Author: Denis Avetisyan
Researchers have developed a novel framework that combines the benefits of additive models with the power of expert systems to achieve both high accuracy and clear interpretability.
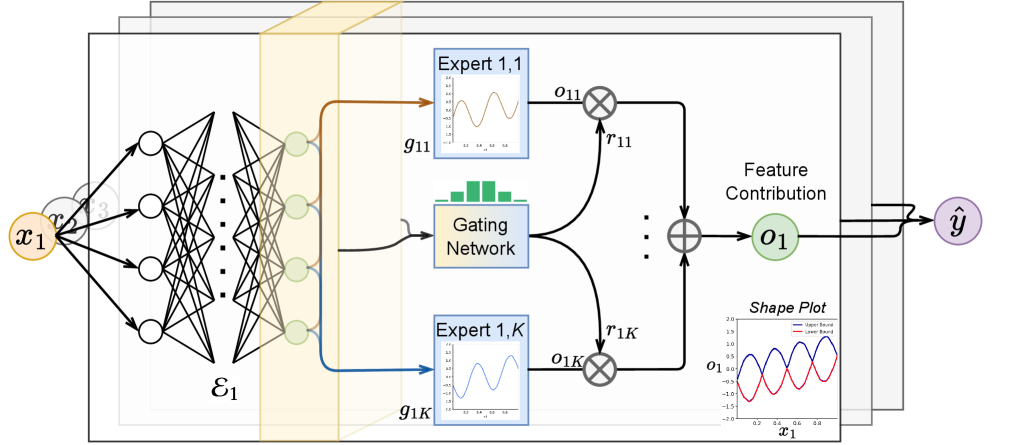
Neural Additive Experts offer a dynamically-gated mixture of experts, enabling controllable accuracy and transparent modeling of feature interactions.
Balancing model accuracy with the need for transparent, feature-level explanations remains a persistent challenge in machine learning. This paper introduces ‘Neural Additive Experts: Context-Gated Experts for Controllable Model Additivity’, a novel framework that extends Generalized Additive Models by employing a mixture of experts and dynamic gating mechanisms. This approach allows for flexible modeling of feature interactions while retaining interpretability and offering a tunable trade-off between predictive performance and transparency. By learning specialized networks per feature and integrating information contextually, can NAEs unlock a new paradigm in both accurate prediction and understandable model behavior?
The Limits of Additive Linearity
Generalized Additive Models (GAMs) have long been favored for their ability to clearly delineate the influence of individual predictors on an outcome, offering a readily understandable relationship between variables. However, this very strength becomes a limitation when reality dictates more nuanced connections. Traditional GAMs assume a simple additive effect – each predictor contributes independently. This approach falters when variables interact, meaning the effect of one predictor changes depending on the value of another. Consequently, a model built on these assumptions may miss crucial predictive power stemming from these non-linear relationships, leading to underperformance in complex datasets where feature interactions are prevalent. The inability to capture these subtleties restricts the model’s capacity to accurately represent the underlying data-generating process, hindering both predictive accuracy and a complete understanding of the system being modeled.
Despite the demonstrated power of deep learning architectures in discerning intricate relationships within data, a significant trade-off often accompanies this capability. These models, characterized by numerous layers and parameters, frequently operate as ‘black boxes’ – achieving high predictive accuracy while obscuring the specific contributions of individual features or their interactions. This lack of transparency hinders understanding why a prediction was made, which is crucial in fields demanding accountability or where insights are as valuable as accurate forecasts. Furthermore, the computational demands of training and deploying deep learning models can be substantial, requiring significant resources and limiting their applicability in resource-constrained environments or for real-time applications. The complexity inherent in these models not only increases computational cost but also necessitates large datasets to prevent overfitting, creating practical barriers to their widespread adoption.
