Author: Denis Avetisyan
Researchers have developed a novel method to identify text generated by large language models, focusing on measuring the ‘distance’ between original and rewritten content.
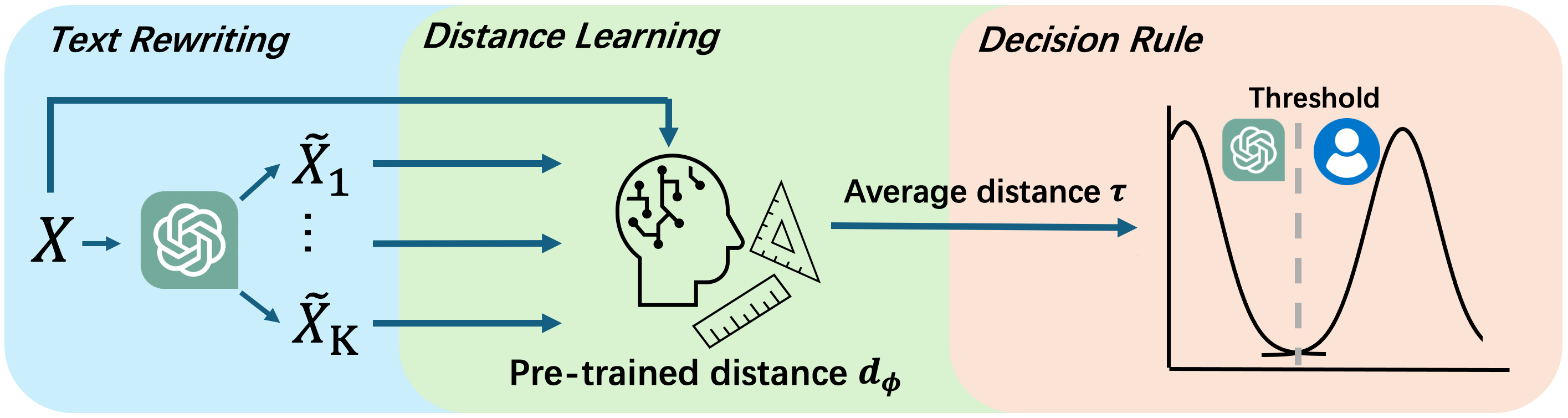
This paper introduces a rewrite-based detection technique with an adaptively learned distance function, demonstrating improved accuracy and robustness against adversarial attacks on large language model generated text.
The increasing sophistication of large language models presents a paradox: while enabling unprecedented creative and communicative capabilities, it simultaneously raises concerns regarding academic integrity and the spread of misinformation. This challenge is addressed in ‘Learn-to-Distance: Distance Learning for Detecting LLM-Generated Text’, which introduces a novel rewrite-based detection algorithm leveraging an adaptively learned distance function to discern between human-written and machine-generated text. Through extensive experimentation, the authors demonstrate significant performance gains-ranging from 57.8% to 80.6%-over existing methods across various language models. Could this adaptive distance learning approach offer a robust and generalizable solution for maintaining trust in an increasingly AI-authored world?
The Evolving Landscape of Text Authenticity
The advent of large language models represents a significant leap in artificial intelligence, now capable of producing text that increasingly mimics human writing styles and nuances. These models, trained on massive datasets, don’t simply regurgitate information; they generate original content exhibiting coherence, grammatical correctness, and even creativity. This capability blurs the established lines between human and machine authorship, making it difficult to discern the origin of a given text. The sophistication extends beyond simple imitation; LLMs can adapt their writing style to suit different prompts and audiences, further complicating the task of identification. Consequently, determining whether a piece of writing is the product of human intellect or algorithmic generation is becoming a critical challenge with far-reaching implications for various fields, from education and journalism to online communication and security.
Existing techniques for identifying machine-generated text are increasingly challenged by the rapid advancements in large language models. Methods relying on stylistic markers – such as predictable sentence structures or repetitive phrasing – prove less effective as these models become adept at mimicking human writing nuances. Similarly, tools focused on detecting statistical anomalies in text distribution struggle against the contextual awareness and creative capabilities of modern LLMs. This escalating sophistication necessitates a shift towards more robust detection strategies, potentially incorporating techniques like analyzing subtle linguistic patterns, examining the consistency of information, or even tracing the probabilistic origins of the text itself. The pursuit of these advanced solutions is critical, not simply to flag automatically generated content, but to preserve the integrity of online discourse and safeguard against the spread of misinformation.
