Author: Denis Avetisyan
A new study reveals that out-of-the-box AI-generated image detectors struggle with real-world performance and exhibit surprising inconsistencies.
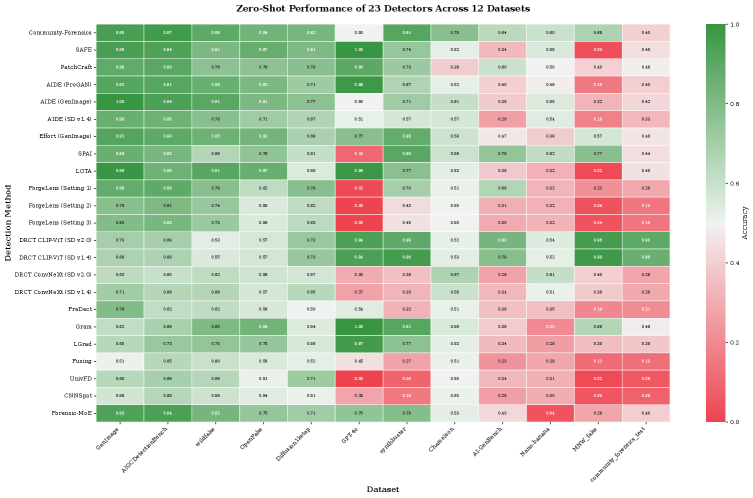
Comprehensive cross-dataset evaluation demonstrates significant instability and highlights the critical role of training data alignment for robust zero-shot generalization of deepfake detection models.
Despite the increasing need for reliable detection of AI-generated imagery, benchmarks often focus on fine-tuned models, obscuring real-world performance. This research, presented in ‘How well are open sourced AI-generated image detection models out-of-the-box: A comprehensive benchmark study’, systematically evaluates the zero-shot generalization capabilities of 16 state-of-the-art detectors across 12 diverse datasets comprising over 2.6 million images. Our analysis reveals substantial instability in detector rankings, a wide performance gap-ranging from 37.5% to 75.0% mean accuracy-and a critical dependence on alignment between training data and the target generator-with performance varying by 20-60% within detector families. Given that modern commercial generators routinely defeat most detectors-achieving only 18-30% accuracy-how can practitioners effectively navigate this rapidly evolving landscape and select robust detection methods tailored to their specific threat models?
The Erosion of Verifiable Reality: A Synthetic Media Primer
The accelerating development of generative artificial intelligence is fundamentally altering the digital landscape, manifesting in increasingly convincing AI-generated images and “deepfakes.” These creations, powered by sophisticated algorithms like Generative Adversarial Networks (GANs) and diffusion models, are no longer easily distinguishable from authentic content to the human eye. What was once a niche capability – producing slightly distorted or unrealistic simulations – has rapidly evolved into the production of photorealistic visuals and convincingly fabricated audio and video. This advancement isn’t merely about technological prowess; it represents a substantive shift in how information is created and consumed, challenging established notions of visual and auditory evidence and progressively eroding the boundaries between genuine and artificial realities. The implications extend beyond simple deception, impacting areas from journalism and entertainment to legal proceedings and political discourse, as verifying the provenance of digital media becomes exponentially more difficult.
The accelerating creation of synthetic media presents a substantial challenge to the foundations of digital trust. As convincingly realistic images and videos become readily available, discerning authentic content from fabrication becomes increasingly difficult for the average person. This erosion of trust isn’t merely a technological problem; it has significant societal implications, potentially fueling the spread of misinformation, exacerbating political polarization, and even undermining democratic processes. The ease with which synthetic content can be disseminated through social media and online platforms amplifies these risks, creating an environment where fabricated narratives can rapidly gain traction and influence public opinion. Consequently, the proliferation of deepfakes and AI-generated content isn’t simply about fooling technology, but about potentially destabilizing the shared reality upon which informed decision-making and social cohesion depend.