Current modeling approaches present a fundamental trade-off between predictive accuracy and analytical insight. Traditional statistical methods, while readily interpretable, often fall short when confronted with the intricate relationships inherent in real-world data, struggling to model interactions beyond simple linear effects. Conversely, the sophisticated architectures of deep learning, capable of capturing these complex interactions, frequently operate as ‘black boxes’, obscuring the specific contributions of individual features. This disparity highlights a critical need for novel modeling techniques – those that can simultaneously achieve high predictive power and provide researchers with a clear understanding of how each variable influences the outcome, bridging the gap between pure prediction and meaningful scientific discovery. The development of such models would empower more informed decision-making and accelerate progress across diverse fields by revealing the underlying mechanisms driving observed phenomena.
Neural Additive Experts: A Mathematically Elegant Solution
Neural Additive Experts (NAE) build upon the Generalized Additive Model (GAM) framework by substituting the univariate functions traditionally used to model feature effects with dedicated neural networks, termed ‘expert networks’. In a standard GAM, the prediction is decomposed into the sum of functions applied to individual features; NAE preserves this additive structure but replaces these simple functions with parameterized neural networks capable of learning more complex, non-linear relationships. Each expert network processes a single feature’s input, allowing the model to capture nuanced feature-specific patterns that would be inaccessible to linear or simple parametric functions. This substitution maintains the overall additive form of the model, facilitating analysis of individual feature contributions while increasing representational capacity.
The dynamic gating mechanism within Neural Additive Experts (NAE) functions by learning a weighted combination of the predictions generated by each individual expert network. These weights are not static; instead, they are determined by a gating network that takes the input features as input and outputs a set of weights, one for each expert. This allows the model to adaptively emphasize the contributions of different experts based on the specific input instance, enabling the capture of complex feature interactions beyond simple additivity. The gating network effectively modulates the influence of each expert, facilitating nuanced and context-dependent predictions and allowing for non-linear relationships to be modeled without requiring explicit interaction terms.
