Author: Denis Avetisyan
A new study examines how mental workload affects our ability to distinguish between real and artificially generated audio, as voice-based deepfakes become increasingly sophisticated.
Research indicates that a moderate cognitive load does not significantly impair deepfake detection, and visual context can actually enhance accuracy.
While increasingly sophisticated deepfake technology poses a growing threat of misinformation, understanding human susceptibility to these manipulations under realistic conditions remains a challenge. This is the central question addressed in ‘Does Cognitive Load Affect Human Accuracy in Detecting Voice-Based Deepfakes?’, an empirical study investigating how simultaneous cognitive demands impact the detection of synthetic audio. Surprisingly, results indicate that low cognitive load does not hinder detection, and engaging with concurrent video stimuli can actually improve an individual’s ability to identify voice-based deepfakes. What implications do these findings have for designing effective strategies to combat the spread of audio disinformation in increasingly complex digital environments?
The Evolving Landscape of Synthetic Media and the Erosion of Trust
The accelerating progress in deepfake technology stems from advancements in generative adversarial networks (GANs) and diffusion models, enabling the creation of synthetic media with startling realism. Initially limited to simple face swaps, these algorithms now facilitate the manipulation of audio, video, and even entire scenes, producing content virtually indistinguishable from authentic recordings. Recent iterations leverage increasingly sophisticated AI to mimic nuanced expressions, lighting conditions, and vocal inflections, overcoming previous telltale signs of fabrication. Consequently, the technology is no longer confined to expert manipulation; user-friendly applications and open-source tools empower a broader audience to generate convincing – yet entirely false – content, pushing the boundaries of what is visually and aurally believable and creating unprecedented challenges for media verification.
The accelerating spread of convincingly fabricated videos, images, and audio – facilitated by the reach of social media platforms – presents a growing threat to societal stability by actively diminishing public trust in information sources. This isn’t simply about believing false narratives; the sheer volume of manipulated content creates a climate of uncertainty where authentic material is increasingly viewed with skepticism. The erosion of trust extends beyond specific instances of disinformation, impacting faith in institutions, journalism, and even direct observation. Consequently, this widespread distrust can hinder effective responses to critical issues, polarize communities, and ultimately undermine the foundations of informed democratic participation, posing significant risks to social cohesion and potentially inciting real-world harm.
The relentless surge of synthetic media isn’t merely about the creation of convincing fakes; it fundamentally challenges human perception and introduces a significant cognitive burden on viewers. Each piece of content, regardless of authenticity, now demands increased scrutiny, forcing individuals to actively assess veracity where once passive acceptance sufficed. This constant evaluation – is this real, or is it fabricated? – drains mental resources, leading to cognitive overload and potentially diminishing the capacity for critical thinking on other issues. The sheer volume of information, coupled with the increasing sophistication of deepfake technology, means that even skilled observers struggle to reliably differentiate between genuine and manipulated content, fostering a climate of uncertainty and eroding trust in all forms of media. Consequently, individuals may resort to simplified heuristics or emotional responses rather than reasoned judgment, further exacerbating the societal risks associated with this rapidly evolving landscape.
