Author: Denis Avetisyan
New autoregressive models are pushing the boundaries of knowledge graph generation by learning the underlying structure of data and predicting new relationships.
This review explores autoregressive approaches, including ARK and SAIL, for generating semantically valid knowledge graphs using latent variable models and graph neural networks.
Constructing coherent and valid knowledge graphs remains challenging due to the need to model complex relationships between entities and adhere to domain-specific constraints. This paper introduces a novel approach, ‘Autoregressive Models for Knowledge Graph Generation’, presenting ARK and SAIL, autoregressive models that generate knowledge graphs by treating them as sequences of triples and learning implicit constraints directly from data. Our models achieve state-of-the-art semantic validity on the IntelliGraphs benchmark, demonstrating the potential for both knowledge base completion and controlled graph generation via learned latent representations. Does this framework offer a computationally efficient path towards building and augmenting large-scale knowledge resources?
Beyond Data: Structuring Knowledge with Graphs
Conventional data storage methods, such as relational databases and simple spreadsheets, often fall short when representing intricate connections between pieces of information. These systems excel at storing discrete facts, but struggle to articulate how those facts relate to one another, limiting their capacity for sophisticated analysis. For instance, understanding that “Marie Curie discovered radium” requires not just the two facts themselves, but also the relationship – “discovered” – linking them. When these relationships are implicit or absent, advanced reasoning tasks – like inferring new knowledge or predicting future outcomes – become significantly more difficult, if not impossible. This limitation hinders applications in fields ranging from medical diagnosis to fraud detection, where understanding context and complex dependencies is crucial for accurate and insightful results.
Knowledge Graphs represent a paradigm shift in how information is structured and utilized, moving beyond simple data tables to create richly interconnected networks of knowledge. Rather than passively storing facts, these graphs actively define entities – real-world objects, concepts, or events – and the relations that connect them. This explicit modeling allows systems to not just retrieve information, but to reason about it; for example, understanding that ‘Paris’ is a ‘City’ that is ‘located in’ ‘France’. This relational structure unlocks capabilities beyond traditional databases, enabling advanced applications like semantic search, recommendation systems, and complex question answering, where understanding context and connections is paramount. The power lies in representing not just what is known, but how things relate, fostering a more nuanced and intelligent interaction with information.

Autoregressive Knowledge Graph Construction
Autoregressive models are specifically designed for generating sequences of data, making them well-suited for Knowledge Graph (KG) construction. Traditional KG creation often involves defining a schema and then populating it; however, autoregressive approaches treat KG construction as a sequential prediction task. Each element of the KG – represented as a triple consisting of subject, predicate, and object – is generated one at a time, conditioned on the previously generated triples. This sequential generation allows the model to maintain consistency and coherence within the graph, as each new triple is predicted in the context of the existing KG structure. The method contrasts with approaches that generate all triples simultaneously, potentially leading to inconsistencies or requiring complex constraints to ensure validity.