The Neural Additive Experts (NAE) architecture facilitates non-linear relationships between input features and the model’s predictions without entirely sacrificing interpretability. Rather than relying on strictly linear combinations of features, NAE utilizes expert networks to model each feature’s contribution, allowing for complex, non-linear transformations. Crucially, the overall prediction is formed by summing the outputs of these individual expert networks, enabling a decomposition of the final result into feature-specific effects; this additive structure permits analysis of each feature’s influence on the prediction, providing a degree of transparency not typically found in highly non-linear models like deep neural networks.
Refining NAE: Optimization Through Rigorous Control
Neural Additive Experts (NAE) rely on effective feature encoding to generate latent representations that serve as input to the expert networks. These encoded features are critical, as the experts subsequently learn to model complex relationships and interactions within the data based solely on these representations. The quality of the encoding directly impacts the ability of the experts to specialize and accurately capture the underlying data distribution; poorly encoded features can limit the model’s capacity to learn and generalize effectively. Consequently, careful consideration must be given to the feature engineering and transformation processes to ensure the expert networks receive meaningful and informative input.
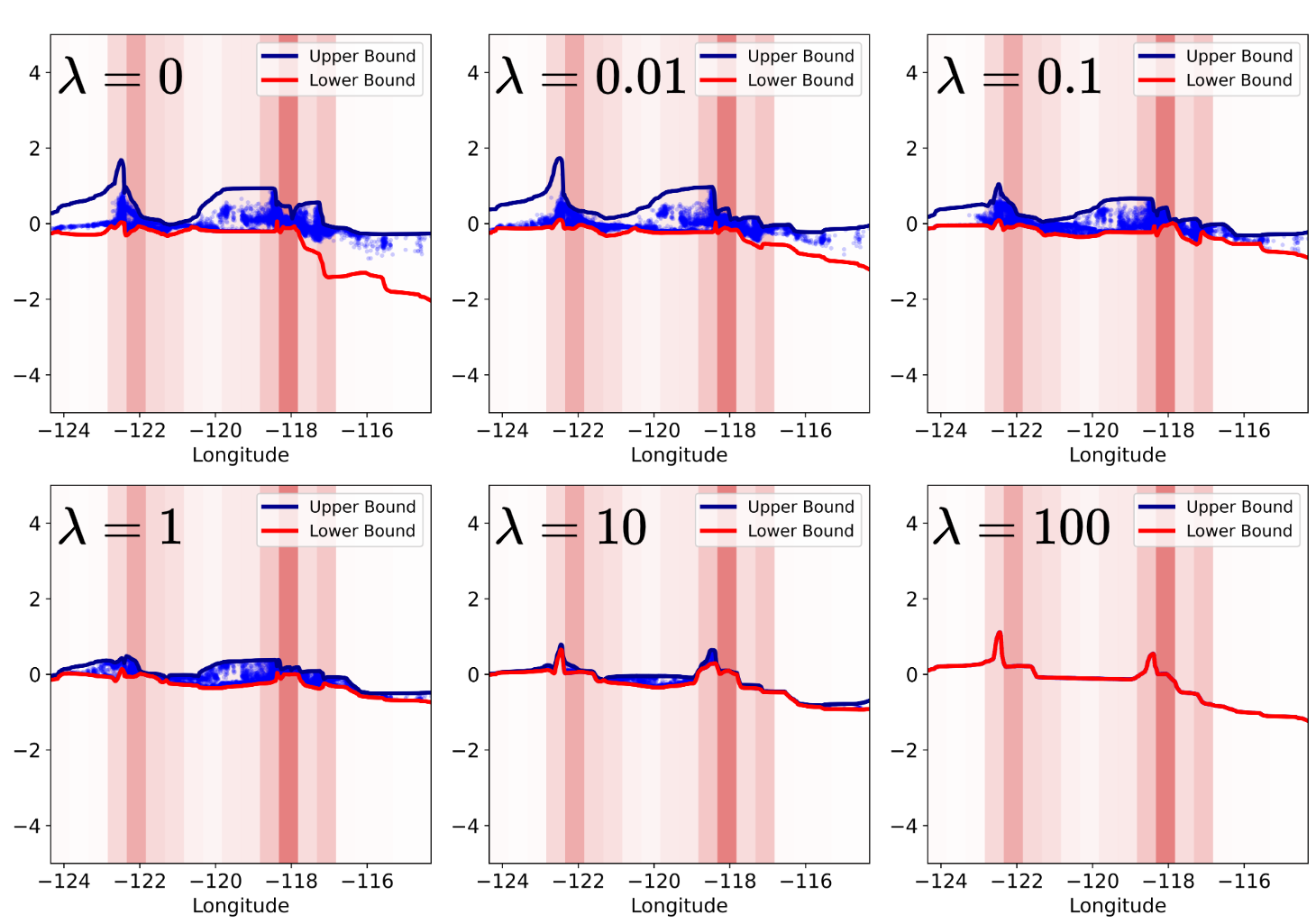
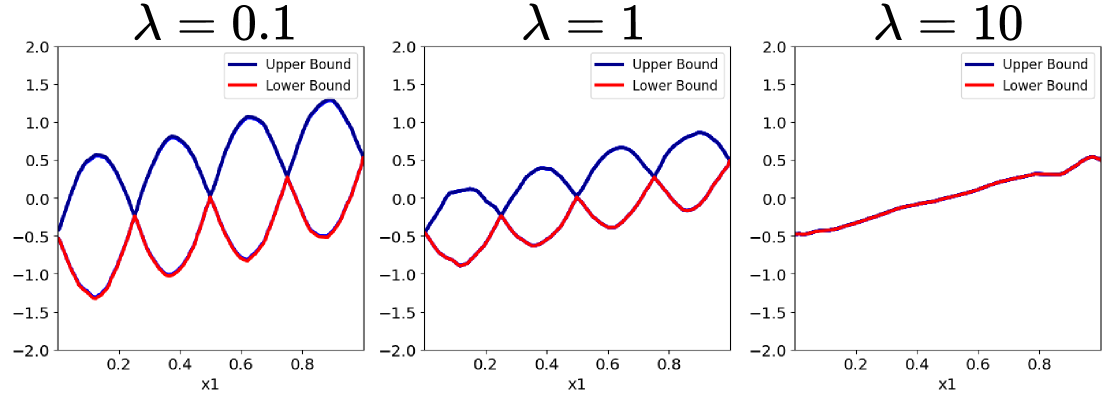
Regularization is incorporated into the Networked Attention Experts (NAE) model to mitigate overfitting and improve generalization performance on unseen data. This is achieved by adding a penalty term to the loss function, discouraging excessively large weights in the model parameters. Specifically, this penalty constrains model complexity by reducing the variance of the learned representations, thereby preventing the model from memorizing the training data and enabling it to better capture underlying patterns. The strength of this regularization is controlled by a hyperparameter, allowing for adjustment based on the specific dataset and model configuration to optimize the balance between model fit and generalization ability.
