Author: Denis Avetisyan
A new study explores how effectively we can train AI to identify content generated by other AI systems.
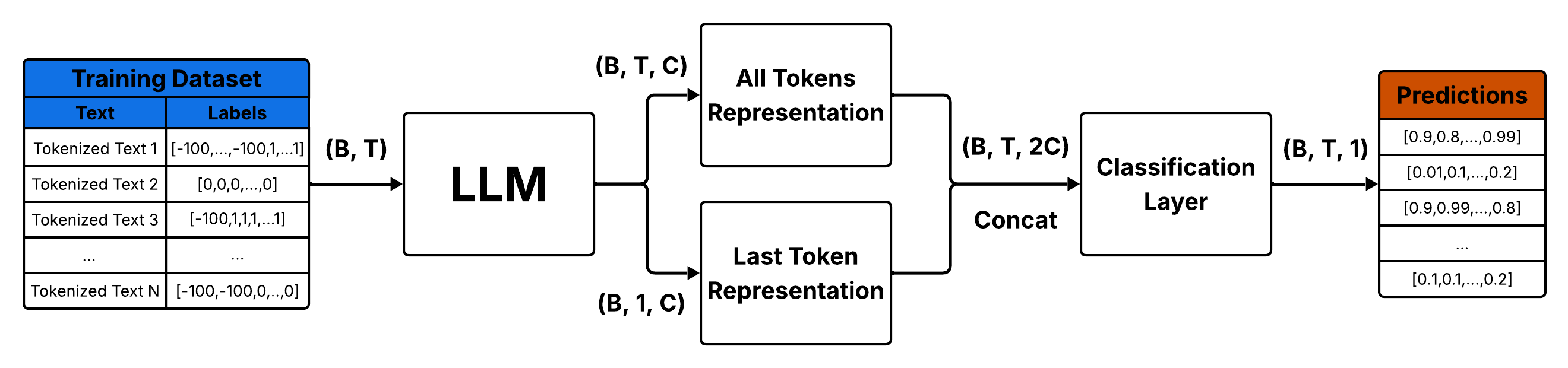
Fine-tuning large language models proves highly effective for AI-generated text detection, with performance varying by model and training strategy.
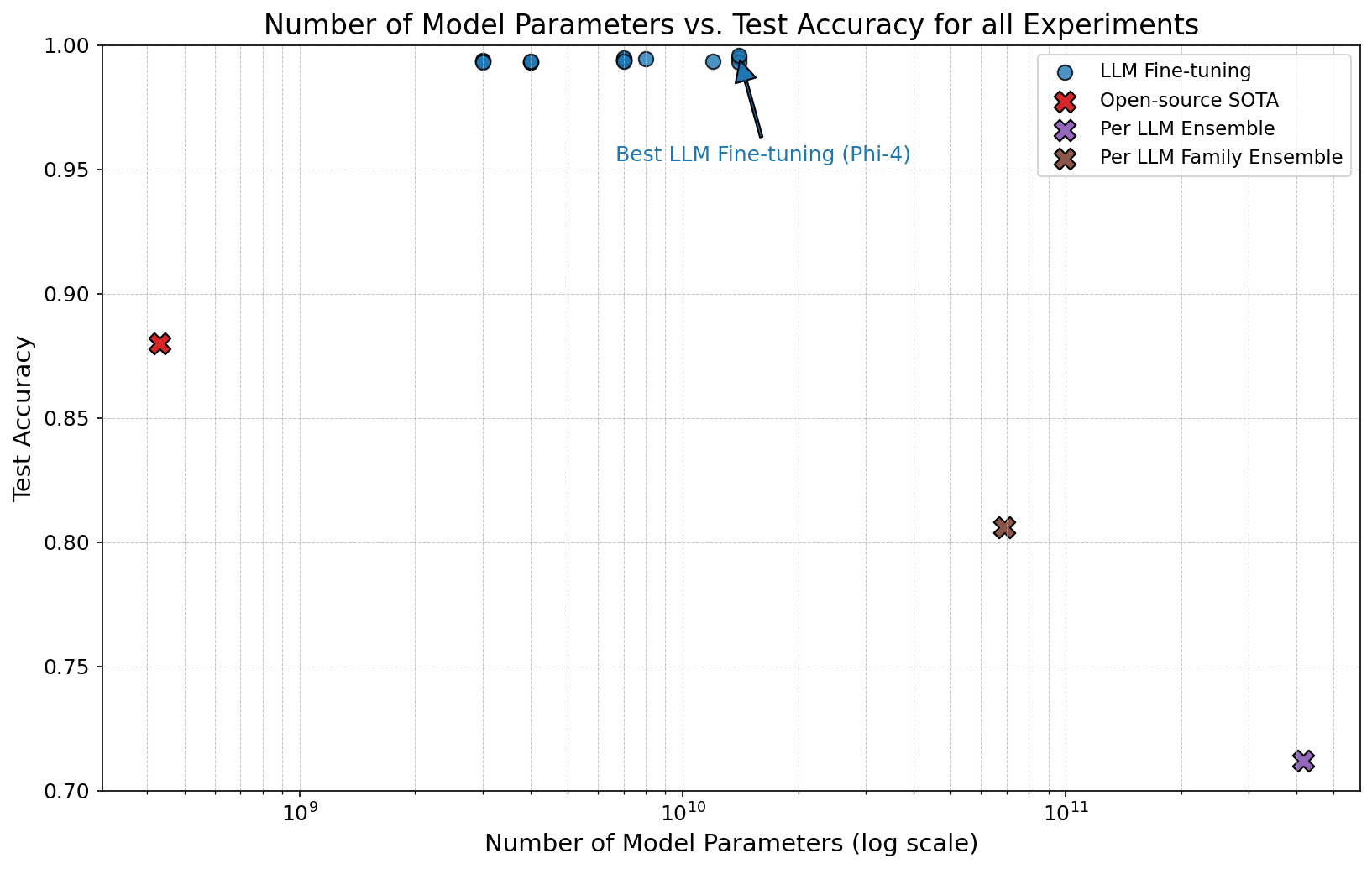
The increasing sophistication of large language models presents a growing challenge to verifying textual authenticity across critical domains. This is addressed in ‘On the Effectiveness of LLM-Specific Fine-Tuning for Detecting AI-Generated Text’, which details a comprehensive investigation into detecting machine-generated content through novel training strategies. The study demonstrates that fine-tuning large language models-particularly using paradigms focused on individual models or families-can achieve up to 99.6\% token-level accuracy on a diverse benchmark of 21 LLMs. Will these advancements in detection methodologies keep pace with the evolving capabilities of increasingly realistic text generation?
The Blurring Line: LLMs and the Challenge of Authentic Text
The rapid advancement of large language models (LLMs) has yielded text generation capabilities that are increasingly difficult to distinguish from human writing. These models, trained on massive datasets, don’t simply regurgitate information; they demonstrate an ability to understand context, mimic writing styles, and even exhibit creativity – composing everything from compelling narratives to technical documentation. This proficiency isn’t merely about grammatical correctness or lexical diversity; it extends to nuanced understanding of sentiment and the ability to tailor language to specific audiences. Consequently, the distinction between text authored by a human and that generated by an artificial intelligence is becoming increasingly blurred, raising fundamental questions about authorship, originality, and the very nature of creative expression. The sophistication of these models presents a significant challenge, demanding new approaches to verify the provenance of digital content and maintain trust in online information.