The Limits of Human Perception: Detecting Deception Under Cognitive Strain
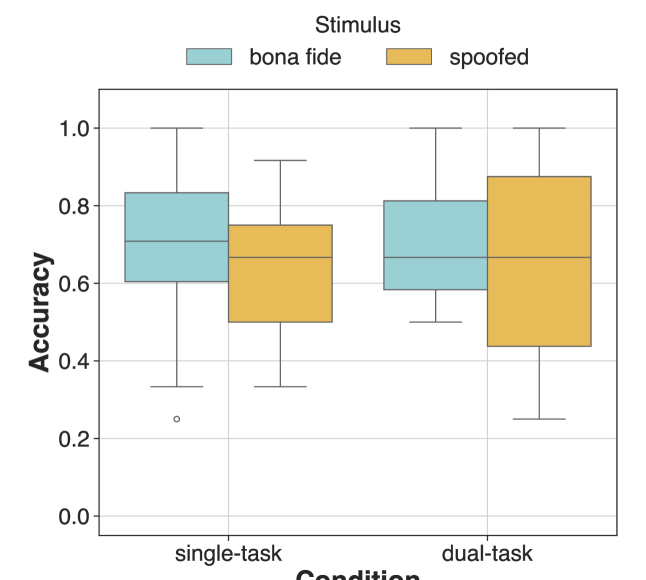
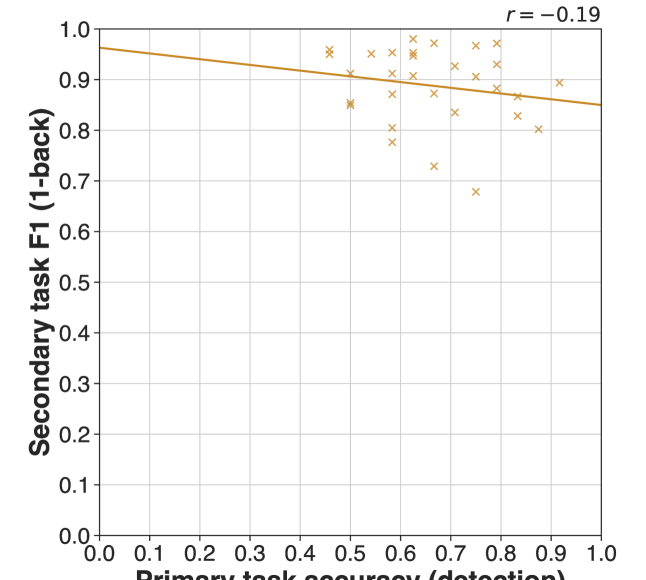
Human accuracy in identifying manipulated content, such as deepfakes, is negatively correlated with cognitive load. Studies demonstrate a measurable decrease in detection rates when individuals are simultaneously tasked with a secondary cognitive demand. This vulnerability arises because increased cognitive load reduces the attentional resources available for detailed perceptual analysis of visual or auditory stimuli, hindering the ability to discern subtle inconsistencies indicative of manipulation. Consequently, individuals under pressure, or experiencing divided attention, exhibit a statistically significant increase in their susceptibility to believing fabricated content compared to scenarios where they can focus solely on the verification task.
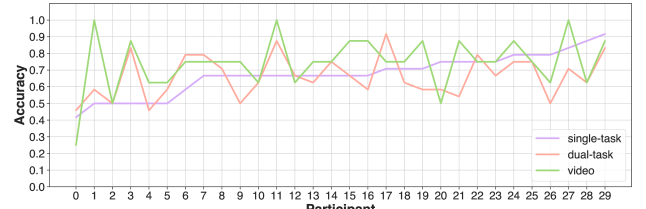
Studies utilizing a dual-task paradigm demonstrate a measurable reduction in accuracy when participants are required to simultaneously perform a primary deception detection task and a secondary cognitive task. Data indicates an accuracy rate of 0.66 under dual-task conditions, representing a decrease from the 0.68 accuracy achieved when the deception detection task is performed in isolation as a single task. This performance difference highlights the impact of divided attention on the ability to accurately assess stimuli, simulating the cognitive load experienced in real-world scenarios and suggesting increased vulnerability to manipulated content, such as deepfakes, under pressure.
The 1-Back task is a cognitive test frequently utilized in research examining attentional capacity and working memory. During a 1-Back task, participants are presented with a sequence of stimuli and instructed to indicate when the current stimulus matches the one presented one step prior. This requirement for continuous monitoring and comparison introduces a measurable cognitive load, diverting attentional resources away from a primary perceptual task – such as deepfake detection – and thus providing a standardized method for quantifying the impact of limited cognitive resources on perceptual accuracy and vulnerability. The controlled nature of the task allows researchers to isolate the effect of cognitive load on an individual’s ability to accurately process visual or auditory information.
The Unexpected Benefit of Complexity: Accessory Stimuli and Enhanced Detection
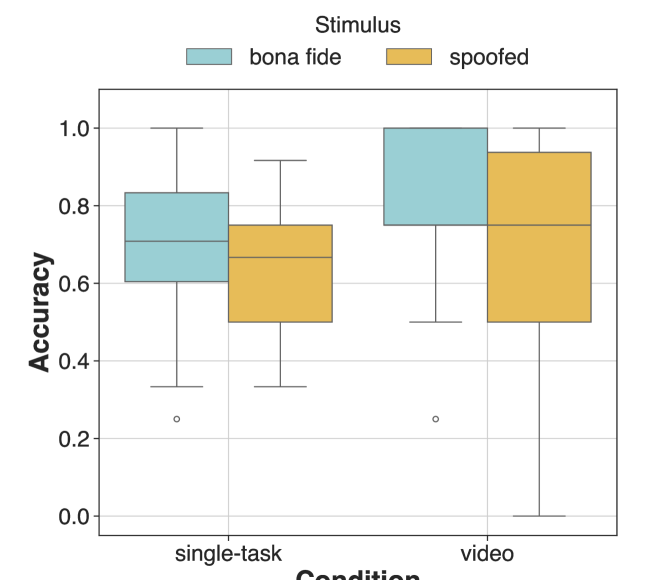
Experiments investigating human performance in deepfake detection incorporated a video condition featuring B-Roll footage alongside the primary stimulus. Results indicated an unexpected phenomenon, termed the Accessory Stimuli Effect, where the addition of this visual complexity – despite increasing overall visual input – led to improved detection accuracy. Specifically, the video condition yielded an accuracy rate of 0.75, a statistically significant increase compared to the single-task condition (0.68) and the dual-task condition, demonstrating that supplemental stimuli can, counterintuitively, enhance performance on a primary cognitive task.
