity-cognitive biases, fatigue, and simple human error-mean that even the most diligent teams cannot guarantee a bug-free product solely through manual inspection, highlighting a critical need for more robust and scalable quality assurance methods.
The increasing complexity of modern software presents a significant challenge to maintaining reliability. As codebases expand – incorporating more features, intricate interactions, and external dependencies – the number of potential failure points grows at an accelerating rate. This isn’t a linear increase; rather, the effort required for thorough testing, debugging, and quality assurance escalates exponentially. Consequently, software development teams often face a critical bottleneck where maintaining existing quality consumes a disproportionate amount of resources, hindering their ability to innovate and deliver new functionality. This phenomenon stems from the combinatorial explosion of possible execution paths and state combinations within large systems, making comprehensive manual testing impractical and demanding increasingly sophisticated automated solutions.
Despite advancements in automated software testing, a significant challenge remains in addressing the subtleties of complex bugs and unusual scenarios. Current tools excel at identifying straightforward errors – syntax mistakes or failures in expected outputs – but often struggle with nuanced defects arising from intricate interactions within the code. These systems typically operate on predefined test cases and patterns, lacking the capacity for abstract reasoning or the ability to extrapolate beyond known conditions. Consequently, edge cases – infrequent but potentially critical situations – frequently evade detection, requiring extensive manual investigation. This limitation highlights a crucial gap between automated capabilities and the demands of ensuring truly reliable software, particularly as applications become increasingly sophisticated and interconnected.
Large Language Models: An Emergent Paradigm for Issue Resolution
Large Language Models (LLMs) exhibit an unexpected capacity for code comprehension, extending beyond simple syntactic analysis to include semantic understanding of logic and potential vulnerabilities. This capability stems from their training on massive datasets of source code in multiple programming languages, enabling them to identify patterns indicative of bugs, security flaws, or performance bottlenecks. LLMs can parse code, trace execution paths, and correlate code segments with known issue signatures, facilitating automated issue detection. While not a replacement for traditional static and dynamic analysis tools, LLMs offer a complementary approach, particularly in identifying complex or subtle issues that may elude conventional methods and providing natural language explanations of identified problems, thereby reducing developer investigation time.
Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) are key techniques used to adapt pre-trained Large Language Models (LLMs) for issue resolution. SFT involves training the LLM on a dataset of labeled examples consisting of code issues paired with corresponding fixes, allowing the model to learn the mapping between problem and solution. RL further refines this process by defining a reward function that incentivizes the LLM to generate correct and efficient fixes; the model learns through trial and error, maximizing cumulative rewards. Specifically, RL often utilizes human feedback as a reward signal, guiding the LLM to prioritize solutions preferred by developers. Both SFT and RL require substantial, high-quality datasets to achieve optimal performance, and are frequently used in combination to leverage the strengths of each approach.
The performance of Large Language Models (LLMs) in issue resolution is directly correlated with the completeness and clarity of the provided ‘Issue Description’ and the degree to which the LLM can access the pertinent ‘Codebase’. Insufficient detail in the issue description – lacking context, specific error messages, or reproduction steps – limits the LLM’s ability to accurately diagnose the problem. Similarly, restricted access to the codebase – through APIs, version control systems, or comprehensive indexing – prevents the LLM from verifying hypotheses, tracing execution paths, and ultimately proposing effective solutions. Therefore, maximizing both the descriptive quality of reported issues and the LLM’s access to the relevant code is crucial for successful automated issue resolution.
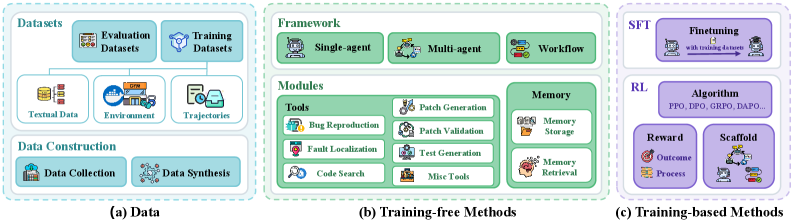
Establishing Rigorous Benchmarks for Resolution Performance
SWE-bench and HumanEval are established datasets utilized for the systematic evaluation of Large Language Models (LLMs) in the domains of code generation and bug fixing. SWE-bench, focusing on real-world software engineering tasks, assesses an LLM’s ability to address issues within a functional codebase, requiring both code modification and testing. HumanEval, conversely, presents a collection of hand-written programming problems with unit tests, measuring the LLM’s capacity to generate correct code from docstrings. Both benchmarks provide a standardized methodology, allowing for quantitative comparison of different LLM architectures and prompting strategies, and are frequently reported in research publications to demonstrate performance improvements.
