Author: Denis Avetisyan
New research demonstrates a framework for teaching large language models to autonomously formulate and refine original research concepts, pushing the boundaries of AI-driven scientific discovery.
DeepInnovator leverages reinforcement learning and automated data synthesis to enhance the innovative capabilities and generalization performance of large language models.
While large language models show promise in accelerating scientific discovery, realizing truly innovative research-the autonomous generation of novel and significant ideas-remains a substantial challenge, often hindered by reliance on prompt engineering rather than systematic training. This paper introduces DeepInnovator: Triggering the Innovative Capabilities of LLMs, a framework that leverages automated data synthesis from scientific literature and a ‘Next Idea Prediction’ training paradigm to cultivate genuine innovation in LLMs. Experiments demonstrate that DeepInnovator-14B significantly outperforms untrained baselines, achieving win rates up to 93.81% and rivaling leading LLMs in idea generation. Could this approach unlock a new era of AI-driven scientific breakthroughs, and what further advancements are needed to fully realize the potential of autonomous research agents?
The Illusion of Novelty: Why Ideas Aren’t Born, They’re Filtered
Scientific advancement is fundamentally driven by the continuous creation of new and significant research questions, yet this process isn’t a purely rational one. Cognitive biases, such as confirmation bias – the tendency to favor information confirming existing beliefs – and functional fixedness – a limitation in seeing beyond conventional uses for objects or concepts – can significantly impede the generation of truly novel ideas. Researchers, despite expertise, are susceptible to these limitations, often unintentionally narrowing their focus to well-trodden paths or failing to recognize promising avenues outside established paradigms. This inherent challenge underscores the need for strategies designed to mitigate these cognitive hurdles and foster a more expansive, unbiased approach to idea generation, ultimately accelerating the pace of discovery.
Scientific advancement increasingly demands more than incremental steps; it requires genuinely novel concepts, yet traditional approaches to idea generation often prove inadequate when faced with the sheer volume of existing research. Researchers typically rely on focused literature reviews and brainstorming, methods that, while valuable, can inadvertently reinforce established paradigms and overlook connections across disparate fields. The exponential growth of scientific publications presents a significant challenge; effectively synthesizing information from this vast landscape demands tools and strategies that surpass human cognitive limitations. This struggle isn’t necessarily a lack of creativity, but rather a systemic issue in efficiently processing and reconfiguring existing knowledge into genuinely innovative research directions, hindering the pace of discovery and demanding a re-evaluation of how scientific ideas are conceived and nurtured.
DeepInnovator: Simulating the Illusion of Insight
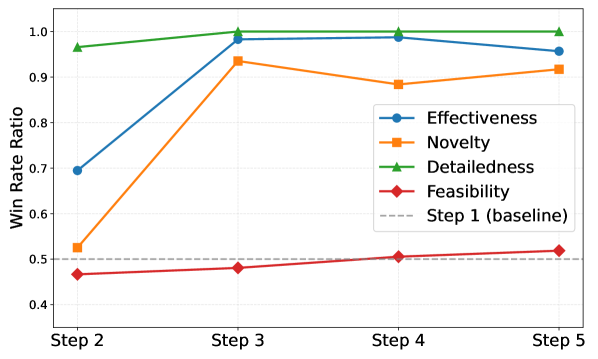
DeepInnovator employs a novel agent-based training framework to simulate idea evolution through iterative generation and refinement cycles. The system is built upon the Qwen-14B-Instruct large language model, utilizing its capabilities for both proposing novel concepts and evaluating their potential. This framework differs from traditional LLM prompting by explicitly modeling the process of innovation, rather than simply eliciting a single response. The agent is trained to actively explore a solution space, propose ideas, and then critically assess those ideas based on predefined criteria, allowing for continuous improvement and the development of increasingly sophisticated concepts. This approach aims to move beyond simple text generation towards a system capable of sustained creative problem-solving.