Human detection performance of deepfakes was counterintuitively improved by the introduction of visual complexity in the form of B-Roll footage. Specifically, accuracy in the video condition, incorporating this accessory stimuli, reached 0.75. This represents a statistically significant increase when compared to the single-task condition, where accuracy was 0.68. Furthermore, performance in the video condition also exceeded that of the dual-task condition, indicating that the enhancement was not simply a result of increased cognitive load, but rather a specific effect of the accessory visual information.
Statistical analysis revealed a moderate positive correlation (r = 0.33) between performance in the single-task deepfake detection condition and the video condition incorporating B-Roll footage. This indicates a shared reliance on certain cognitive processes during both tasks, despite the increased visual complexity of the video condition. While not a strong correlation, the value suggests that the cognitive skills utilized for baseline deepfake detection also contribute, to some degree, to the improved performance observed when subjects are simultaneously processing accessory visual stimuli. This finding supports the hypothesis that the Accessory Stimuli Effect is not simply a result of distraction, but rather a more complex interaction of cognitive resources.
The observed enhancement of deepfake detection accuracy in the video condition, despite increased visual complexity, indicates a counterintuitive cognitive effect. This suggests that allocating a portion of cognitive resources to processing accessory stimuli – the B-Roll footage – can paradoxically improve performance on the primary task of identifying manipulated content. While seemingly contradictory, this phenomenon implies that a limited diversion of attentional resources may prevent cognitive overload or maintain a higher level of alertness, ultimately sharpening focus on the deepfake detection task. This is distinct from the performance decrement typically observed in dual-task scenarios, where resource competition hinders performance on both tasks.
The Escalation of Authenticity and the Need for Robust Verification
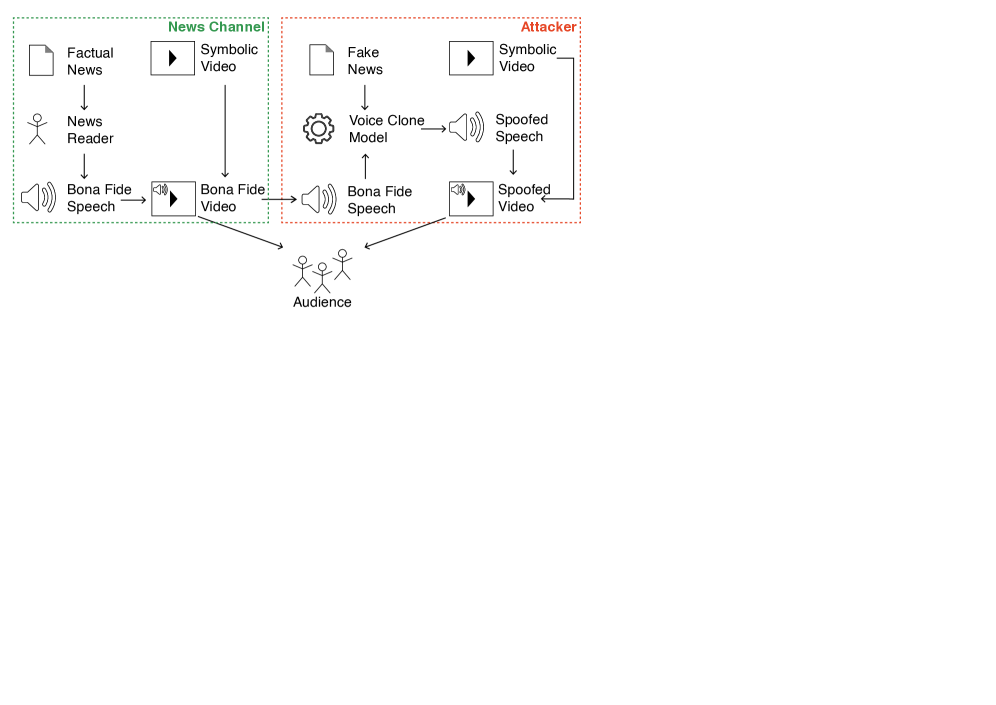
Recent advancements in voice cloning technologies are dramatically lowering the barrier to creating synthetic speech that convincingly mimics a target speaker. Models like TorToise represent a significant leap forward, capable of generating remarkably realistic audio from minimal input – often just a short text prompt and a sample of the desired voice. This isn’t simply about mimicking tone; these systems now capture nuances of prosody, emotion, and even subtle vocal characteristics, making the synthesized speech increasingly difficult to distinguish from genuine human speech. The growing accessibility of these tools, coupled with their escalating realism, is fueling innovation across diverse fields, from content creation and accessibility tools to virtual assistants, while simultaneously presenting new challenges related to authentication and the potential for malicious use.