The increasing proficiency of large language models in crafting convincingly human-like text has created an urgent need for reliable AI-generated text detection systems. This demand isn’t simply about identifying the source of content; it directly addresses growing concerns surrounding the spread of misinformation and the erosion of trust in online information. Robust detection methods are also crucial for maintaining academic and professional integrity, preventing plagiarism, and ensuring authenticity in various forms of digital communication. Without effective tools to distinguish between human and machine authorship, the potential for deceptive practices increases, impacting everything from journalistic reporting and political discourse to creative writing and scientific research. Consequently, the development of these detection systems represents a vital step in safeguarding the reliability and trustworthiness of information in an increasingly digital world.
Conventional techniques for detecting machine-generated text, such as analyzing stylistic patterns or identifying predictable word choices, are increasingly ineffective against the advanced capabilities of Large Language Models. These models now excel at mimicking human writing nuances, producing text that exhibits a high degree of complexity and originality, thus evading detection by simpler algorithms. Consequently, research is shifting towards more sophisticated methods, including analyzing subtle statistical anomalies in text, examining the ‘fingerprints’ left by specific model architectures, and leveraging adversarial training to create detectors that can withstand increasingly clever AI-generated forgeries. The challenge isn’t simply identifying that text was created by AI, but determining which AI created it, and whether the content has been manipulated or repurposed – a pursuit demanding continuous innovation in detection methodologies to maintain a step ahead of rapidly evolving generative models.