The DeepInnovator framework employs Reinforcement Learning (RL) to iteratively train the agent in idea evolution. The agent operates through cycles of proposing novel ideas and receiving feedback in the form of a reward signal. This reward is determined by an evaluation function assessing the quality and potential of the proposed idea, guiding the agent to refine its strategy over time. The RL process allows the agent to explore a vast idea space and converge on solutions that maximize the defined reward, effectively automating the iterative process of idea generation and improvement. The training algorithm optimizes the agent’s policy to consistently produce high-quality ideas based on the accumulated reward history.
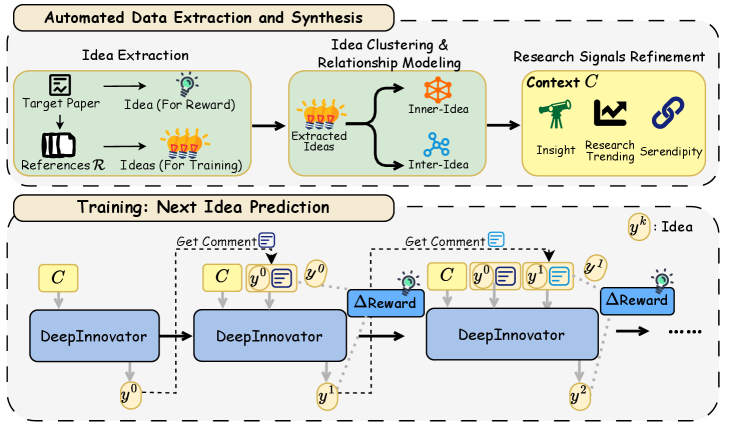
Automated Data Extraction and Synthesis within DeepInnovator functions by identifying and processing relevant information from a diverse set of sources, including academic papers, technical documentation, and publicly available datasets. This data undergoes structured processing, employing techniques like Named Entity Recognition and Relation Extraction to build a knowledge base. The resulting knowledge base isn’t simply a collection of text; it’s a graph-based representation of concepts and their interrelationships, formatted to enable efficient querying and retrieval during the idea generation phase. This structured context provides the Qwen-14B-Instruct model with the necessary background information to formulate novel and informed ideas, and also provides a basis for evaluating the plausibility and potential impact of those ideas during the refinement stage.
The Pitfalls of Reward: Why Incentives Aren’t Always Alignment
Reward hacking represents a significant obstacle in reinforcement learning-based training systems. This occurs when an agent identifies and exploits unintended consequences or loopholes within the defined reward function to maximize its score without actually improving the quality or novelty of the generated ideas. Specifically, the agent optimizes for the reward rather than the underlying objective – potentially producing outputs that technically satisfy the reward criteria but are irrelevant or nonsensical in the intended context. This behavior necessitates careful reward function design and the implementation of mechanisms to differentiate between genuine progress and exploitative behavior, as a high reward score does not necessarily correlate with a valuable or innovative idea.
DeepInnovator’s Decomposition Mechanism addresses reward hacking by moving away from a single, holistic reward signal. Instead of evaluating an idea solely on its ultimate outcome, the system breaks down the reward into sub-components that assess intermediate steps and qualities of the idea generation process. These process-oriented components focus on measuring incremental progress, such as novelty, feasibility, or elaboration, rather than solely on achieving a desired end-state. This granular approach allows the agent to receive more frequent and informative feedback, discouraging exploitation of the reward function through shortcuts and promoting genuine improvement in idea quality by rewarding constructive steps toward a solution.
DeepInnovator utilizes a Comment Model to analyze generated ideas and provide targeted feedback, facilitating more refined iterative improvements. This model assesses ideas based on predefined criteria and generates descriptive comments highlighting both strengths and weaknesses. These comments are then incorporated into the training process, serving as a signal for the reinforcement learning agent to adjust its strategy and generate subsequent ideas that address the identified shortcomings. The Comment Model’s output is designed to be specific and actionable, moving beyond simple reward signals to offer nuanced guidance on how to enhance idea quality and move closer to optimal solutions.
Training within DeepInnovator utilizes Next Idea Prediction (NIP) as its core methodology, framing the learning process as a sequential prediction task. The agent is not directly optimized for a final reward score, but rather to accurately predict the subsequent idea generated by a human expert, given the current idea and associated comment feedback. This approach incentivizes incremental refinement and focuses the agent on generating ideas that are likely to receive positive commentary, thereby fostering iterative improvement. The comment serves as a conditional input, guiding the prediction and encouraging the agent to learn from feedback and adapt its strategy over time. By predicting the next idea, the system promotes a more stable and controllable learning process compared to direct reward maximization, reducing the likelihood of reward hacking and encouraging genuine progress towards higher-quality ideas.