The proliferation of convincingly realistic, machine-generated text presents a significant challenge to the integrity of online information ecosystems. As Large Language Models become increasingly adept at mimicking human writing styles, the ability to reliably distinguish between authentic and artificial content is paramount. This distinction isn’t merely academic; undetected machine-generated text can be leveraged to spread disinformation, manipulate public opinion, and erode trust in established sources. Furthermore, the potential for malicious applications extends to automated propaganda campaigns, the creation of fraudulent reviews, and even the impersonation of individuals online. Consequently, robust detection methods are crucial not only for maintaining the veracity of information but also for safeguarding against deliberate deception and preserving the reliability of digital communication.

Rewriting as a Signature: Unveiling the Origins of Text
Rewrite-based detection functions by introducing controlled perturbations to input text and subsequently analyzing the divergence between the original and modified versions. This technique leverages the hypothesis that machine-generated text, due to its underlying generation process, will demonstrate a statistically significant difference in its response to these alterations compared to text composed by humans. The specific alterations applied can range from paraphrasing and synonym substitution to more complex grammatical transformations, with the goal of exposing subtle inconsistencies in the text’s structure or semantic coherence that differentiate it from naturally-written content. The magnitude and type of rewrite applied are critical parameters in optimizing detection accuracy.
Rewrite-based detection leverages the hypothesis that machine-generated text and human-authored text respond differently to stylistic or semantic alterations. This disparity stems from the differing processes employed in their creation; humans utilize complex cognitive processes, including nuanced understanding and creative expression, while machine learning models rely on statistical patterns and learned representations. Consequently, when subjected to rewriting – such as paraphrasing, synonym replacement, or minor structural changes – machine-generated text tends to exhibit greater instability or amplified differences compared to human text, providing a measurable signal for detection. This principle forms the basis for distinguishing between the two text types based on their response to controlled perturbations.
Quantifying the difference between original and rewritten text is central to rewrite-based detection and necessitates the implementation of a distance metric. Fixed distance metrics employ a pre-defined measure, such as character error rate or Levenshtein distance, applied consistently across all text pairs. Adaptive metrics, conversely, dynamically adjust their sensitivity based on characteristics of the input text or the rewriting process itself; these may involve weighting specific types of edits or incorporating statistical language modeling to assess fluency changes. The selection of an appropriate metric impacts both the sensitivity and robustness of the detection system, requiring careful consideration of the anticipated rewriting strategies and the characteristics of the target text.
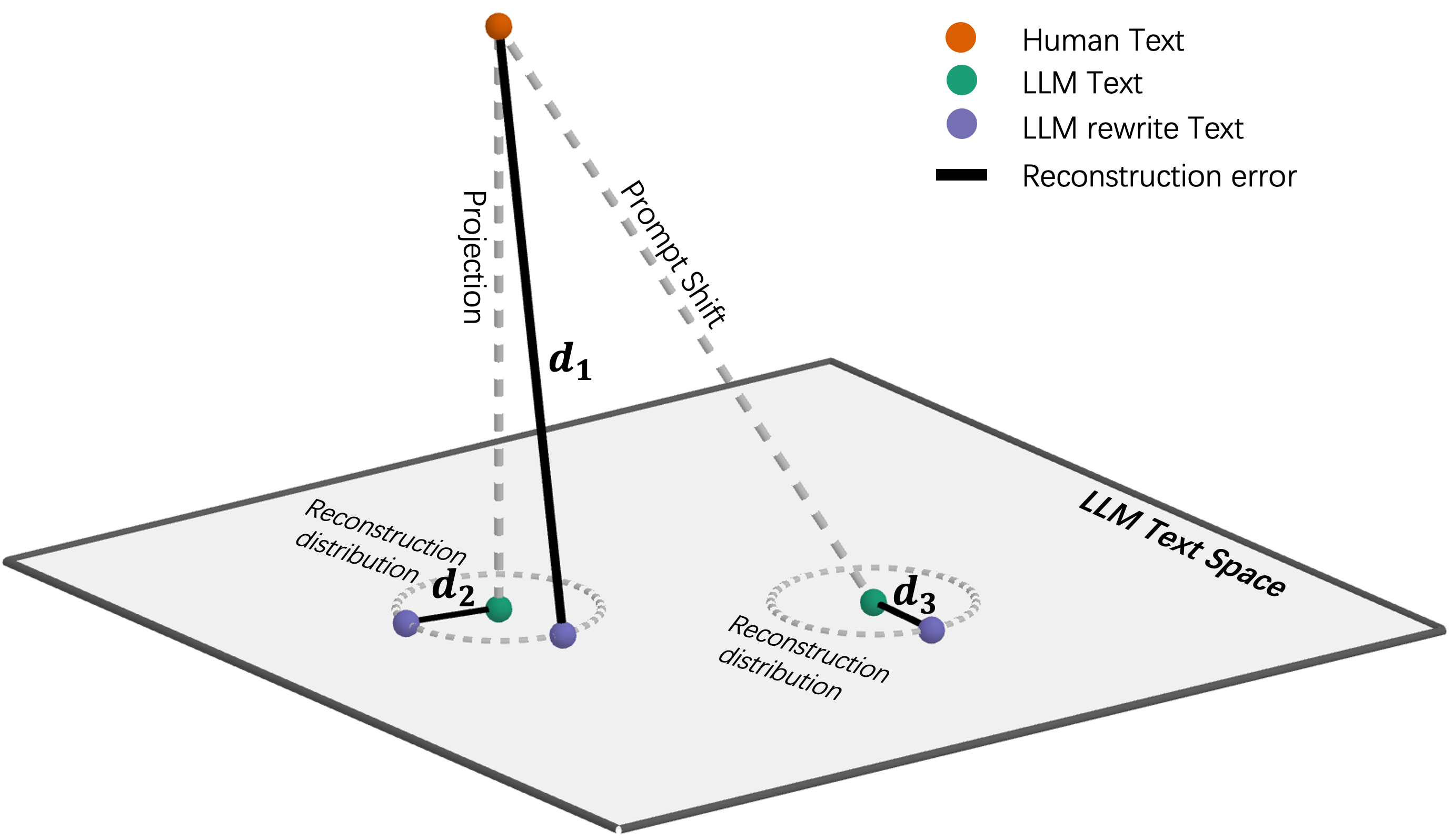
Precision in Difference: Adaptive Distance Functions for Robust Detection
