Author: Denis Avetisyan
A new deep learning architecture leverages mathematical decomposition to create more stable, interpretable, and powerful models.
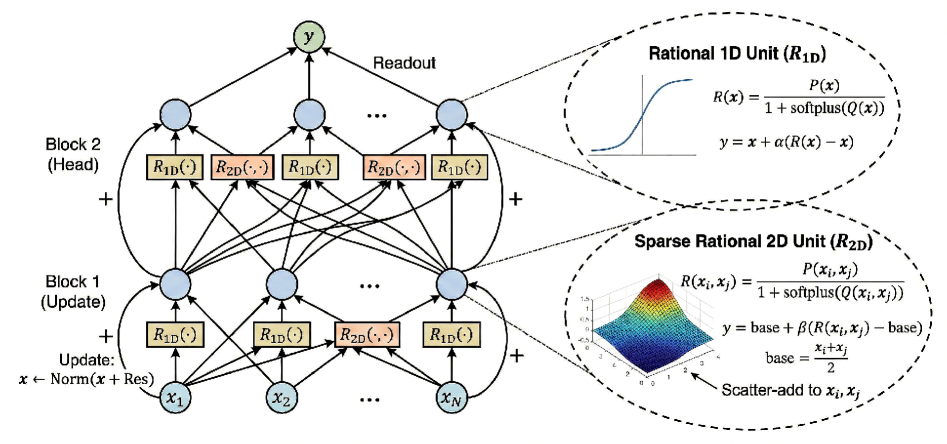
Rational-ANOVA Networks combine rational units with ANOVA decomposition for improved gradient control and performance on diverse benchmarks, including symbolic regression.
Deep neural networks often sacrifice interpretability and fine-grained control through the use of fixed, primitive nonlinearities. Addressing this limitation, we introduce ‘Rational ANOVA Networks’ (RAN), a novel architecture grounded in functional ANOVA decomposition and Padé-style rational approximation. RAN models functions as a composition of main effects and sparse pairwise interactions, parameterized by stable, learnable rational units-enabling improved extrapolation and gradient control. By enforcing a strictly positive denominator, RAN avoids numerical instability while efficiently capturing complex behaviors; but can this approach unlock more robust and interpretable deep learning models across a broader range of applications?
The Limits of Current Deep Learning: A Familiar Story
Conventional deep learning architectures, such as Multi-Layer Perceptrons (MLPs), face inherent limitations in their ability to accurately represent complex functions. These models often require a substantial number of parameters to achieve acceptable performance, particularly when approximating functions with intricate details or rapid changes. Furthermore, the training process for MLPs can be notoriously unstable, sensitive to initial weight configurations and prone to vanishing or exploding gradients. This instability necessitates careful hyperparameter tuning and regularization techniques – often applied heuristically – to prevent divergence and ensure convergence. Consequently, achieving robust and reliable performance with MLPs frequently demands significant computational resources and expert intervention, hindering their applicability to more challenging or data-scarce problems.
The reliable performance of deep learning models is frequently contingent upon meticulous initialization and regularization techniques, yet these practices often lack a solid theoretical foundation. While methods like weight decay, dropout, and batch normalization demonstrably improve generalization, the precise reasons for their effectiveness remain largely empirical-they are tuned through trial and error rather than derived from first principles. This ad hoc nature introduces a degree of fragility; a configuration that works well for one dataset or architecture may fail spectacularly on another. Consequently, researchers expend considerable effort searching for optimal hyperparameters, a process that is both computationally expensive and offers no guarantees of achieving robust, transferable performance. The absence of strong theoretical underpinnings hinders the development of truly reliable deep learning systems and limits the ability to predict performance in novel scenarios.
