Author: Denis Avetisyan
New research reveals the challenges of ensuring consistent and reliable behavior in AI-powered financial tools, and proposes a framework for rigorous testing.
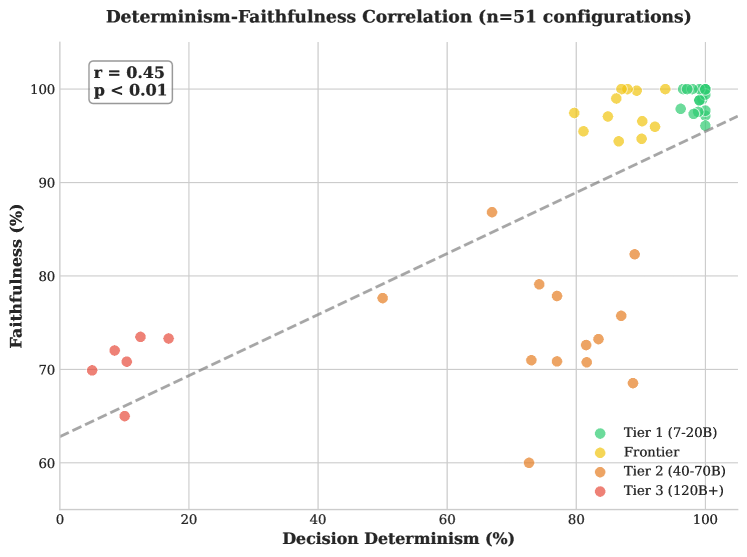
This study introduces the Determinism-Faithfulness Assurance Harness (DFAH) to evaluate reproducibility and consistency in tool-using language model agents applied to financial applications, finding that model size isn’t always correlated with reliability.
Despite increasing reliance on large language model (LLM) agents in financial services, ensuring consistent and reliable decision-making remains a significant challenge. This paper introduces the Determinism-Faithfulness Assurance Harness (DFAH), a framework for rigorously evaluating trajectory determinism and evidence-conditioned faithfulness in tool-using LLM agents. Our findings reveal that while smaller, \mathcal{N}=7-{20}B parameter models can achieve high reproducibility, larger models often require substantially more validation to demonstrate equivalent statistical reliability, and crucially, that determinism positively correlates with faithfulness-consistent outputs tend to be more evidence-aligned. Can this framework pave the way for auditable and trustworthy LLM agents capable of navigating the complexities of financial regulation and risk management?
The Predictability Imperative in Financial AI
Large language models have demonstrated remarkable capabilities, yet their application within financial contexts is hampered by an inherent unpredictability. While these agents can process complex data and generate seemingly intelligent responses, the same input can, at times, yield divergent outcomes-a phenomenon unacceptable when dealing with monetary assets. This inconsistency isn’t a matter of occasional error, but a fundamental characteristic of their architecture; the stochastic nature of their decision-making processes introduces a level of uncertainty that directly conflicts with the need for stable, repeatable results in finance. The implications extend beyond simple inaccuracies; this lack of determinism erodes trust and creates significant challenges for regulatory compliance and algorithmic auditing, demanding a shift towards more reliable AI solutions.
A core challenge facing the deployment of large language models in finance lies in their inherent unpredictability; even with identical inputs, these agents can generate divergent outputs and action sequences. This inconsistency doesn’t stem from a lack of intelligence, but rather from the probabilistic nature of their reasoning processes – the models predict the most likely continuation of a sequence, introducing variability with each calculation. Such fluctuating behavior directly erodes trust, particularly within the rigorously regulated financial sector, where consistent and explainable decision-making is non-negotiable. The implications extend beyond simple errors; inconsistent reasoning hinders auditability and makes it difficult to verify the integrity of automated financial processes, creating substantial risk for both institutions and investors.