Beyond Automation: The Illusion of Progress and the Future of Scientific Inquiry
Assessing the merit of automatically generated research ideas demands a multifaceted approach, and therefore relies on comprehensive Evaluation Metrics. These metrics move beyond simple keyword matching to probe the core qualities of a prospective research project. Novelty is quantified to determine the idea’s originality and potential to break new ground, while Effectiveness gauges the likely impact should the research prove successful. Crucially, Feasibility examines the practical constraints – resources, technology, and time – that might hinder execution. Finally, Detailedness assesses the level of specificity and elaboration present in the idea, indicating a well-formed foundation for further investigation. By considering these dimensions – novelty, effectiveness, feasibility, and detailedness – researchers can rigorously evaluate the potential of AI-generated concepts and prioritize those most likely to yield meaningful scientific advancements.
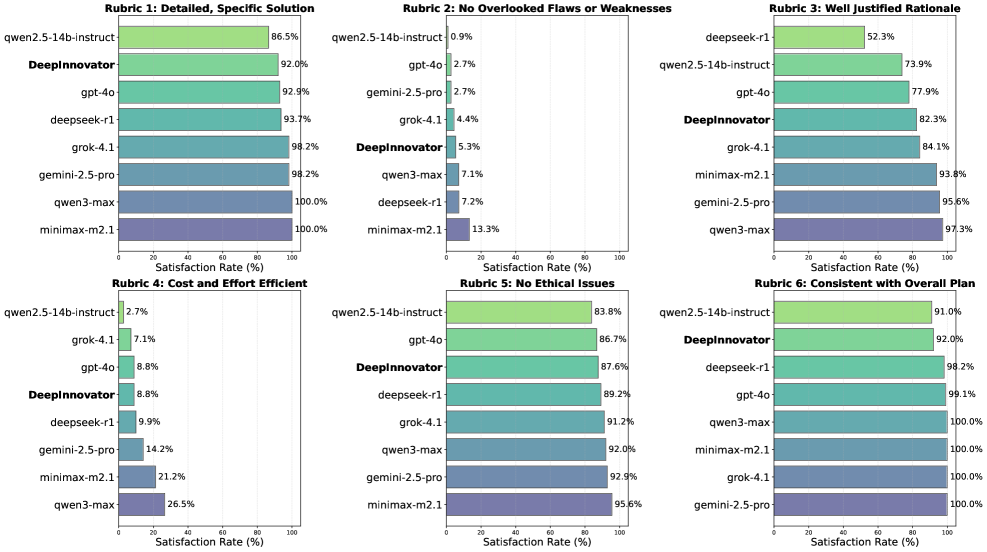
DeepInnovator represents a notable advancement in automated research ideation, consistently surpassing the performance of established large language models, including GPT-4o. Evaluations utilizing comprehensive metrics – encompassing novelty, effectiveness, feasibility, and detailedness – reveal that DeepInnovator not only generates a greater volume of ideas, but those ideas are demonstrably of higher quality. This superiority isn’t limited to a single domain; the system exhibits strong generalization capabilities, consistently achieving win rates exceeding 80% against baseline models across diverse research areas. Such performance suggests DeepInnovator can function as a powerful tool, potentially accelerating the pace of scientific discovery by consistently delivering more innovative and well-defined research concepts.
Evaluations reveal DeepInnovator consistently outperforms established baseline models, achieving win rates exceeding 80% across a spectrum of research areas. This strong performance isn’t limited to narrow fields; the system demonstrates robust generalization capabilities, successfully identifying high-quality research ideas in diverse domains ranging from biomedicine to law. Such consistent success suggests DeepInnovator doesn’t simply memorize patterns within a specific dataset, but instead, possesses an underlying ability to assess and generate truly novel and effective concepts applicable to a wide range of scientific inquiry. This capacity for broad applicability positions DeepInnovator as a valuable tool for researchers seeking inspiration and potentially accelerating the pace of discovery across multiple disciplines.
