Author: Denis Avetisyan
Researchers are leveraging inconsistencies in how light reflects off faces to develop a more robust and generalizable method for detecting manipulated videos.
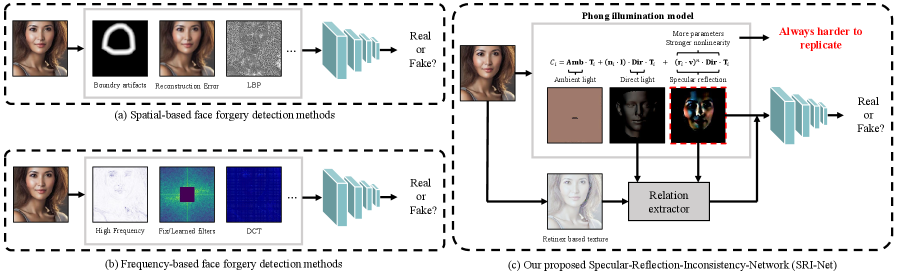
This review details a novel face forgery detection technique based on the challenges of accurately replicating specular reflections under the Phong illumination model, achieving state-of-the-art performance on both traditional and generative deepfake datasets.
Despite advances in deepfake technology, reliably detecting synthetically generated faces remains a significant challenge, particularly with the rise of diffusion models. This paper, ‘Exploring Specular Reflection Inconsistency for Generalizable Face Forgery Detection’, introduces a novel approach predicated on the observation that accurately replicating complex illumination effects, specifically specular reflection governed by the Phong illumination model, is inherently difficult for forgery algorithms. By leveraging Retinex theory for precise texture estimation and a two-stage cross-attention network (SRI-Net) to analyze inconsistencies between specular reflection, face texture, and direct light, the method achieves state-of-the-art performance on both traditional and generative deepfake datasets. Could this focus on physically-based rendering inconsistencies offer a pathway toward more robust and generalizable forgery detection systems?
The Illusion of Authenticity: When Seeing is No Longer Believing
The proliferation of highly convincing facial forgeries is being driven by rapid innovations in generative modeling, most notably Diffusion Models. These models, unlike their predecessors, don’t simply ‘build’ an image; instead, they learn to reverse a process of gradual addition of noise, effectively learning the underlying data distribution and then creating new samples from it. This nuanced approach results in forgeries exhibiting a level of realism previously unattainable, capturing subtle details like realistic skin textures, lighting, and even micro-expressions. Consequently, discerning between authentic and manipulated facial imagery is becoming increasingly difficult, as these models generate content that surpasses the capabilities of many current detection systems and challenges the very foundations of visual trust.
Existing methods for detecting manipulated facial imagery often falter when applied to new and varied datasets. A system trained to identify forgeries within the CelebDF database, for instance, may exhibit significantly reduced accuracy when presented with examples from FaceForensics++ or DiFF. This lack of generalization stems from the rapidly evolving techniques used to create these forgeries; as generative models become more sophisticated, they produce manipulations that bypass the features traditionally used for detection. Subtle inconsistencies, once reliable indicators of a fake, are increasingly difficult to discern, and algorithms reliant on these cues struggle to adapt. Consequently, a detector demonstrating high performance on one benchmark does not guarantee comparable results across the broader landscape of increasingly realistic digital alterations, highlighting a critical vulnerability in current approaches.
The proliferation of highly convincing face forgeries represents a significant and growing threat to the reliability of visual evidence. As generative models continue to advance, the ability to fabricate realistic, yet entirely false, depictions of individuals undermines trust in photographs and videos used across numerous sectors – from journalism and legal proceedings to social media and personal communication. This erosion of confidence isn’t merely a technological challenge; it has profound societal implications, potentially enabling disinformation campaigns, damaging reputations, and manipulating public opinion. Consequently, the development of robust and adaptable forgery detection strategies is no longer simply a matter of academic pursuit, but a critical imperative for safeguarding the integrity of information and maintaining public trust in a visually-saturated world.
The Tell-Tale Glint: Illumination as a Forensic Fingerprint
Specular reflection, the mirror-like reflection of light from a surface, presents measurable differences between authentic and forged images due to manipulation processes. Forged images often exhibit inconsistencies in specular highlights – variations in intensity, shape, or position – because these highlights are highly sensitive to surface geometry and lighting conditions which are frequently altered or incompletely replicated during forgery. These alterations are often subtle and not readily apparent to the human eye, but can be detected through computational analysis of the light transport function. The complexity of accurately simulating specular reflection, especially across varying viewing angles and surface imperfections, contributes to these detectable inconsistencies, making it a valuable indicator for identifying image manipulations.
The Phong Illumination Model and Spherical Harmonic Model are computational techniques used to simulate and analyze light interactions with surfaces, specifically focusing on specular reflection. The Phong model approximates specular highlights as the result of a single reflection, defined by a specular exponent that controls the size and sharpness of the highlight. Spherical Harmonic Models represent illumination as a series of spherical harmonics, allowing for the decomposition of complex lighting environments into constituent components. By characterizing specular reflection through these models, algorithms can isolate and quantify the intensity and distribution of highlights in an image. Deviations from expected specular behavior, as predicted by these models, can then indicate potential image manipulation, as forgeries often struggle to accurately replicate the nuances of realistic illumination.