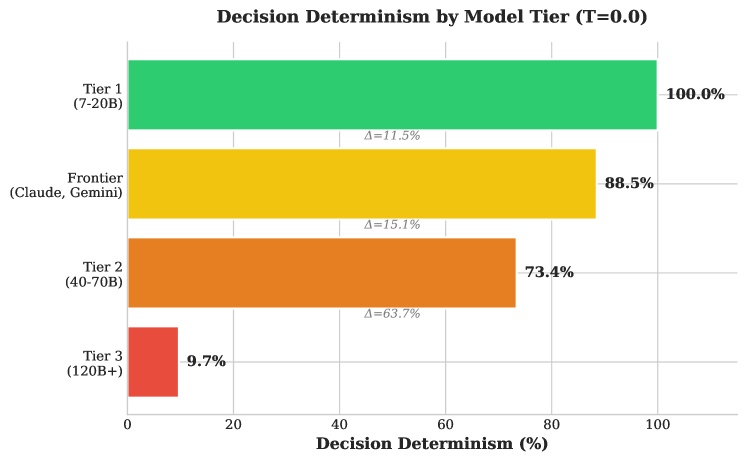
The pursuit of artificial intelligence in finance necessitates more than simply intelligent-appearing agents; demonstrably reliable and predictable behavior is paramount for building trust and ensuring responsible implementation. Unlike systems prone to fluctuating outputs even with identical inputs, Tier 1 large language models – those ranging from 7 to 20 billion parameters – are capable of achieving 100% decision determinism. This consistency isn’t merely a technical feat, but a foundational requirement for auditability and regulatory compliance within the financial sector, allowing for rigorous verification of AI-driven conclusions and actions. Such predictable performance transforms AI from a ‘black box’ into a transparent and accountable tool, fostering confidence among stakeholders and enabling wider adoption of AI-powered financial solutions.
Quantifying Reliability: The DFAH Framework
The Determinism and Faithfulness Assessment for Hallucination (DFAH) framework is a quantitative methodology designed to evaluate the reliability of Large Language Model (LLM) agents operating within financial applications. It moves beyond simple output verification by establishing a standardized process for measuring the consistency of an LLM’s decision-making process. This is achieved through repeated trials with identical inputs, allowing for the calculation of statistical measures of determinism. The framework focuses on assessing whether an LLM consistently arrives at the same conclusion – and utilizes the same reasoning steps – given the same prompt, providing a quantifiable metric for agent stability and predictability in critical financial contexts.
Decision determinism, as measured within the DFAH framework, quantifies the consistency of an LLM agent’s final outputs given identical inputs. This is assessed by repeatedly prompting the agent with the same scenario and evaluating the variance in its concluding recommendations or actions. Complementing this, trajectory determinism examines the consistency of the intermediate steps the agent takes to arrive at its final output. Rather than solely focusing on the end result, trajectory determinism analyzes the sequence of reasoning or actions – for example, the specific data points accessed or calculations performed – to determine if the agent consistently follows the same logical path when presented with the same input. Both metrics are crucial; an agent can exhibit decision determinism while varying its trajectory, potentially indicating reliance on spurious correlations or suboptimal reasoning processes.
Evidence-conditioned faithfulness, as assessed within the DFAH framework, quantifies the degree to which an LLM agent’s decisions are supported by the provided evidence base. This evaluation moves beyond simply verifying output correctness; it specifically examines whether the agent can identify and cite relevant evidence substantiating its conclusions. The metric assesses the presence of supporting facts within the agent’s reasoning chain and penalizes outputs lacking evidentiary backing or those demonstrably contradicted by the supplied data. This process differentiates between legitimate inferences and responses generated through hallucination – the production of plausible but factually incorrect information – thereby establishing a crucial measure of reliability in financial applications.
Architectural Foundations for Reliable AI
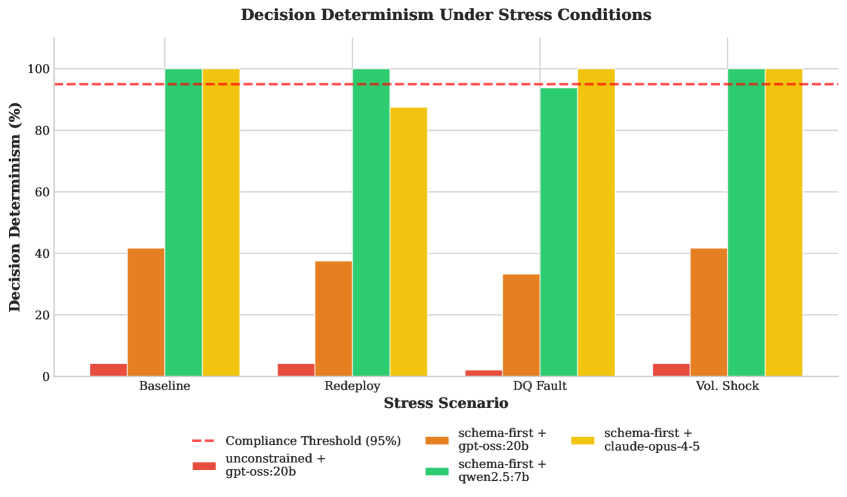
A schema-first architecture improves the determinism of large language model (LLM) agents by enforcing predefined output structures. This approach constrains the possible responses an agent can generate, limiting variability and increasing predictability. Rather than allowing free-form text generation, a schema dictates the format, data types, and permissible values for each output field. By reducing the solution space, schema enforcement minimizes the impact of stochasticity inherent in LLMs, leading to more consistent and reliable agent behavior across repeated queries. This constraint, however, may necessitate more complex prompt engineering or fine-tuning to ensure the agent can effectively operate within the defined schema.