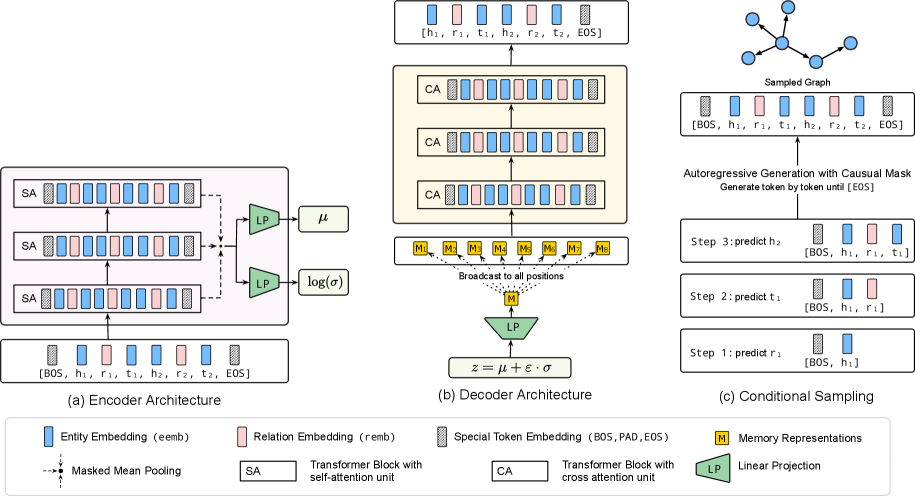
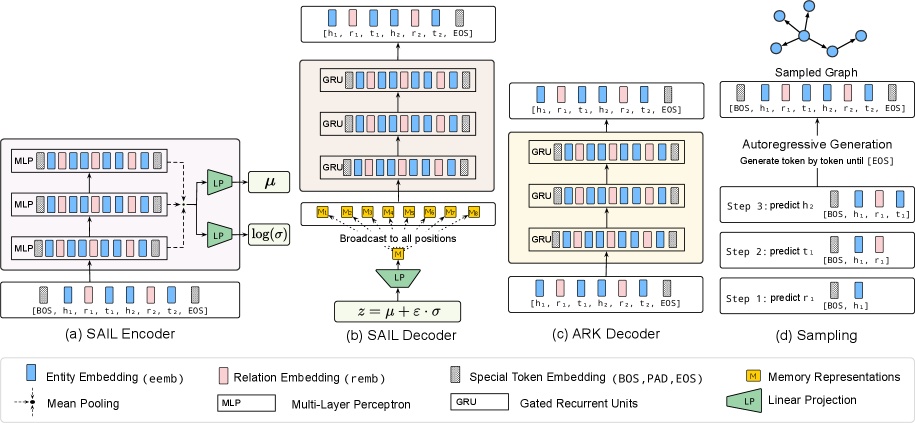
ARK constructs Knowledge Graphs through an autoregressive process, generating triples sequentially. Each new triple prediction is conditioned on the entirety of previously generated triples, establishing a dependency on the existing graph structure. This approach allows the model to iteratively ‘grow’ the Knowledge Graph, with each added triple informed by the context established by its predecessors. The predicted triple consists of a subject, predicate, and object, forming a relational statement added to the graph. This sequential generation contrasts with methods that attempt to generate the entire graph simultaneously, offering advantages in scalability and control over graph coherence.
Gated Recurrent Units (GRUs) are employed within ARK to capture long-range dependencies inherent in the sequential generation of knowledge graph triples. Unlike traditional Recurrent Neural Networks, GRUs utilize update and reset gates to control the flow of information, mitigating the vanishing gradient problem and enabling the model to effectively learn relationships between triples generated at different steps in the sequence. This allows ARK to consider previously generated triples when predicting subsequent ones, resulting in a more coherent and accurate knowledge graph construction compared to models lacking such contextual awareness. The GRU architecture’s ability to retain relevant information over extended sequences directly contributes to improved generation quality and overall graph consistency.
Introducing Control: Latent Variables and SAIL
SAIL builds upon the ARK knowledge graph completion framework by integrating a Variational Autoencoder (VAE). This incorporation introduces latent variables, represented as a probability distribution, which serve as a control mechanism during triple generation. The VAE learns a compressed, lower-dimensional representation of the existing knowledge graph data, and samples from this latent space are used to condition the generation of new triples. By manipulating these latent variables, SAIL can explore different areas of the knowledge space, enabling the creation of diverse and potentially novel relationships while still grounding the generated triples in the established data distribution.
SAIL utilizes latent variables to enhance triple generation by introducing stochasticity into the decoding process. These variables, learned through a Variational Autoencoder, provide a continuous representation that allows the model to sample diverse outputs from the learned data distribution. This sampling capability enables SAIL to generate novel triples – those not explicitly present in the training data – while still adhering to the structural and semantic constraints of the Knowledge Graph. The latent space effectively regularizes the generation process, promoting semantic validity by ensuring generated triples remain consistent with the existing knowledge and relationships represented within the graph.
