Decoding Harmful Intent: Probing Large Language Models for Cyber Threats
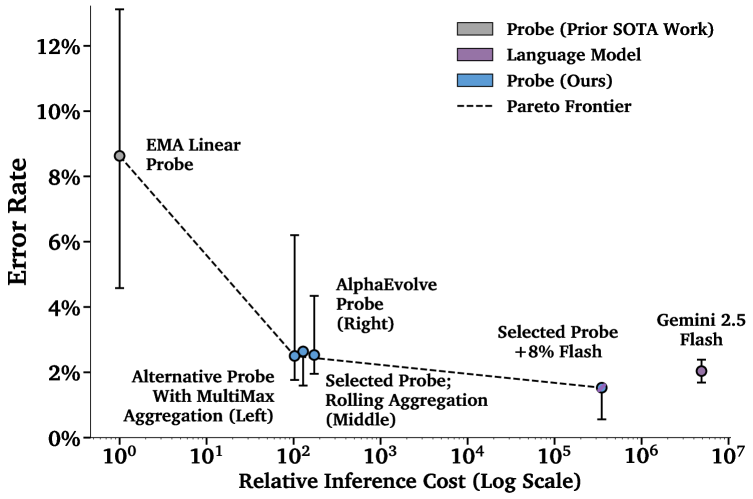
New research explores how analyzing internal model states can effectively detect malicious prompts targeting large language models, offering a practical defense against emerging cybersecurity risks.

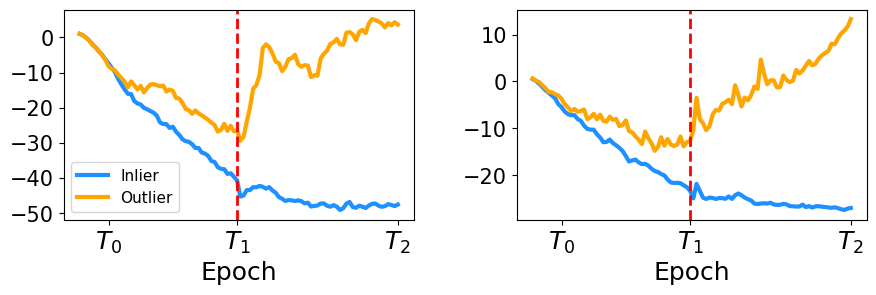
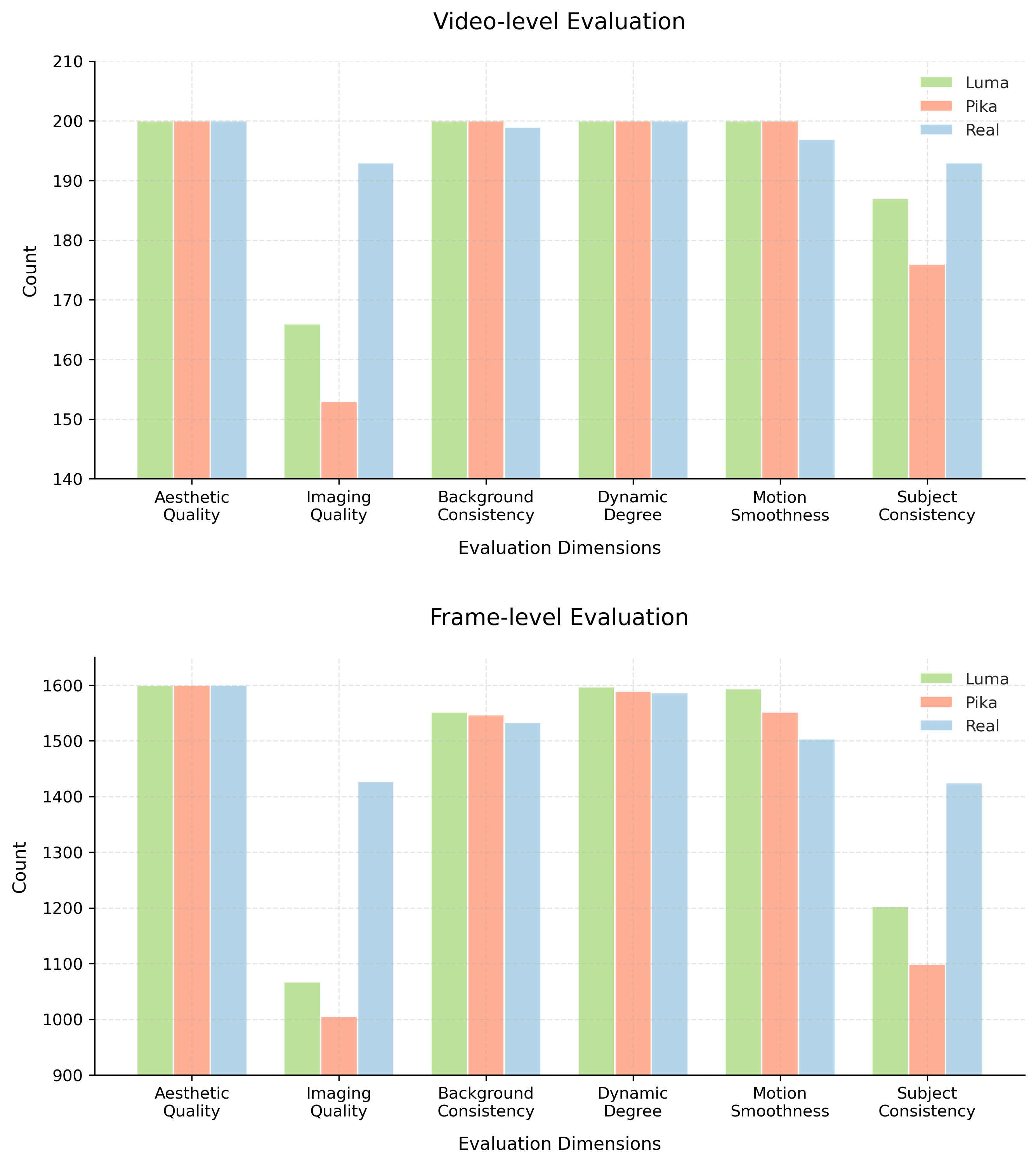
![The self-reflection framework reveals a performance decline correlated with increasing levels of spurious correlation-specifically, as the correlation coefficient [latex]b[/latex] rises from 0.5 to 0.9, the system’s efficacy diminishes, demonstrating the framework’s sensitivity to deceptive patterns within the data.](https://arxiv.org/html/2601.11021v1/x3.png)