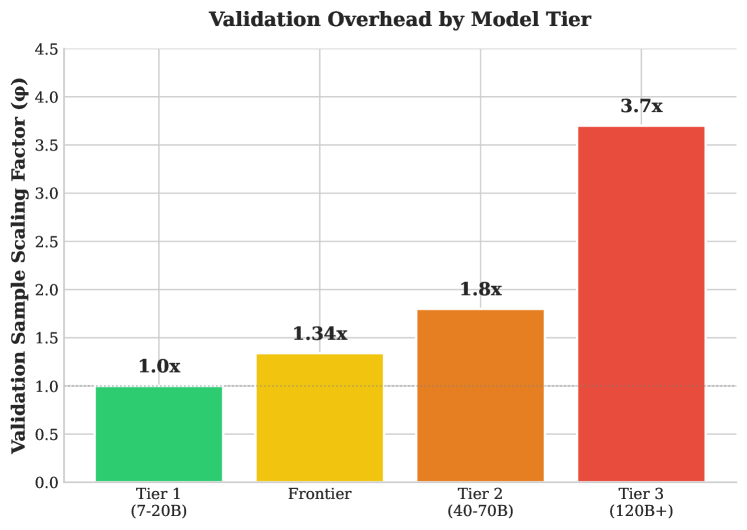
Large Language Model (LLM) tiers significantly influence system reliability. ‘Tier 1’ models demonstrate high output consistency, simplifying validation processes. Conversely, ‘Tier 3’ models exhibit greater inherent unpredictability, necessitating more extensive testing. Specifically, achieving comparable statistical reliability with a Tier 3 model requires a validation dataset 3.7 times larger than that needed for a Tier 1 model. This increased data requirement stems from the higher variance in Tier 3 model outputs, demanding a larger sample size to confidently establish performance metrics and identify potential failure modes.
Standardized financial benchmarks are essential for the objective evaluation of Large Language Model (LLM) agent performance and reliability. These benchmarks provide a consistent and quantifiable basis for comparing different agent configurations across various financial tasks, such as portfolio optimization, risk assessment, and fraud detection. Utilizing a common set of metrics – including accuracy, precision, recall, and Sharpe ratio – derived from these benchmarks minimizes subjective interpretation and allows for statistically significant comparisons. Furthermore, benchmark datasets enable the identification of performance regressions during model updates and facilitate the tracking of improvements over time. The availability of publicly accessible benchmarks fosters transparency and collaboration within the financial AI community, accelerating the development and deployment of reliable agent systems.
Scaling Validation and Real-World Impact
Determining adequate validation sample sizes for large language models presents a unique challenge, particularly when evaluating ‘lower-tier’ models intended for specific, less demanding tasks. The ‘Validation Scaling Factor’ addresses this by providing a quantifiable metric that moves beyond simple statistical power calculations. This factor accounts for anticipated model drift – the inevitable degradation of performance over time due to evolving data distributions – and dynamically adjusts the required sample size accordingly. Essentially, it recognizes that models operating in real-world environments are not static entities, and their validation must reflect this dynamism. By incorporating expected drift rates, the factor ensures that validation sets are sufficiently robust to detect performance declines before they impact operational efficiency, thus minimizing the risk associated with deploying potentially unreliable models and offering a proactive approach to maintaining model integrity.