SAIL employs Kullback-Leibler (KL) Divergence as a regularization term during training to manage the trade-off between generating novel triples and maintaining semantic coherence within the Knowledge Graph. KL Divergence measures the difference between the distribution of learned latent variables and a predefined prior distribution – typically a standard normal distribution. Minimizing this divergence encourages the latent space to remain well-behaved and prevents the model from generating completely random or incoherent triples. A higher weighting on the KL Divergence term promotes coherence by constraining the latent variables to resemble the prior, while a lower weighting allows for greater exploration of the latent space and potentially more novel, albeit potentially less coherent, triple generation. This optimization process ensures that SAIL generates diverse triples while adhering to the structural and semantic constraints of the underlying Knowledge Graph.
Evaluation of SAIL on the IntelliGraphs benchmark demonstrates a high degree of semantic validity in generated triples, ranging from 89.2% to 100%. This metric assesses the factual correctness of the generated statements with respect to existing knowledge within the graph. The reported range indicates consistent performance across different experimental configurations and datasets used within the IntelliGraphs evaluation suite, signifying SAIL’s ability to reliably produce logically sound and contextually appropriate Knowledge Graph additions.
Beam Search is employed during triple generation to enhance the quality of the constructed Knowledge Graph. This algorithm maintains a specified number of candidate sequences – the “beam” – at each generation step, evaluating them based on a defined scoring function. Rather than selecting the single most probable continuation at each step, Beam Search explores multiple high-probability options, ultimately choosing the sequence with the highest cumulative score. This process mitigates the risk of prematurely committing to suboptimal continuations, resulting in more coherent and semantically valid triples and improving the overall quality of the generated Knowledge Graph compared to greedy decoding approaches.
Benchmarking and the Pursuit of Knowledge Graph Excellence
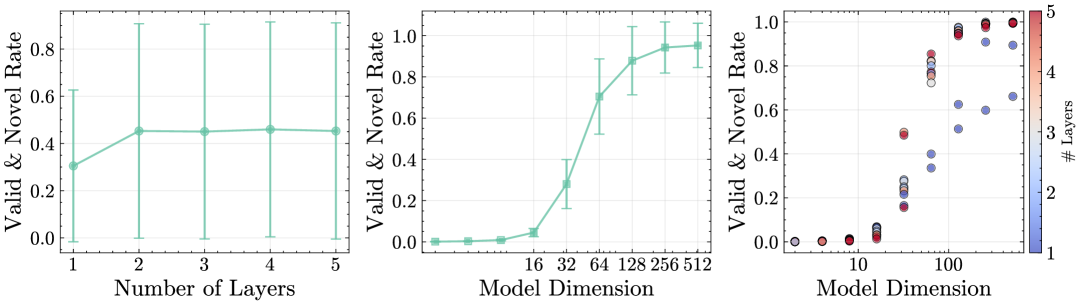
Evaluations conducted on the IntelliGraphs benchmark reveal that both SAIL and ARK demonstrate a robust capacity for generating high-quality Knowledge Graphs. This assessment utilized a diverse suite of metrics designed to quantify not only the structural integrity of the generated graphs, but also the validity and relevance of the contained information. The models were challenged with reconstructing complex relationships and entities, and their performance was rigorously measured against established baselines. Results indicate a significant ability to capture essential knowledge and represent it in a coherent and accessible format, highlighting the potential of these models for applications requiring structured knowledge representation and reasoning.
Recent evaluations demonstrate that SAIL attains state-of-the-art compression performance on the wd-movies and wd-articles datasets, achieving remarkably concise knowledge graph representations. Specifically, SAIL compresses wd-movies to a length of just 98.19 bits and wd-articles to 199.55 bits – significantly outperforming prior models in terms of data efficiency. This superior compression isn’t merely about smaller file sizes; it indicates a more effective encoding of information, suggesting SAIL captures the essential relationships within these complex datasets with greater precision and minimizes redundancy. The ability to represent substantial knowledge graphs with so few bits has implications for storage, transmission, and processing, potentially enabling broader applications in resource-constrained environments and facilitating faster knowledge retrieval.