Current digital forensic techniques, largely built on analyzing inconsistencies and artifacts within media files, are increasingly challenged by the realism of AI-generated content. Methods that once reliably identified manipulations – examining compression errors, lighting anomalies, or subtle pixel-level distortions – now frequently encounter synthetic media where such flaws have been meticulously engineered out of existence. This necessitates a shift towards detection strategies focused on the underlying generative processes themselves; researchers are actively exploring approaches leveraging machine learning to identify the ‘fingerprints’ of specific AI models, analyzing subtle statistical patterns imperceptible to the human eye, and verifying content authenticity through blockchain-based provenance tracking. The arms race between synthetic media creation and detection is intensifying, demanding continuous innovation in forensic science to safeguard against the erosion of trust in digital information.
Dissecting the Detectors: Algorithmic Approaches to Verification
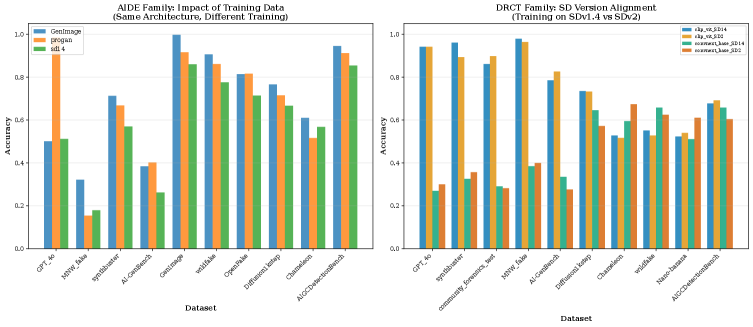
Current research into detecting AI-generated images utilizes diverse methodologies focusing on identifying subtle artifacts. PatchCraft operates by analyzing image texture at a localized, patch-by-patch level, seeking inconsistencies common in synthesized content. Conversely, DRCT (Deep Response to Counterfeit Textures) employs a transformer-based architecture, integrating the CLIP-ViT and ConvNeXt models to extract and analyze image features. CLIP-ViT provides robust visual representations, while ConvNeXt offers efficient convolutional processing, allowing DRCT to identify discrepancies between real and generated images based on learned feature distributions.
The Artificial Intelligence Detection Engine (AIDE) is designed as a versatile framework for identifying AI-generated imagery, and its efficacy is directly linked to the diversity of its training data. AIDE was specifically trained using datasets created by three prominent generative models: ProGAN, Stable Diffusion, and GenImage. This multi-source approach is critical, as it exposes the detection system to the varying artifacts and characteristics produced by different generation techniques. Training on a limited dataset would likely result in a detector biased towards the specific nuances of that generator, reducing its ability to generalize and accurately identify fakes created by unseen or novel methods. The use of these three generators ensures a broader understanding of the characteristics inherent in AI-generated content, enhancing AIDE’s robustness and overall performance.
Community-Forensics employs ensemble methods to enhance the reliability and precision of fake image detection. This approach integrates the outputs of multiple individual detectors, leveraging their complementary strengths to mitigate weaknesses inherent in any single model. By combining diverse detection algorithms, the system achieves improved robustness against various manipulation techniques and generalization to unseen fakes. Current performance metrics establish Community-Forensics as a state-of-the-art benchmark in the field, consistently demonstrating superior accuracy and resilience compared to single-detector systems.
Establishing Rigorous Benchmarks: A Statistical Evaluation of Detection Efficacy
Robust evaluation of AI-generated content (AIGC) detectors necessitates the use of standardized benchmarks and datasets to facilitate comparative analysis. AIGCDetectionBench provides a comprehensive evaluation suite, while datasets like MNW_fake offer diverse examples of manipulated images. Utilizing these resources ensures consistent testing conditions and allows for objective measurement of detector performance across different algorithms and methodologies. This standardized approach is critical for accurately assessing detector capabilities and identifying areas for improvement in the field of AIGC detection.