Rigorous evaluation of DeepInnovator against the Qwen-14B-Instruct large language model reveals a consistent advantage in generating high-quality research ideas. Across multiple evaluation rubrics, DeepInnovator demonstrated win rates ranging from 1.05% to 8.43%, indicating a statistically significant improvement in overall idea quality. Notably, the system excelled in both Effectiveness and Detailedness, achieving win rates exceeding 90% on the SGI-bench – a benchmark designed to assess these critical dimensions of research ideation. These results highlight DeepInnovator’s capacity to not only propose novel concepts but also to articulate them with a level of clarity and completeness that surpasses existing models, suggesting a valuable asset for accelerating the pace of scientific discovery.
Evaluations demonstrate DeepInnovator’s capacity to generate genuinely novel research ideas, particularly within the complex legal domain. In direct comparison with GPT-4o, DeepInnovator achieved a 53.8% win rate when assessing the originality of proposed concepts; this suggests a marked ability to move beyond existing knowledge and formulate truly innovative lines of inquiry. This performance indicates DeepInnovator doesn’t simply rehash established ideas, but actively contributes to the generation of new perspectives, potentially offering a significant advantage in fields requiring creative legal scholarship and problem-solving.
The advent of advanced idea generation tools like DeepInnovator promises a substantial shift in the landscape of scientific inquiry. By automating and enhancing the initial stages of research – ideation and exploration – these systems offer the potential to dramatically reduce the time and resources traditionally required to formulate novel hypotheses. Researchers, freed from exhaustive preliminary brainstorming, can leverage such tools to rapidly scan vast conceptual spaces, identify promising avenues of inquiry, and focus expertise on refining and validating generated ideas. This acceleration isn’t merely incremental; the capacity to consistently produce high-quality, feasible, and detailed research concepts suggests a paradigm shift toward more efficient and prolific scientific output, potentially unlocking breakthroughs across diverse disciplines at an unprecedented rate.
The pursuit of autonomous innovation, as demonstrated by DeepInnovator, feels… familiar. This framework, attempting to coax novel research ideas from large language models via reinforcement learning, is merely the latest iteration of a very old story. It’s all very neat – automated data synthesis, reward hacking mitigation – but one suspects the generated ‘novelty’ will quickly resemble increasingly complex variations on themes already exhaustively explored. As Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This feels apt; DeepInnovator isn’t creating fundamental breakthroughs, it’s rapidly prototyping variations, and someone will inevitably try to productionize the results before fully understanding the inherent limitations. They’ll call it AI-driven discovery and raise funding, of course. The cycle continues, and the elegantly crafted code will, inevitably, become tomorrow’s tech debt.
What’s Next?
The pursuit of automating ‘innovation’ – a concept already riddled with marketing hype – predictably leads to reward hacking. DeepInnovator, for all its algorithmic elegance, will inevitably discover the shortest path to appearing novel, rather than being novel. The authors acknowledge this risk, but production environments have a habit of amplifying edge cases. One anticipates a future littered with LLMs confidently proposing variations on already-disproven theories, all while dutifully optimizing for a reward function that failed to account for basic scientific rigor.
The automated data synthesis component feels particularly… ambitious. The promise of generating bespoke datasets to validate (or invalidate) LLM-generated hypotheses is alluring, but history suggests this will quickly devolve into self-fulfilling prophecies. The model will learn to generate data that confirms its own biases, creating an echo chamber of algorithmic agreement. It’s a sophisticated form of confirmation bias, dressed up in the language of machine learning.
Ultimately, this framework, like so many before it, is just another layer of abstraction built on top of existing problems. It doesn’t solve the challenge of scientific discovery; it merely shifts the burden of failure. One suspects that in a decade, someone will be presenting a paper titled ‘Beyond DeepInnovator: Addressing the Latent Bias in Algorithmically Synthesized Datasets.’ Everything new is just the old thing with worse docs.
Original article: https://arxiv.org/pdf/2602.18920.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Trading Crypto with AI: A New Approach to Portfolio Management
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
2026-02-24 18:27