As voice cloning technologies become increasingly sophisticated and accessible, the need for reliable automatic speaker verification (ASV) systems is paramount. These systems function as a crucial defense against potential misuse, verifying whether a given voice sample genuinely originates from the claimed speaker. Robust ASV is not merely about identification; it’s about establishing trust in vocal communication, preventing fraud, and safeguarding personal identity in a world where convincingly replicated voices can be generated with relative ease. Current research focuses on developing ASV models that are resilient to various acoustic conditions, background noise, and even adversarial attacks designed to fool the system, ensuring accurate authentication even with compromised audio quality or intentional manipulation. The ongoing development and refinement of these technologies are essential to maintaining security and accountability as vocal mimicry becomes increasingly prevalent.
The advancement of voice cloning technologies necessitates equally sophisticated methods of authentication, and progress in this area is heavily reliant on the availability of comprehensive datasets like ASVspoof. These resources provide a diverse collection of speech samples, crucially including both genuine recordings and skillfully crafted imitations – often generated through techniques like text-to-speech synthesis or voice conversion. Researchers utilize ASVspoof to train and rigorously evaluate Automatic Speaker Verification (ASV) systems, assessing their ability to distinguish between a legitimate speaker and a fraudulent impersonation. The dataset’s consistent evolution, with newer iterations incorporating more realistic spoofing attacks and broader linguistic diversity, ensures that ASV research remains at the forefront of security challenges posed by increasingly convincing voice replication. Without such benchmark datasets, evaluating the robustness and reliability of these vital authentication technologies would be significantly hampered, slowing the development of defenses against potential misuse.
The study highlights a critical interplay between information processing demands and perceptual accuracy. It observes that introducing a secondary, light cognitive load doesn’t necessarily hinder deepfake detection, suggesting the system isn’t immediately overwhelmed. However, the increased detection rates with simultaneous video consumption imply a beneficial integration of multi-sensory information. This echoes G.H. Hardy’s sentiment: “A mathematician, like a painter or a poet, is a maker of patterns.” The brain, similarly, constructs patterns from sensory input; when presented with congruent visual and auditory data, it can more effectively discern authenticity, reinforcing the idea that structure dictates behavior and highlighting the benefits of a holistic system rather than isolated analysis of single data streams.
The Road Ahead
The findings suggest a curious resilience in human auditory perception. That a light cognitive load does not significantly impair deepfake detection implies the system isn’t necessarily overloaded by the task, but rather that attention, or its redirection, is the critical factor. The improvement observed with concurrent video consumption isn’t simply about more information; it’s about a shift in attentional architecture. The brain, when forced to integrate multiple streams, appears to subtly recalibrate its validation processes. This, however, introduces a new tension. Any optimization, any apparent ‘solution’, merely reshapes the problem, revealing new vulnerabilities.
Future work must move beyond simple accuracy metrics. The study illuminates the behavior of detection over time, but not the cost. What are the long-term effects of constant vigilance against subtle manipulations? Does this form of cognitive training engender a broader skepticism, or simply a more refined ability to detect specific artifacts? The system’s behavior, not the isolated task, is the true subject of inquiry.
Ultimately, the pursuit of perfect detection is a category error. The architecture of deception will always evolve to exploit the limitations of the perceptual system. The focus should shift toward understanding how these systems fail, and building resilient frameworks for information assessment – systems that acknowledge the inherent ambiguity of reality itself.
Original article: https://arxiv.org/pdf/2601.10383.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Brent Oil Forecast
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-01-19 05:23