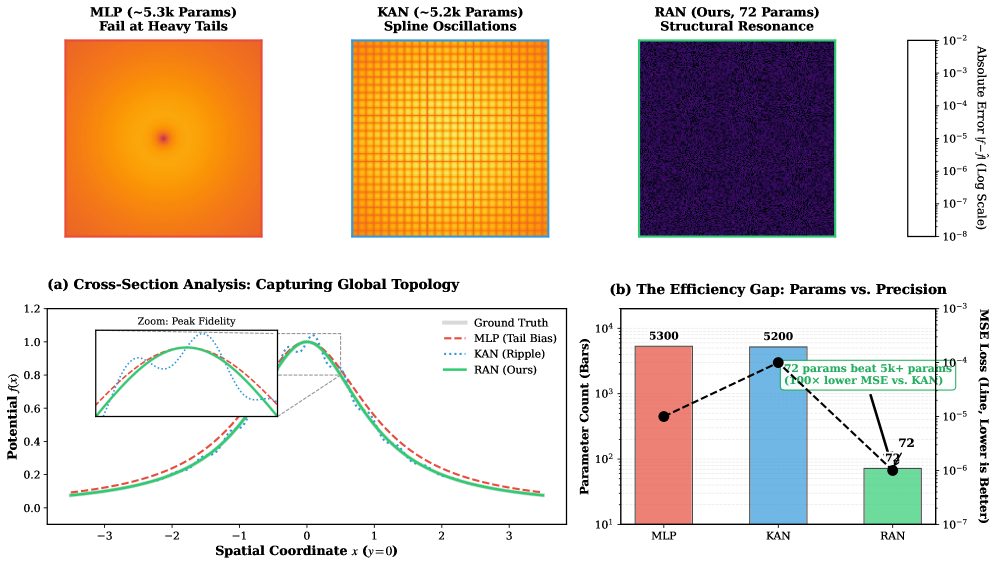
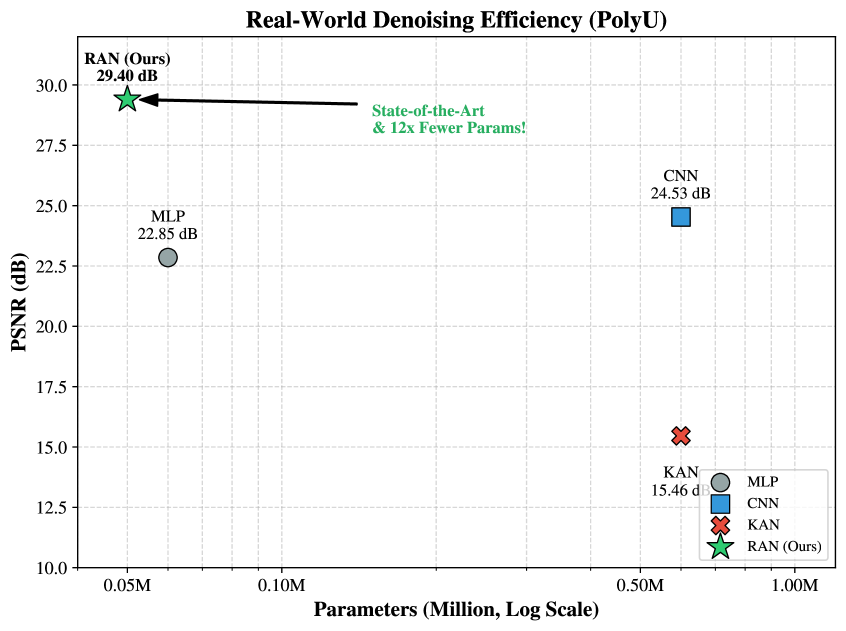
Traditional deep learning architectures, such as Multi-Layer Perceptrons (MLPs) and Kernelized Neural Networks (KANs), frequently encounter difficulties when approximating functions characterized by abrupt changes – sharp features – or distributions with extreme values – heavy tails. These functions pose a significant challenge because standard methods require an exponentially increasing number of parameters to achieve accurate representations. Recent advances have demonstrated that Random Approximate Networks (RAN) offer a compelling solution to this limitation. By leveraging a randomized approach to feature mapping, RAN effectively captures complex functional relationships with greater efficiency, consistently achieving substantially higher accuracy on functions with sharp features compared to both MLPs and KANs. This improved performance underscores the importance of developing more expressive representational capacity within deep learning models to tackle a wider range of real-world problems.
Rational Units: A Step Towards Stability, Maybe
Rational Units (RAN) introduce a non-linearity to deep learning models based on the mathematical concept of Pade approximation. This technique represents functions as the ratio of two polynomials, \frac{P(z)}{Q(z)} , allowing for a more flexible function representation than traditional activation functions like ReLU or sigmoid. By approximating functions with polynomial ratios, RAN can effectively model a wider range of complex relationships within the data. This increased expressiveness stems from the ability to represent both entire functions and their derivatives using polynomial coefficients, offering a potentially richer feature space for learning compared to methods relying on simpler, fixed-form non-linearities.