The Retinex Theory posits that perceived color is determined by the relative reflectance of surfaces, rather than absolute illumination levels. This is achieved by modeling the visual system as processing light in a logarithmic fashion, effectively normalizing for varying illumination. Applying Retinex algorithms to image analysis allows for the decomposition of an image into illumination and reflectance components; this separation is crucial for forgery detection because manipulations often affect illumination inconsistencies. By enhancing the reflectance component, subtle traces of forgery – such as mismatched specular highlights or inconsistent shading – become more visible and quantifiable, as these artifacts are typically embedded within the illumination signal and suppressed when isolating reflectance.
Analysis of illumination characteristics, specifically inconsistencies in specular reflection, offers a potential generalized signal for forgery detection due to its sensitivity to subtle manipulations. Forged images often exhibit distortions in how light interacts with surfaces, as replicating realistic illumination is computationally complex and prone to error during editing. By characterizing specular reflection using models like the Phong or Spherical Harmonic models, and leveraging techniques such as the Retinex theory to isolate illumination components, these inconsistencies can be quantified and used as features for automated forgery detection systems. The generalizability stems from the fact that these inconsistencies aren’t tied to specific image content, but rather to the physics of light and the limitations of forgery techniques.

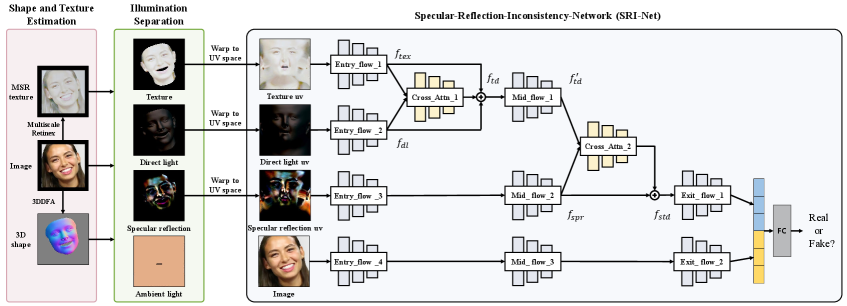
SRI-Net: Weaving Texture, Light, and the Ghost in the Machine
SRI-Net introduces a network architecture specifically designed to model the interdependencies of specular reflection, facial texture, and direct illumination. Traditional forgery detection methods often treat these elements as independent features; however, SRI-Net explicitly establishes correlations between them to improve performance. The network’s design acknowledges that specular highlights are intrinsically linked to both surface texture and the angle of incident light, and that inconsistencies in these relationships can indicate manipulation. By directly modeling these dependencies, SRI-Net aims to create a more robust and accurate forgery detection system, particularly in scenarios with varying lighting conditions and image quality.
SRI-Net utilizes XceptionNet as its primary feature extraction network due to XceptionNet’s established performance in image recognition tasks. XceptionNet is a convolutional neural network based on the Inception architecture, but replaces Inception modules with depthwise separable convolutions. This design choice increases the network’s efficiency and allows for more complex feature representations with fewer parameters. The pre-trained weights from ImageNet are used to initialize XceptionNet within SRI-Net, facilitating faster convergence and improved generalization capabilities when applied to the task of forgery detection. The extracted features from XceptionNet serve as input to subsequent cross-attention modules within SRI-Net.
Cross-attention mechanisms within SRI-Net facilitate the modeling of dependencies between specular reflection, facial texture, and direct illumination features. These mechanisms operate by allowing each feature representation to attend to and weigh the importance of other features during processing. Specifically, queries are generated from one feature map, while keys and values are derived from the others, enabling the network to dynamically focus on relevant information across these modalities. This attention-based interaction allows SRI-Net to capture complex, non-local relationships, going beyond simple concatenation or element-wise operations, and thereby improving its ability to discern subtle forgery artifacts related to illumination and texture inconsistencies.
SRI-Net’s design prioritizes generalizability and robustness in forgery detection by explicitly modeling specular reflection, face texture, and illumination – characteristics consistently present in authentic facial images. Traditional forgery detection methods often struggle with variations in lighting conditions, image quality, and pose; however, by focusing on these fundamental visual cues, SRI-Net aims to create features less susceptible to these variations. This approach allows the network to better discriminate between genuine faces and manipulated images, even when the forgery techniques introduce subtle or complex alterations, ultimately improving performance across diverse datasets and real-world scenarios.