LLM Fine-tuning: A Pathway to Discernment
LLM fine-tuning for AI-generated text detection utilizes pre-trained Large Language Models and adapts them to a classification task. This is achieved by training the model on a labeled dataset comprising both authentic, human-authored text and synthetic text produced by other AI models. The process adjusts the model’s internal parameters – its weights – to maximize its ability to correctly categorize input text as either human or machine-generated. Effectively, the model learns to identify statistical patterns, stylistic nuances, and linguistic features that differentiate between the two sources, improving its discriminatory capabilities beyond those of the original, general-purpose LLM.
A robust data pipeline is critical for successful LLM fine-tuning for detection tasks. This pipeline begins with the collection of both human-authored and AI-generated text, sourced from varied domains to ensure generalization. Collected data undergoes rigorous cleaning, including the removal of irrelevant characters, HTML tags, and potentially biased content. Data preparation often involves tokenization and formatting suitable for the target LLM. Furthermore, prompt engineering is frequently integrated to generate a diverse range of synthetic examples, augmenting the existing dataset and improving the model’s ability to discern subtle differences between human and AI writing styles. The quality and diversity of this prepared data directly impacts the performance of the fine-tuned LLM.
The performance of fine-tuned Large Language Models (LLMs) for detecting AI-generated text is heavily dependent on the optimization algorithm employed during training. The Adam optimizer, a stochastic gradient descent method, is frequently used due to its adaptive learning rates for each parameter, facilitating faster convergence. When performing token-level classification – determining the provenance of each token in a sequence – a Binary Cross-Entropy Loss function is commonly applied. This loss function quantifies the difference between the predicted probability of a token being human- or AI-generated and the actual label, providing a gradient signal to update the model’s weights and improve classification accuracy. The effectiveness of this process is directly correlated with the appropriate configuration of hyperparameters within the Adam optimizer and the precise implementation of the Binary Cross-Entropy Loss calculation.
Targeted Training: LLM Families and Detection Specificity
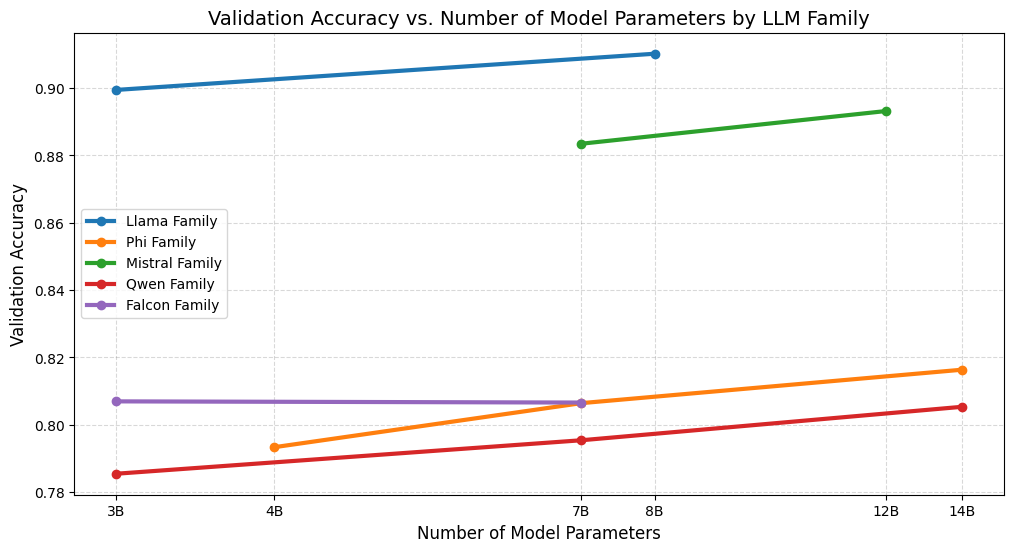
Two distinct approaches to fine-tuning language models for detection are currently under investigation. Per-LLM fine-tuning involves training each individual language model to specifically identify text generated by itself, creating a self-detection capability. Alternatively, Per-LLM Family fine-tuning trains all models within a defined family – such as models sharing a common architecture or training dataset – to detect content originating from any member of that family. This contrasts with training each model individually and allows for generalization across models within the family, potentially improving detection of previously unseen model outputs.
Large Language Models (LLMs) exhibit discernible stylistic patterns and varying susceptibility to adversarial attacks, stemming from differences in architecture, training data, and decoding strategies. This inherent heterogeneity necessitates specialized detection training; a single, universally applicable detector is unlikely to effectively identify machine-generated text across all LLMs. Training detectors specifically on the outputs of individual models, or model families, allows for the capture of these unique characteristics and vulnerabilities, resulting in improved accuracy compared to generic detection approaches. This targeted methodology recognizes that the “fingerprint” of an LLM’s output is not consistent across all models and leverages this distinction for more robust and precise identification of machine-generated content.