Evaluating the performance of knowledge graph generation models requires careful consideration of competing priorities, and metrics like compression and novelty offer crucial insights into these trade-offs. Compression, measured in bits, quantifies how efficiently a model can represent the generated knowledge graph – lower bit counts indicate a more concise and potentially more generalizable structure. However, achieving extreme compression shouldn’t come at the expense of introducing novel, yet valid, information. Novelty, therefore, assesses the proportion of previously unseen triples within the generated graph, signaling the model’s capacity to expand existing knowledge. A balanced approach, reflected in both high compression and substantial novelty, demonstrates a model’s ability to create knowledge graphs that are simultaneously compact, informative, and capable of enriching existing datasets. These metrics, when considered together, provide a holistic understanding of a model’s strengths and weaknesses, guiding further development and optimization.
The architecture of SAIL fosters enhanced Knowledge Graph generation through controlled outputs, proving particularly beneficial when diversity and informational richness are paramount. Unlike models that produce homogeneous or repetitive structures, SAIL utilizes guiding mechanisms to encourage the creation of varied relationships and entities within the Knowledge Graph. This capability is demonstrated by its ability to consistently generate more novel triples – unique statements about entities and their connections – while maintaining high levels of factual accuracy. Consequently, scenarios demanding comprehensive and nuanced representations, such as building specialized databases or exploring complex research topics, see significant improvements when leveraging SAIL’s controlled generation approach, resulting in Knowledge Graphs that are both informative and adaptable.
The architecture of SAIL uniquely supports conditional Knowledge Graph generation, allowing for the creation of highly specialized graphs designed to fulfill specific requirements. Unlike models producing generic knowledge bases, SAIL can be steered via input prompts to prioritize certain entities, relations, or topics during graph construction. This capability proves particularly valuable in scenarios demanding focused knowledge – for example, building a Knowledge Graph centered on a particular scientific field, a specific historical period, or the attributes of a defined product line. By controlling the generative process, SAIL doesn’t simply produce knowledge; it curates it, resulting in more relevant, concise, and informative Knowledge Graphs that are precisely tailored to the user’s intended application and eliminating extraneous information.

The pursuit of semantic validity, central to ARK and SAIL’s autoregressive approach, echoes a fundamental principle of elegant design. The models strive not to add complexity through exhaustive rules, but to remove inconsistencies by learning underlying constraints. This aligns with the notion that a truly successful system requires minimal explicit instruction. As Tim Bern-Lee once stated, “The Web is more a social creation than a technical one,” highlighting the importance of implicit understanding and shared context – a principle mirrored in the models’ ability to generate coherent knowledge graphs from data, rather than relying on rigidly defined schemas. The power lies in what’s not needed to be said.
Further Shores
The presented work, while demonstrating efficacy in knowledge graph generation, illuminates a persistent tension. Semantic validity, achieved through learned constraints, is not inherent truth, but statistical mimicry. Future iterations must confront the fragility of these learned structures, their susceptibility to distributional shift, and the inherent ambiguity embedded within even the most meticulously curated datasets. The models perform well, but performance is a local maximum, not a global solution.
A reduction in architectural complexity is not merely desirable, but necessary. Current reliance on expansive parameter spaces – a common indulgence – obscures fundamental principles. The field would benefit from a deliberate parsimony, a focus on identifying the minimal sufficient structure for representing and generating knowledge. Unnecessary is violence against attention; the pursuit of scale, without concomitant gains in interpretability, is a dissipation of effort.
Ultimately, the true measure of success will not be the generation of more knowledge, but the generation of useful knowledge. This necessitates a shift in evaluation metrics, away from purely structural assessments and towards measures of practical utility – the capacity to enhance reasoning, facilitate discovery, and resolve genuine informational deficits. Density of meaning is the new minimalism; the goal is not quantity, but precision.
Original article: https://arxiv.org/pdf/2602.06707.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Persona 5: The Phantom X Relativity’s Labyrinth – All coin locations and puzzle solutions
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Unlock Stellar Blade’s Secret Dev Room & Ocean String Outfit
- Brent Oil Forecast
- ‘Super Mario Galaxy’ Trailer Launches: Chris Pratt, Jack Black, Anya Taylor-Joy, Charlie Day Return for 2026 Sequel
2026-02-10 06:06