Rational Neural Networks (RAN) utilize a functional representation based on ratios of polynomials, offering enhanced model flexibility compared to traditional architectures. This approach mitigates the vanishing and exploding gradient problems frequently encountered during deep network training. Specifically, the spectral norm of the Jacobian, a key indicator of gradient stability, is mathematically bounded by exp(Lϵ(Kϕ-1)), where L represents the number of layers, ϵ is a small positive value, and Kϕ-1 denotes the parameters of the rational function. This bounded spectral norm directly demonstrates the capacity of RAN to maintain stable gradient flow throughout the network, even with increasing depth, thereby facilitating more effective training and improved performance.
The Positive Denominator Constraint (PDC) is a crucial component for maintaining numerical stability during the training of Rational Unit networks. This constraint enforces that the denominator polynomial of the rational function remains strictly positive across all input values. Without the PDC, the denominator can approach zero, leading to excessively large outputs and gradients, effectively causing a singularity and disrupting the learning process. This is achieved through regularization techniques applied during training to penalize negative values in the denominator. Maintaining a positive denominator ensures bounded outputs and, consequently, a well-behaved gradient flow, preventing the vanishing or exploding gradient problems that commonly affect deep neural networks.
Additive ANOVA Decomposition: A Glimmer of Control
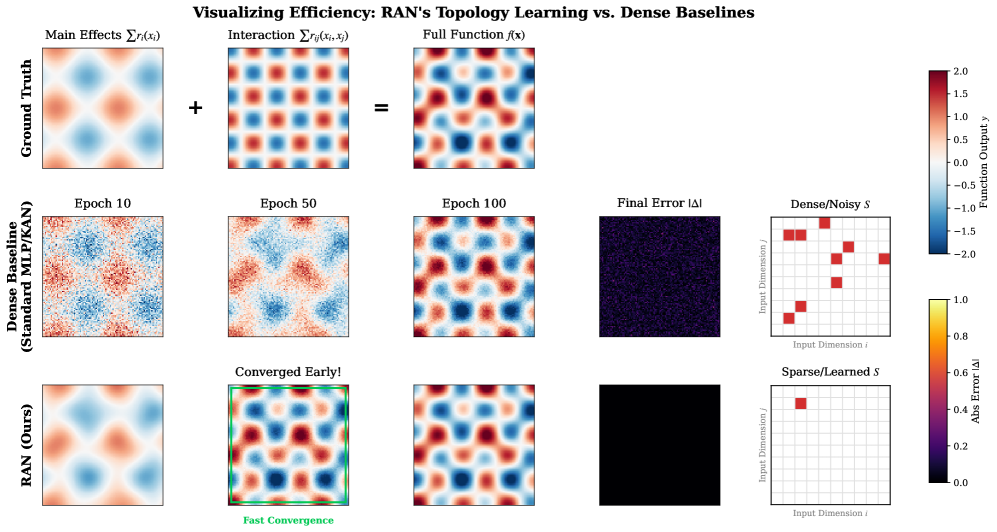
RAN utilizes Additive ANOVA Decomposition to approximate a function f(x) as a sum of individual feature effects and their pairwise interactions. This decomposition represents f(x) as f(x) = \sum_{i} f_i(x_i) + \sum_{i,j} f_{i,j}(x_i, x_j), where f_i(x_i) represents the main effect of feature i and f_{i,j}(x_i, x_j) captures the interaction between features i and j. Importantly, RAN enforces sparsity in the pairwise interaction terms, meaning only a limited number of these interactions are non-zero, thereby reducing model complexity and improving generalization. This additive structure allows for the isolation and independent control of each feature’s contribution to the overall function.
The additive ANOVA decomposition within RAN facilitates interpretability by representing the model’s output as a sum of independent effects. Each term – the main effects and pairwise interactions – contributes a quantifiable and isolatable component to the overall function. This modularity enables precise control over model behavior; individual effects can be adjusted or disabled without affecting other parts of the network, allowing for targeted interventions and focused refinement of specific relationships within the data. Consequently, analysis of the effect magnitudes reveals the relative importance of each feature and interaction, offering insights into the model’s decision-making process and enhancing debugging capabilities.