Evaluation using the 100-million-token RAID dataset demonstrates significant performance gains from targeted fine-tuning strategies. Specifically, the Per LLM Family ensemble achieved a Recall of 0.980, indicating a high ability to identify generated text, and a Precision of 0.660, representing the accuracy of those identifications. These results suggest near-perfect token-level accuracy is achievable through these methods, exceeding the performance of non-targeted approaches and highlighting the efficacy of leveraging stylistic fingerprints for improved detection of machine-generated content.
Beyond Accuracy: Validating and Interpreting Detection Performance
Rigorous statistical analysis forms the cornerstone of evaluating AI-generated text detection methods, moving beyond subjective impressions to establish objective performance benchmarks. This process involves calculating key metrics – such as precision, recall, and F1-score – to quantify a method’s ability to accurately identify machine-generated text while minimizing false accusations. Analyzing these statistics reveals not only how well a detector performs overall, but also where its strengths and weaknesses lie – for example, whether it excels at identifying longer, more complex passages but struggles with shorter, simpler ones. Furthermore, statistical significance testing allows researchers to confidently determine if observed differences in performance between different methods are genuine, or simply due to random chance, ultimately guiding the development of more robust and reliable detection tools.
Rigorous evaluation of AI-generated text detection relies on a detailed analysis of performance metrics beyond simple accuracy. Researchers meticulously examine detection rates – the proportion of AI-generated text correctly identified – alongside the incidence of false positives, where human-written text is incorrectly flagged as artificial. Further metrics, such as precision and recall, provide a nuanced understanding of a system’s ability to both correctly identify and comprehensively capture all instances of AI-generated content. By pinpointing specific areas of weakness – for example, a high false positive rate on creative writing or difficulty detecting subtly altered text – developers can iteratively refine their algorithms, enhancing robustness and minimizing errors. This continuous cycle of analysis and improvement is crucial for building reliable detection tools capable of adapting to the ever-evolving landscape of AI text generation.
The Phi-4 model has emerged as a critical benchmark in the evaluation of AI-generated text detection techniques, largely due to its compact size and surprisingly strong performance. This allows researchers to conduct rigorous testing without the computational demands often associated with larger language models. By providing a standardized and reproducible platform, Phi-4 enables direct comparison of different detection methods – assessing their accuracy, false positive rates, and robustness against various text manipulations. Consequently, the model isn’t merely a testing ground; it facilitates iterative refinement of detection algorithms, pushing the boundaries of what’s possible in distinguishing between human and machine-authored content and fostering greater transparency in AI text generation.
The pursuit of discerning AI-generated text, as detailed in the study, echoes a fundamental tenet of clarity. The paper demonstrates that fine-tuning large language models, while seemingly complex, achieves a remarkable simplification – a high degree of accuracy in detection. This resonates with Turing’s observation: “Sometimes people who are unkind say things that are unkind to other people.” The nuance lies not in the complexity of the language models themselves, but in the focused application – much like identifying a deliberate falsehood. The study’s exploration of ‘per LLM’ versus ‘per LLM family’ training paradigms exemplifies a surgical approach to refining detection capabilities, removing unnecessary abstraction to reveal the core signal of authenticity. Intuition, in this context, guides the selection of the most effective fine-tuning strategy – the best ‘compiler’ for truth.
What Remains?
The pursuit of automated detection offers diminishing returns. This work confirms that discrimination, even with sophisticated models, is fundamentally a question of feature space. The current emphasis on per-model or per-family fine-tuning feels… taxonomic. It addresses the symptoms of proliferation, not the underlying condition. The models generate; classification chases. A more durable solution will likely necessitate a shift in generative architecture itself – a traceable provenance, perhaps, embedded within the text stream.
Accuracy, reported as a number, obscures a critical point. Detection isn’t binary. There exists a gradient of ‘AI-ness,’ a spectrum of influence. To treat generated text as categorically ‘other’ is a simplification that may prove strategically unwise. Consider the implications for attribution, authorship, and the very definition of originality.
The real challenge isn’t identifying what a machine wrote, but understanding what it means. The current focus on surface features risks overlooking the deeper erosion of semantic integrity. A future worth anticipating prioritizes not detection, but resilience – the capacity to critically evaluate all text, regardless of origin.
Original article: https://arxiv.org/pdf/2601.20006.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-01-29 11:11