The methodologies underpinning robust LLM validation extend seamlessly into the high-stakes realm of financial operations. Specifically, techniques designed to assess model reliability are proving invaluable in optimizing ‘Portfolio Constraint’ adherence, automating ‘Compliance Triage’ processes, and efficiently managing ‘DataOps Exception’ handling. By applying rigorous validation-and understanding the ‘Validation Scaling Factor’-financial institutions can confidently deploy LLM agents to identify potential constraint violations, flag suspicious transactions requiring review, and swiftly resolve data quality issues. This not only accelerates critical workflows but also minimizes the potential for costly errors and regulatory penalties, ultimately establishing a more resilient and efficient financial infrastructure.
Prioritizing determinism and faithfulness in Large Language Model (LLM) agents is paramount for reliable deployment in real-world applications. When these agents consistently produce the same output given the same input – determinism – and accurately reflect the underlying data and logic – faithfulness – it dramatically reduces the potential for unpredictable errors and biases. This increased predictability unlocks significant efficiencies by minimizing the need for constant monitoring and intervention. Furthermore, a focus on these qualities directly mitigates risk in sensitive domains, allowing organizations to confidently automate tasks previously requiring human judgment. Ultimately, deterministic and faithful LLM agents are not simply more accurate; they are foundational for building trust and realizing the full potential of artificial intelligence in critical operational processes.
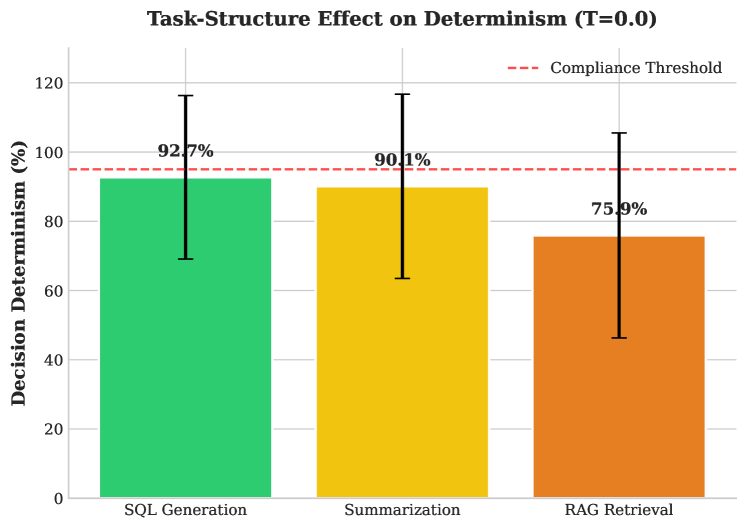
The research meticulously details how seemingly minor architectural choices within LLM agents-like model size and task optimization-propagate through the entire system, influencing both determinism and faithfulness. This echoes Donald Knuth’s observation: “Premature optimization is the root of all evil.” The study demonstrates that striving for overly complex, general-purpose agents can introduce unnecessary variability, hindering reproducibility – a critical concern in financial applications. Instead, focusing on streamlined, task-specific models-as highlighted by the findings-offers a path towards predictable and reliable behavior, aligning with the principle that elegant design arises from simplicity and clarity. Every new dependency, in this case, a layer of model complexity, is indeed a hidden cost of freedom from predictable outcomes.
Beyond Repeatability: Charting a Course for Reliable Agents
The Determinism-Faithfulness Assurance Harness (DFAH) offers a crucial, if sobering, observation: scale does not inherently guarantee stability. The finding that smaller, purpose-built models can surpass their larger counterparts in reproducibility forces a re-evaluation of prevailing optimization strategies. The field has largely equated parameter count with capability, often neglecting the underlying architectural coherence. What, precisely, are these agents optimizing for? Is it simply the completion of a task, or a consistent, explainable pathway towards that completion? The latter, it seems, demands a different kind of engineering-one focused on internal structure rather than brute force.
Future work must move beyond merely detecting non-determinism and faithfulness failures, toward proactive mitigation. A critical direction lies in developing formal methods for verifying agent behavior-techniques borrowed from established software engineering, but adapted to the probabilistic nature of large language models. This isn’t about imposing rigidity, but about building agents that demonstrate a predictable response to predictable stimuli.
Simplicity is not minimalism, but the discipline of distinguishing the essential from the accidental. The pursuit of increasingly complex agents risks obscuring the fundamental principles that govern reliable decision-making. A system is only as understandable as its underlying structure. Perhaps, the most fruitful path forward lies not in building more powerful agents, but in building agents that reveal how they think.
Original article: https://arxiv.org/pdf/2601.15322.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-01-24 20:00