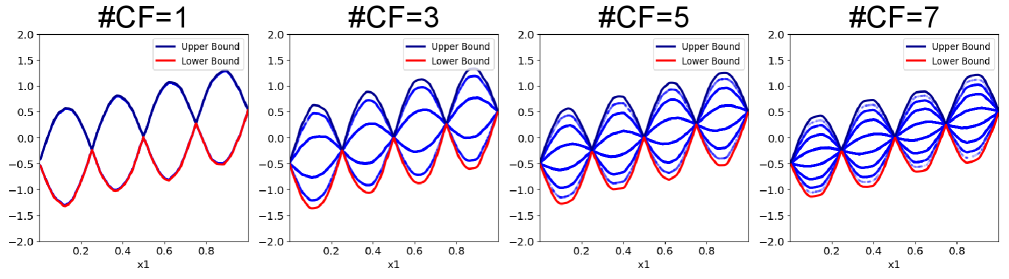
Evaluations on the Housing dataset demonstrate that the Novel Attention Encoder (NAE) achieves a Root Mean Squared Error (RMSE) of 0.1306. This performance indicates an improved capacity to model complex feature interactions compared to baseline models. Further optimization is achieved through the implementation of a sparsity-inducing mask within the gating network; this mask selectively sets less significant attention scores to zero, resulting in a more efficient model with a reduced computational footprint without sacrificing predictive accuracy.
Scaling and Adapting NAE: Efficient Architectures for Practical Deployment
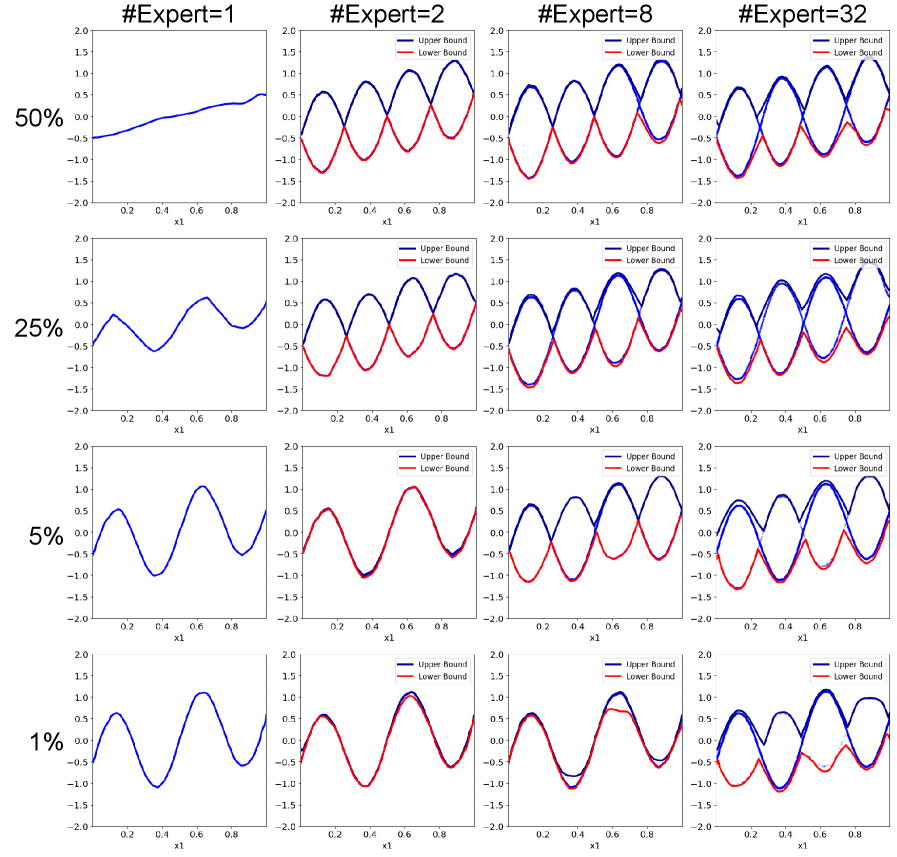
NAE-D reduces computational complexity by implementing a diagonal routing matrix. This simplification constrains the connections between input features and mixture of experts to only those along the matrix diagonal, effectively limiting the number of parameters requiring computation during the routing stage. While this introduces a degree of restriction, performance evaluations indicate that the reduction in parameters does not result in a substantial decrease in model accuracy, offering a favorable trade-off between computational efficiency and predictive capability. This approach is particularly beneficial in scenarios with high-dimensional input data where the full routing matrix would incur significant computational overhead.