Adaptive Distance Functions enhance text version comparison by dynamically adjusting the methodology used to quantify differences, rather than relying on static, pre-defined metrics. These functions employ algorithms to learn the characteristics of both legitimate and machine-generated text, allowing them to prioritize relevant distinctions and minimize the impact of irrelevant variations. This learning process enables a more accurate assessment of textual similarity, leading to substantial improvements in detection performance; testing demonstrates an average relative improvement of 57.8% to 80.6% compared to the strongest baseline and a 97.1% improvement over fixed distance functions.
The refinement of distance calculation in adaptive distance functions relies on the Projection Operator and Reconstruction Error. The Projection Operator determines the closest point within a defined text subspace to a given text version, effectively reducing dimensionality and noise. Subsequently, the Reconstruction Error quantifies the difference between the original text and its projected reconstruction; a lower Reconstruction Error indicates a more accurate representation within the subspace. This error value is then used to iteratively adjust the distance function’s parameters, optimizing its ability to discern subtle differences between texts and improving detection accuracy by minimizing the impact of stylistic variations and focusing on content-level changes. This process allows the function to learn which features are most indicative of authorship or manipulation.
Adaptive distance functions consistently exceed the performance of traditional, fixed-metric approaches in detecting text alterations. Evaluations indicate an average relative improvement ranging from 57.8% to 80.6% when compared against the strongest baseline model. Critically, these adaptive functions demonstrate a 97.1% improvement in accuracy over the use of a static distance function, highlighting their capacity to more effectively discern differences attributable to both human writing variations and machine-generated text characteristics.
The Illusion of Authenticity: Adversarial Attacks and the Limits of Current Detection
Current methods for identifying text generated by large language models are demonstrably vulnerable to subtle manipulation, as evidenced by adversarial attacks like rephrasing and decoherence techniques. These attacks don’t rely on drastic changes to the text; instead, they introduce minor alterations – synonymous substitutions, slight reorderings, or the insertion of seemingly innocuous phrases – that are designed to mimic the stylistic nuances of human writing. Critically, these modifications often succeed in bypassing detection tools, which frequently rely on identifying statistical patterns or specific linguistic features characteristic of machine generation. The success of these attacks underscores a fundamental limitation in existing detection systems: their susceptibility to even slight deviations from the expected profile of AI-generated content, highlighting the need for more sophisticated and resilient approaches.
Adversarial attacks on large language models (LLMs) cleverly manipulate generated text through subtle alterations designed to mimic human writing styles. These aren’t wholesale changes, but rather carefully crafted modifications – a rephrased sentence here, a slight adjustment to sentence structure there – that aim to bypass existing detection methods. The effectiveness of these attacks stems from their ability to exploit the statistical fingerprints that often distinguish machine-generated text from human-authored content; by nudging the text closer to natural human patterns, they can successfully evade classifiers trained to identify artificial origins. Consequently, even highly sophisticated detection tools can be fooled, highlighting a critical vulnerability in current approaches and the urgent need for more resilient techniques capable of discerning genuine human writing from increasingly convincing machine-generated imitations.