The Proof is in the Perception: Performance and the Pursuit of Trust
SRI-Net exhibits robust performance across a spectrum of forgery detection datasets, notably DF40 and DeepfakeDetection (DFD), indicating its adaptability to varied forgery techniques and quality levels. This capacity stems from the network’s design, which focuses on subtle inconsistencies often present in manipulated media, allowing it to generalize well beyond the specific examples used during training. Evaluations on these datasets consistently demonstrate SRI-Net’s ability to accurately identify both frame-level and video-level forgeries, highlighting its potential for real-world applications in securing digital content and combating the spread of misinformation. The network’s success on diverse datasets underscores its value as a versatile tool in the ongoing effort to detect increasingly sophisticated face-swap and manipulation technologies.
A comprehensive assessment of the forgery detection system’s efficacy involved analyzing video content at two distinct levels: individual frames and complete video sequences. Frame-Level Analysis concentrates on the accuracy of identifying forgeries within static images extracted from videos, offering a detailed look at the system’s ability to pinpoint manipulations in single instances. Complementing this, Video-Level Analysis examines the system’s performance across the temporal dimension, evaluating its capacity to maintain consistent and accurate detection throughout an entire video clip; this is crucial as forgeries may be more easily masked within a dynamic sequence. By employing both methodologies, researchers gain a holistic understanding of the system’s robustness and reliability in real-world scenarios where video evidence is often presented as a continuous stream of data, rather than isolated snapshots.
The efficacy of the forgery detection method is rigorously quantified through the use of Area Under the Curve, or AUC, a metric central to evaluating both accuracy and robustness. AUC effectively measures the model’s ability to distinguish between genuine and forged content across a range of classification thresholds; a higher AUC score indicates superior performance, signifying the model’s consistent ability to correctly identify forgeries while minimizing false positives. This statistical measure is particularly valuable because it provides a single, comprehensive value representing the model’s overall discriminatory power, independent of any specific threshold setting-a critical advantage when dealing with the nuanced variations inherent in realistic face forgery techniques. Consequently, AUC serves as a reliable indicator of the method’s generalizability and its potential for deployment in real-world scenarios where the characteristics of forged content may vary significantly.
Evaluations reveal that SRI-Net demonstrates exceptional accuracy in detecting facial forgeries, achieving a Frame-Level Area Under the Curve (AUC) of 90.9% on the challenging DF40 dataset, thereby exceeding the performance of existing methodologies. Further analysis focused on specular reflection features – the highlights on a face – when inputted into the XceptionNet architecture on the DiFF dataset yielded a Frame-Level AUC of 73.9%. This result signifies a notable 3.2% improvement over the baseline method’s performance on the same dataset, highlighting the critical role of these subtle visual cues in discerning authentic faces from sophisticated forgeries and establishing SRI-Net’s robust detection capabilities.
The increasing sophistication of face forgery techniques presents a growing threat, but recent research indicates substantial progress in automated detection. SRI-Net, a novel approach to forgery analysis, effectively distinguishes between genuine and manipulated faces, as demonstrated by its performance across multiple datasets. This capability isn’t merely academic; the system’s ability to achieve high accuracy-quantified by an Area Under the Curve of 90.9% on the DF40 dataset-suggests a viable defense against the spread of disinformation and the potential for malicious use of synthetic media. By focusing on subtle inconsistencies in specular reflection, SRI-Net offers a robust method for identifying these forgeries, even as the technology used to create them becomes more refined, ultimately contributing to a more secure and trustworthy digital landscape.
The pursuit of flawless forgery detection, as detailed in this study, feels less like engineering and more like a conjuring trick. It’s a humbling reminder that even the most meticulous models are built on approximations – attempts to domesticate the inherent chaos of light and surface interaction. As David Marr observed, “Vision is not about copying the world, but about constructing a representation of it that is useful for action.” This work, with its focus on the subtle inconsistencies of specular reflection under the Phong illumination model, doesn’t aim to perfectly replicate reality, but to exploit the fractures where fabrication reveals itself. It acknowledges that a model isn’t about truth, but about a persuasive illusion – one that holds until production inevitably introduces new distortions.
What’s Next?
The pursuit of specular consistency, as a vulnerability in the architecture of synthetic faces, feels less like a breakthrough and more like a temporary truce. Any model that reliably predicts reflection invites a counter-model designed to become indistinguishable in its imperfections. The current work, while achieving impressive metrics, merely raises the cost of deception – a cost that will inevitably be met with increasingly sophisticated forgeries. It is a familiar dance; anything you can measure isn’t worth trusting.
Future investigations will undoubtedly focus on the multi-scale properties of light transport – the subtle asymmetries, the stochastic nature of surface micro-geometry. But the real challenge isn’t replicating physics, it’s obscuring the attempt at replication. A truly convincing forgery won’t simply mimic specular highlights; it will generate artifacts that appear physically plausible, even if they defy strict mathematical modeling. If the hypothesis held up, one hasn’t dug deep enough.
Perhaps the most fruitful, yet unsettling, direction lies in abandoning the quest for ‘realism’ altogether. What if the most effective forgeries aren’t those that flawlessly imitate human faces, but those that subtly diverge from our expectations, exploiting the inherent limitations of human perception? The problem, then, shifts from detection to acceptance – a far more insidious prospect.
Original article: https://arxiv.org/pdf/2602.06452.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-02-09 13:11