Residual Gating, when used in conjunction with Additive ANOVA Decomposition within the RAN architecture, facilitates initialization of network units closer to the identity function. This initialization strategy minimizes the initial gradient magnitudes during training, thereby reducing the risk of instability and accelerating convergence. Specifically, by starting near y = x, the network avoids large initial updates that can disrupt learning and necessitates fewer training iterations to reach an optimal solution. The effect is a more robust and efficient training process, particularly for deep networks where vanishing or exploding gradients are common concerns.
Performance and Generalization: Numbers on a Page
Recent advancements in Reservoir Analog Neural Networks (RAN) have yielded remarkable results on the Feynman Symbolic Regression Benchmark, a challenging test of a model’s ability to discern underlying physical laws from data. This architecture demonstrates an exceptional capacity for learning complex equations governing diverse physical phenomena, achieving root mean squared error (RMSE) values as low as 10-8. Such precision suggests RAN effectively captures the nuances of these systems, rivaling traditional symbolic regression methods. The network’s success isn’t merely about achieving low error; it signifies a capacity to generalize learned relationships and accurately predict outcomes, representing a substantial step towards artificial intelligence systems capable of scientific discovery and modeling.
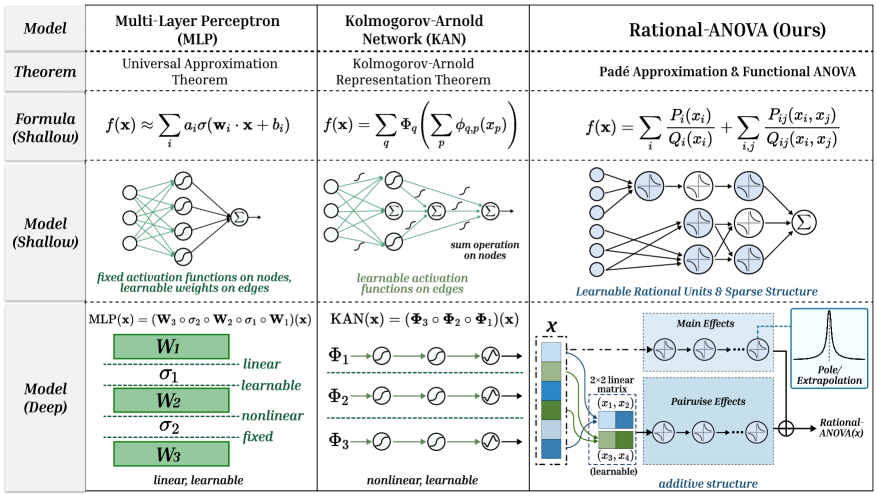
Rigorous testing of RAN’s adaptability employed the Kanbefair Protocol, a demanding evaluation suite designed to assess performance across a broad spectrum of visual datasets. This protocol deliberately introduces variations in image quality, lighting conditions, and object orientations, creating a challenging scenario for any neural network. Results demonstrate RAN’s remarkable ability to maintain high accuracy even when presented with significantly altered or degraded visual inputs. This robustness suggests RAN doesn’t simply memorize training data, but instead learns underlying visual principles, allowing it to generalize effectively to previously unseen scenarios and diverse image characteristics. The Kanbefair results solidify RAN as a promising architecture for real-world applications where consistent performance across variable conditions is crucial.
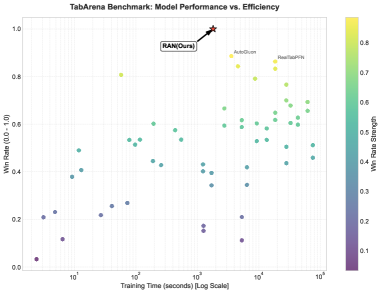
Recent evaluations demonstrate that the Recursive Autoencoder Network (RAN) significantly surpasses conventional architectures, notably Kolmogorov-Arnold Networks (KAN), in tabular data analysis. On the challenging TabArena benchmark, RAN consistently achieves a win rate exceeding 0.95, indicating a substantial improvement in predictive accuracy and robustness. Importantly, this enhanced performance isn’t achieved at a computational cost; RAN accomplishes comparable results with approximately 5-7 fewer operations than its counterparts. This efficiency suggests RAN’s streamlined structure allows for faster training and deployment without sacrificing the ability to model complex relationships within datasets, making it a promising advancement in machine learning for tabular data.