The emergence of adversarial attacks against large language models (LLMs) underscores a critical vulnerability in current text detection methods and necessitates the development of more resilient techniques. These attacks, designed to subtly manipulate LLM-generated text, demonstrate that even seemingly sophisticated detectors can be evaded by carefully crafted alterations. This isn’t simply a matter of improving accuracy; it’s about building systems that are fundamentally robust to intentional deception. Future detection methods must move beyond identifying stylistic markers – which are easily mimicked or disrupted – and focus on deeper linguistic properties or inherent inconsistencies within the text itself. Without such advancements, the reliability of automated content verification will remain compromised, potentially enabling the widespread dissemination of misleading or fabricated information.

Beyond Comparison: Towards Zero-Shot Detection and a Future of Reliable Text Attribution
Zero-shot detection represents a significant advancement in addressing the challenge of identifying machine-generated text, operating without the need for pre-labeled training datasets. This innovative approach leverages the inherent statistical properties and linguistic patterns characteristic of large language models, allowing algorithms to distinguish between human and machine authorship based on these intrinsic features. Rather than ‘learning’ from examples, these methods assess the probability and perplexity of text, identifying anomalies or stylistic fingerprints typical of artificial text generation. The ability to perform accurate detection without requiring extensive, and often costly, labeled data opens avenues for real-time content verification and widespread deployment in diverse applications, from combating misinformation to ensuring academic integrity, and offers a flexible solution as language models continue to evolve.
Current strategies for discerning machine-generated text hinge on identifying subtle statistical fingerprints within the language models’ output. Logits-based detection, for example, analyzes the probability distributions assigned to potential words before selection, revealing patterns characteristic of LLM decision-making-machines often exhibit more predictable token choices than humans. Machine learning-based detection, conversely, employs algorithms trained on the nuances of both human and machine writing styles, learning to classify text based on features like perplexity, burstiness, and the frequency of specific syntactic structures. These methods capitalize on the inherent differences in how humans and large language models construct sentences and express ideas, offering a pathway to automated authorship attribution even without explicitly labeled training examples.
The evolving landscape of large language models necessitates a parallel advancement in both detection techniques and methods to circumvent them. While current approaches, such as the one detailed in this study achieving an Area Under the Curve (AUC) of up to 92%, demonstrate promising results in identifying machine-generated text, these systems are not impervious to sophisticated adversarial attacks designed to mimic human writing styles. Consequently, sustained investigation into robust detection methodologies – those resilient to manipulation – is inextricably linked to the development of techniques that probe and expose vulnerabilities in those same systems. This iterative process of attack and defense is vital; it not only refines the accuracy of detection but also establishes a foundation of trust in an increasingly digital world where discerning authentic content from synthetic creation is paramount for maintaining informed discourse and reliable information.
The pursuit of robust LLM detection, as detailed in this work, echoes a fundamental principle of systemic integrity. The proposed rewrite-based method, with its adaptively learned distance function, exemplifies how understanding the ‘whole’-the nuances of text generation and potential adversarial manipulations-is crucial for building resilient detection systems. This approach moves beyond simply identifying surface-level features; it seeks to establish a deeper understanding of the underlying structure that differentiates human and machine-generated text. As Claude Shannon observed, “The most important thing in communication is to convey the meaning, not the symbols.” This sentiment directly applies to LLM detection; the goal isn’t merely to flag certain words or phrases, but to accurately discern the meaning behind the text and its origin.
Where Do We Go From Here?
The pursuit of robust detection for machine-generated text inevitably reveals a fundamental truth: the signal is always weaker than the noise. This work, by focusing on adaptive distance metrics within a rewrite-based framework, offers a temporary respite, but it does not solve the underlying problem. Future work will likely center not on finding the artificial, but on accepting its inevitability. The true cost isn’t misidentification, but the escalating complexity of the detection systems themselves. Each layer of defense introduces new vulnerabilities, new abstractions that leak, and ultimately, new avenues for circumvention.
A more fruitful direction might lie in shifting the focus from detection to provenance. Rather than asking “is this text human or machine?” the relevant question becomes “what was the process by which this text came to be?”. Such an approach necessitates a fundamental rethinking of text as a data structure, incorporating metadata about its creation and modification-a sort of textual pedigree. This, however, introduces its own set of challenges, requiring robust mechanisms for authentication and tamper-proofing.
Ultimately, the architecture of detection will remain invisible until it fails. The current emphasis on adversarial attacks, while valuable, is a symptom, not a cause. A truly scalable solution will acknowledge that simplicity scales, cleverness does not, and that the most effective defense is not a complex algorithm, but a fundamentally honest system. The long game isn’t about winning the arms race; it’s about minimizing the incentives to fight it.
Original article: https://arxiv.org/pdf/2601.21895.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Gold Rate Forecast
- Building Agents That Learn and Improve Themselves
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 18 TV Series Filming Rehearsals as Bonus Content
- Trading Crypto with AI: A New Approach to Portfolio Management
2026-01-31 22:10