NAE-E implements a discrete expert selection process characterized by evenly distributed expert activation. This approach contrasts with methods that dynamically weight or select experts based on input features; instead, NAE-E assigns activation across all experts in a uniform manner for each input. By distributing activation evenly, NAE-E reduces the reliance on any single expert, thereby mitigating potential instability caused by over-reliance or catastrophic failure of a particular expert. This uniform activation strategy contributes to a more robust and predictable model behavior, particularly in scenarios with noisy or ambiguous input data.
Evaluations using simulated datasets featuring correlated features indicate that the NAE architecture maintains a low Root Mean Squared Error (RMSE), while the performance of the NAM (Naive Additive Model) degraded under the same conditions. This performance difference highlights NAE’s increased robustness when processing data with high feature correlation. Consequently, NAE and its variants, NAE-D and NAE-E, demonstrate adaptability to challenging data characteristics and present a viable option for deployment in environments where computational resources are limited and data quality may be variable.
Towards Interpretable and Accurate Predictions: A Paradigm for Trustworthy AI
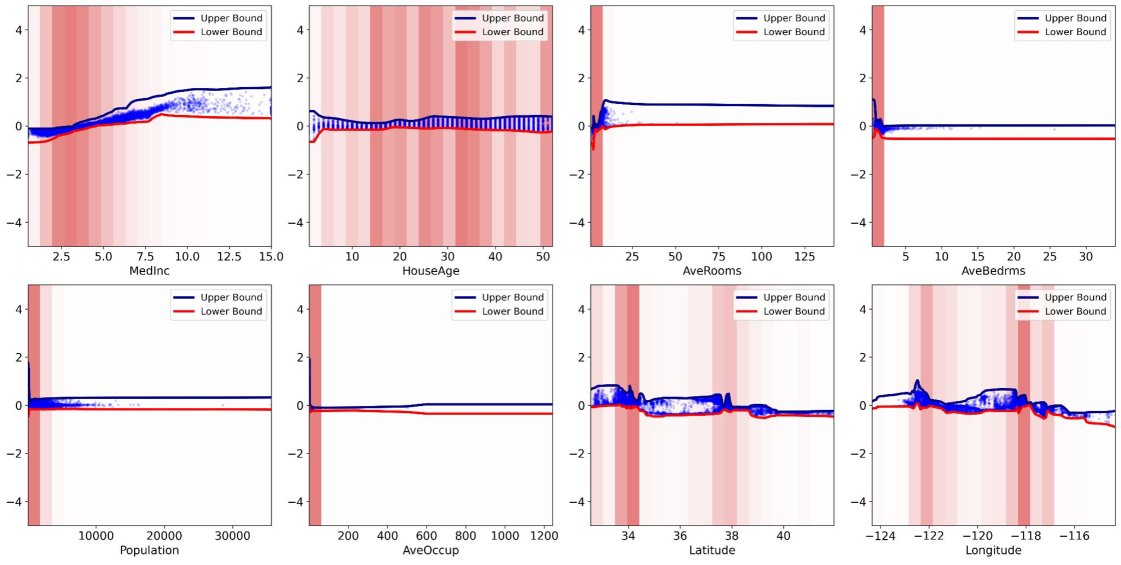
Neural Additive Models (NAE) present a compelling advancement in machine learning by uniquely balancing predictive power with the capacity for clear explanation. Unlike many high-performing models that operate as ‘black boxes’, NAE decomposes predictions into contributions from individual features, allowing for a direct understanding of how each input influences the outcome. This characteristic is particularly valuable in fields demanding both accuracy and transparency – such as healthcare, finance, and criminal justice – where simply knowing a prediction isn’t enough; stakeholders require insight into why that prediction was made. The ability to model complex, non-linear relationships between features – often critical for real-world accuracy – is achieved without sacrificing the interpretability inherent in additive models, offering a practical solution for building trustworthy and actionable artificial intelligence systems.