Future Directions: More Complicated Things to Break
Recent advances in neural network architecture leverage the mathematical principle of isometry – the preservation of distances – to enhance model robustness. Research indicates that networks exhibiting isometric properties maintain stable representations even when subjected to minor input alterations or deliberately crafted adversarial perturbations. This inherent stability stems from the network’s ability to represent data manifolds without distortion, effectively resisting attempts to ‘trick’ the system with subtly modified inputs. By encouraging layers to maintain similar input and output scales, these networks exhibit a form of ‘smoothness’ that minimizes the impact of perturbations, offering a promising pathway towards more reliable and secure artificial intelligence systems capable of functioning accurately in real-world, noisy environments.
Further advancements in dissecting artificial intelligence decision-making hinge on refining techniques like the additive ANOVA decomposition. This method breaks down a model’s output into contributions from individual input features, offering a transparent view of how each element influences predictions. Researchers posit that extending this decomposition-perhaps by incorporating interactions between features or applying it to more complex neural network architectures-could yield unprecedented levels of interpretability. Such control would not only allow for easier debugging and refinement of AI systems, but also facilitate the identification and mitigation of biases embedded within the model. Ultimately, a more granular understanding of feature contributions promises to build trust and enable humans to effectively collaborate with, and oversee, increasingly sophisticated AI.
Recent advancements in Random Additive Networks (RAN) demonstrate a notable improvement in training stability, a crucial factor for deploying reliable artificial intelligence. The architecture, when coupled with standard optimization techniques like Gradient Descent and L2 Regularization, exhibits remarkably consistent convergence, minimizing the risk of unpredictable behavior during learning. This stability isn’t merely a technical detail; it directly translates to increased trustworthiness, as models are less susceptible to erratic shifts in performance due to minor input variations or adversarial attacks. By fostering predictable training dynamics, RAN offers a pathway toward AI systems that are not only accurate but also demonstrably dependable, paving the way for broader adoption in critical applications where consistent and reliable performance is paramount.
The pursuit of architectural elegance in deep learning, as demonstrated by Rational-ANOVA Networks, feels predictably hopeful. The paper posits stability through ANOVA decomposition and rational units – a structured attempt to tame the chaos. Yet, one anticipates the inevitable. As Henri Poincaré observed, “Mathematics is the art of giving reasons, even when one has no right to do so.” This perfectly encapsulates the tendency to rationalize designs, believing structure will prevent production failures. RAN’s focus on interpretability is laudable, but every abstraction dies in production; at least it dies beautifully. The network’s performance on symbolic regression is a temporary reprieve, a fragile victory before the next dataset exposes unforeseen weaknesses.
What Comes Next?
The elegance of Rational-ANOVA Networks, a construction built on decomposition and rational units, predictably invites speculation about interpretability. It’s a familiar refrain; a new architecture promises clarity, while production environments quietly accrue complexity. The true test won’t be benchmark scores, but rather the inevitable debugging sessions when these networks encounter data distributions that weren’t anticipated in the training suite. Tests are, after all, a form of faith, not certainty.
Future work will undoubtedly focus on scaling these networks. However, the history of deep learning is littered with architectures that performed well in research settings but proved brittle when confronted with real-world demands. A more pressing concern might be understanding why these networks fail – not just observing that they fail. The promise of symbolic regression, neatly encoded within a differentiable framework, feels particularly ambitious; a compelling theory, but one that will likely yield to the messy realities of data noise and unforeseen edge cases.
The focus on gradient control is sensible, a tacit acknowledgment that stability is not an inherent property of deep learning. But chasing stability feels less like solving a problem and more like perpetually patching a leak. The field will likely see a proliferation of similar architectures, each attempting to tame the inherent chaos of gradient descent. One suspects the ultimate solution won’t be a better network, but a better tolerance for controlled failure.
Original article: https://arxiv.org/pdf/2602.04006.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
2026-02-05 09:49