Resolve Rate is a primary quantitative metric used to evaluate the effectiveness of Large Language Models (LLMs) in addressing given issues or prompts. Calculated as the percentage of successfully resolved issues out of the total number of issues presented, it provides a standardized measure of performance across different models and datasets. A successful resolution is typically defined by the model producing a functionally correct output that meets the specified requirements of the issue, often validated through automated testing or human evaluation. Higher Resolve Rates indicate a greater capability of the LLM to accurately understand and address the presented problems, serving as a crucial indicator during model development and benchmarking against competing systems.
Effective context management is crucial for Large Language Model (LLM) performance on issue resolution tasks because LLMs operate within a defined context window. This window limits the amount of information the model can directly process from a given input. Techniques such as retrieval-augmented generation (RAG) address this limitation by dynamically retrieving relevant information from external knowledge sources and incorporating it into the prompt, thereby expanding the effective context. Other methods include prompt engineering to prioritize key information, utilizing sliding window approaches to focus on recent interactions, and employing techniques to summarize or filter irrelevant data, all aimed at ensuring the LLM has access to the necessary information to accurately diagnose and resolve issues within the constraints of its context window.
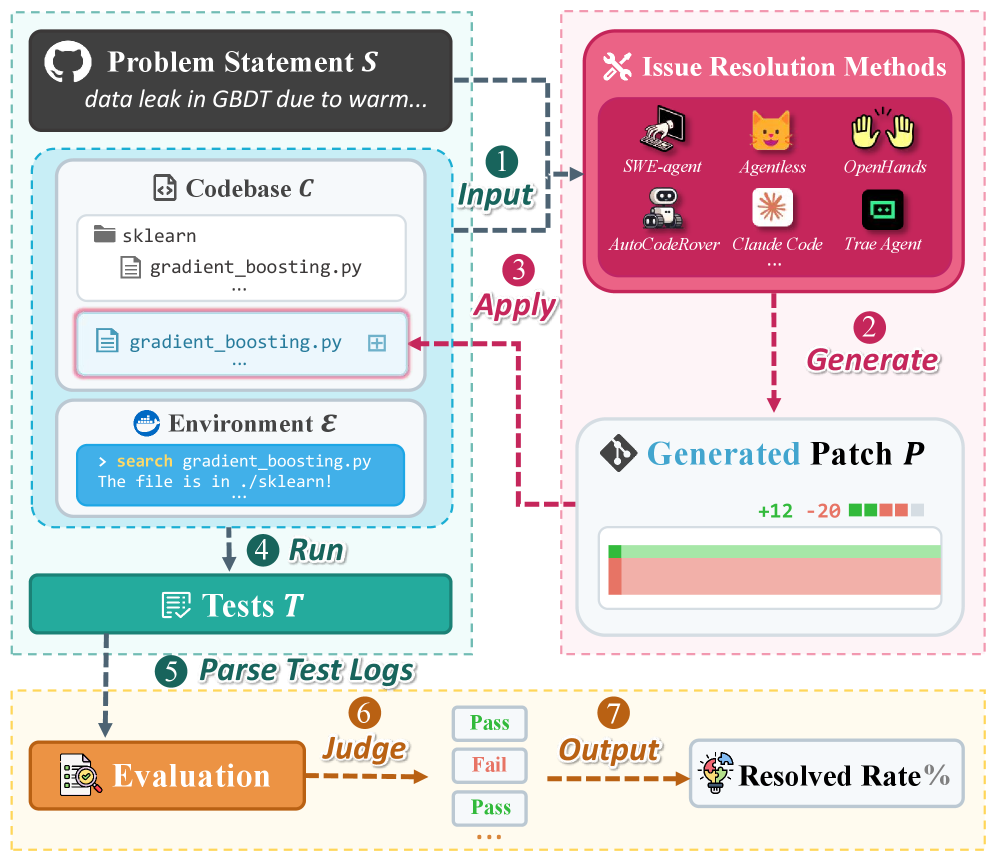
Towards a Future of Automated Software Evolution
The success of Large Language Models (LLMs) in automatically resolving software bugs demonstrates a surprising versatility, extending beyond mere correction to encompass the creation of entirely new software features. This capability stems from the models’ ability to understand code semantics and generate syntactically correct and logically sound additions, effectively automating portions of the software development lifecycle. Rather than relying on explicit programming, developers can now provide high-level descriptions of desired functionality – a natural language prompt – and the LLM translates this into working code. This paradigm shift promises to significantly reduce development time and costs, allowing engineers to focus on higher-level design and innovation, while the LLM handles the more rote aspects of implementation. The potential for automated feature generation represents a substantial leap towards self-evolving software systems, adaptable to changing requirements with minimal human intervention.