Neural Additive Models (NAE) enhance the reliability of predictions by revealing how each input feature contributes to the final outcome. This decomposition isn’t merely a post-hoc explanation; it’s integral to the model’s architecture, allowing for a granular understanding of its reasoning. Consequently, debugging becomes significantly easier, as developers can pinpoint specific features driving erroneous predictions. More importantly, this transparency fosters trust in the model, especially vital in sensitive applications like healthcare or finance, where understanding the basis of a decision is paramount. The ability to trace predictions back to their constituent features doesn’t just improve model performance; it empowers informed decision-making by providing stakeholders with clear, interpretable insights.
The architecture underpinning this novel approach is designed not as a culminating point, but rather as a springboard for continued innovation. Its modular construction and adaptable framework readily accommodate the integration of context-gated experts, a concept poised to enhance the model’s ability to selectively focus on relevant features based on input context. Furthermore, the framework’s scalability suggests avenues for developing even more efficient architectures – potentially through techniques like network pruning or quantization – without sacrificing predictive power or, crucially, interpretability. This inherent flexibility promises a sustained trajectory of refinement, allowing researchers to explore increasingly sophisticated models capable of tackling complex challenges while retaining the vital capacity for transparent and trustworthy predictions.
The pursuit of controllable accuracy, as demonstrated by Neural Additive Experts, echoes a fundamental principle of rigorous computation. Alan Turing once stated, “Sometimes people who are not very good at games, or at anything much, can still offer a kind of insight.” This insight aligns with the framework’s ability to dissect complex interactions into manageable, interpretable components. The model doesn’t merely achieve a result; it reveals how that result is achieved, mirroring the desire for provable algorithms rather than black boxes. This approach offers a predictable boundary, permitting adjustments to model complexity and transparency without sacrificing performance – a testament to mathematical purity in the realm of neural networks.
What Remains?
The pursuit of controllable accuracy, as demonstrated by Neural Additive Experts, circles a fundamental question: Let N approach infinity – what remains invariant? The framework rightly addresses the limitations of purely additive models by introducing dynamic feature interactions. However, the gating mechanism itself becomes a complexity to be scrutinized. While interpretability is improved relative to monolithic networks, the interpretability of the gate – its decision boundaries in feature space – requires further rigorous analysis. Does increased control simply shift the opacity from the core model to the controller?
Future work must move beyond empirical demonstration. Formal guarantees regarding the sparsity and stability of the expert contributions are essential. The current reliance on differentiable approximations introduces potential for subtle, yet critical, errors. A truly elegant solution would derive these expert systems not from gradient descent, but from first principles – perhaps a re-examination of kernel methods or symbolic regression, guided by the desire for provable additivity.
Ultimately, the value of Neural Additive Experts lies not in achieving state-of-the-art accuracy-many architectures accomplish that-but in forcing a reckoning with the trade-offs between complexity and understanding. The field should not settle for ‘good enough’ interpretability; it must strive for mathematical certainty.
Original article: https://arxiv.org/pdf/2602.10585.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-02-15 05:35