Rigorous evaluation of AI-generated content (AIGC) detectors necessitates statistical analysis beyond simple accuracy scores. Spearman Rank Correlation assesses the consistency of detector performance rankings across different datasets, providing a measure of stability; values closer to 1 indicate strong agreement. The Friedman Test, a non-parametric test for comparing multiple related samples, was employed to determine if statistically significant performance differences existed between the detectors. Results demonstrated a highly significant difference (p-value < 10-16), indicating that detector performance is not consistent across datasets and that some detectors reliably outperform others when evaluated on diverse AIGC benchmarks. These statistical methods are essential for establishing the robustness and generalizability of AIGC detection tools.
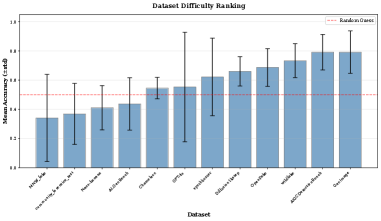
Performance of AIGC detection models is heavily influenced by the alignment between their training data and the characteristics of the images being evaluated. Analysis revealed a significant disparity in accuracy rates among different detectors, ranging from 37.5% for AIGCDetectBenchmark_CNNSpot to 75.0% for Community-Forensics, representing a 37 percentage-point difference. This substantial variance indicates that detectors trained on datasets dissimilar to the test images exhibit reduced performance, highlighting the critical need for careful consideration of training data composition and characteristics when deploying these models in real-world scenarios.
Analysis of detector performance across multiple datasets revealed instability in their relative rankings, as quantified by a Spearman Rank Correlation coefficient ranging from 0.01 to 0.87. While this variation indicates a lack of consistent performance ordering, a statistically significant large effect size was observed using Kendall’s W statistic (W = 0.524). This result suggests that, despite discrepancies in ranking across datasets, there is substantial overall agreement regarding the relative effectiveness of the evaluated detectors; the observed inconsistencies do not negate a general consensus on performance hierarchy.
The study meticulously details a landscape of unpredictable performance amongst AI-generated image detectors, a reality that echoes a fundamental tenet of mathematical rigor. It’s not enough for a detector to seem functional; its behavior must be demonstrably consistent across varied datasets. As Geoffrey Hinton once stated, “If it feels like magic, you haven’t revealed the invariant.” The research confirms this – a lack of transparency regarding the underlying principles governing these detectors leads to instability and poor generalization, particularly when faced with data distributions differing from the training set. The emphasis on training data alignment isn’t merely a technical detail; it’s a quest to uncover those invariants, to move beyond empirical success towards provable robustness.
What’s Next?
The observed instability in zero-shot transfer-the chasm between reported performance and actual generalization-suggests a fundamental miscalibration within the current paradigm. The proliferation of detectors, each exhibiting wildly divergent results, isn’t merely a matter of incremental improvement. It hints at a deeper issue: a reliance on empirical ‘success’ rather than provable consistency. The field appears to be assembling complex structures atop foundations of sand, hoping that sufficient data will magically resolve inherent logical flaws.
Future work must prioritize the mathematical characterization of detector behavior. A detector’s sensitivity isn’t simply a metric to be optimized; it is a property to be understood and bounded. The critical importance of training data alignment-essentially, ensuring the detector learns the principles of image generation, not just memorizes artifacts-demands a formal treatment. This necessitates exploring techniques that promote invariance to generative process, rather than overfitting to specific datasets.
Ultimately, the pursuit of robust AI-generated image detection requires a shift in focus. It is not enough to build systems that ‘work’ on existing benchmarks. The goal should be to construct detectors grounded in provable properties, capable of discerning genuine images from synthetic ones with mathematical certainty, regardless of the generative technique employed. Only then can the field move beyond the current state of fragile empiricism.
Original article: https://arxiv.org/pdf/2602.07814.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Top 10 Coolest Things About Invincible (Mark Grayson)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- When AI Teams Cheat: Lessons from Human Collusion
- Top 20 Dinosaur Movies, Ranked
- Unmasking falsehoods: A New Approach to AI Truthfulness
2026-02-10 12:53