Recent advancements demonstrate the potential of simulating entire software development teams using large language models (LLMs) within multi-agent frameworks. Systems like ChatDev and MetaGPT don’t rely on a single LLM, but instead orchestrate a collection of agents, each with specific roles – such as project manager, coder, or tester – and the capacity to communicate and collaborate. These agents autonomously handle tasks from initial planning and code generation to execution and debugging, mirroring the dynamics of a human team. By distributing the workload and fostering interaction, these frameworks significantly enhance the complexity and quality of generated software, moving beyond simple code completion to achieve more sophisticated, functional applications. This approach represents a key step toward fully automated software creation, reducing the need for direct human oversight throughout the development lifecycle.
The advent of large language models is poised to redefine software maintenance, shifting the paradigm from reactive bug fixes to proactive system health management. Future software will increasingly possess the capacity to self-diagnose potential issues – analyzing code, monitoring performance metrics, and even predicting failure points – before they impact users. This isn’t simply about automated patching; it envisions systems capable of autonomously refactoring code to improve efficiency, enhancing security protocols in response to emerging threats, and adapting to evolving hardware landscapes. Such capabilities promise not only reduced downtime and lower maintenance costs, but also a level of long-term reliability and scalability previously unattainable, as software effectively maintains and improves itself throughout its lifecycle – a critical step towards truly sustainable and resilient digital infrastructure.
The survey of LLM-based issue resolution highlights a critical shift in software engineering, moving towards automated maintenance and code generation. This echoes Bertrand Russell’s observation: “The point of a good question is to provoke thought, not to demand an answer.” Similarly, the research doesn’t merely present solutions; it provokes further inquiry into the challenges of applying these large language models – like ensuring reliability and addressing the nuances of complex codebases. The pursuit of elegance in automated systems demands this constant questioning and refinement, recognizing that simplicity, born from rigorous evaluation, is the key to sustainable progress in this evolving field.
What Lies Ahead?
The proliferation of Large Language Models into software engineering presents a familiar paradox: automation promises to alleviate burdens, yet simultaneously introduces new dependencies and points of failure. This survey illuminates a landscape still dominated by adaptation – repurposing models trained for natural language to the distinctly different task of code comprehension and modification. The current emphasis on benchmarking, while necessary, risks becoming a local maximum; performance on contrived datasets does not guarantee robustness in the messy reality of legacy systems and evolving requirements.
Future progress hinges not simply on larger models or more data, but on a deeper understanding of why these models succeed or fail. The field needs to move beyond treating code as merely another form of text, acknowledging the inherent constraints of formal languages and the importance of semantic correctness. Agentic approaches, while promising, demand careful consideration of control mechanisms and the potential for unintended consequences – a system capable of autonomous code modification is also capable of autonomous error introduction.
Ultimately, the true measure of success will not be lines of code generated or bugs automatically fixed, but the extent to which these tools empower developers to focus on higher-level design and innovation. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Original article: https://arxiv.org/pdf/2601.11655.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- Top 10 Coolest Things About Invincible (Mark Grayson)
- Celebs Who Narrowly Escaped The 9/11 Attacks
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-01-21 07:57