Author: Denis Avetisyan
Researchers have developed a new framework, AssetFormer, that uses the power of autoregressive transformers to create customizable 3D models from text prompts.
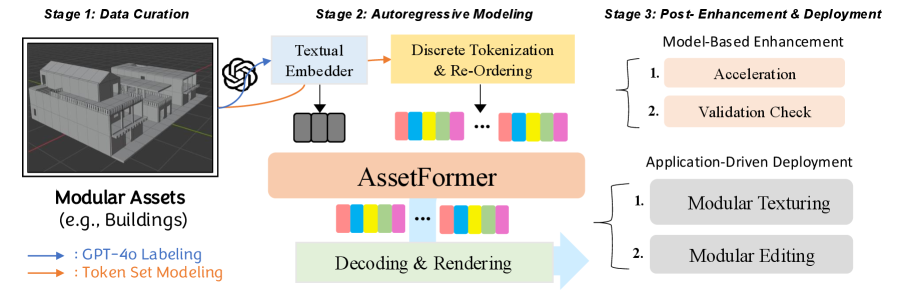
AssetFormer introduces a novel approach to modular 3D asset generation, enabling efficient and diverse content creation for applications like game development and virtual environments.
The demand for diverse and customizable 3D assets often clashes with the efficiency of traditional content creation pipelines. To address this, we introduce AssetFormer: Modular 3D Assets Generation with Autoregressive Transformer, a novel framework leveraging Transformer networks to generate modular 3D assets directly from textual descriptions. Our approach uniquely adapts autoregressive modeling-commonly used in language processing-to the creation of constrained, primitive-based 3D components, enabling a streamlined and flexible asset creation process. Could this methodology unlock new levels of procedural content generation and accelerate development across fields like game design and virtual reality?
Unveiling Patterns: Beyond Traditional 3D Representation
Historically, crafting detailed 3D environments has been constrained by the limitations of both voxel and mesh-based representations. Voxels, while offering simplicity, quickly become computationally expensive as resolution increases, leading to massive data storage requirements and hindering the creation of truly expansive scenes. Mesh-based models, though more efficient, struggle with complexity – detailed objects require millions of polygons, pushing the limits of real-time rendering and making editing a laborious process. This inherent difficulty in scaling both approaches has traditionally forced artists to compromise on detail or rely on increasingly powerful hardware, ultimately impeding the creative process and restricting the scope of possible virtual worlds. The challenges associated with managing this geometric complexity demonstrate the need for alternative approaches to 3D content creation.
While Neural Fields have emerged as a compelling alternative to traditional 3D representations, offering continuous scene descriptions and impressive rendering quality, a significant limitation lies in their inherent lack of discrete composability. Unlike assets built from distinct, editable parts, Neural Fields represent scenes as a single, continuous function; this makes targeted editing – such as swapping a chair for a sofa, or altering the texture of a specific object – remarkably difficult. Deconstructing a Neural Field to isolate and modify individual elements requires complex optimization processes, negating the efficiency gains initially offered by the continuous representation. This contrasts sharply with modular asset pipelines, where components can be readily reused, modified, and reassembled, fostering rapid iteration and scalability in content creation. Consequently, despite their strengths in rendering realism, Neural Fields currently pose challenges for workflows demanding precise control and efficient asset management.
The limitations of traditional 3D modeling techniques are increasingly addressed through the concept of modular assets. Rather than constructing scenes from monolithic meshes or dense voxels, this approach decomposes environments into a library of pre-built, reusable components – a wall segment, a window frame, a specific type of tree, for example. This decomposition offers significant advantages in content creation pipelines; designers can assemble complex scenes with relative ease, simply by instancing and arranging these modular elements. Beyond speed, modularity fosters consistency across projects and simplifies iterative design, as changes to a single asset automatically propagate throughout all instances. Furthermore, this paradigm lends itself well to procedural generation and data-driven content creation, promising a future where 3D worlds can be built and adapted with unprecedented efficiency and scalability.

Asset Synthesis: A Transformer-Based Generation Framework
AssetFormer utilizes a Transformer architecture to generate 3D assets in a modular fashion. This framework departs from traditional 3D generation methods by treating asset creation as a sequence prediction problem, where individual components, or modules, are predicted and assembled sequentially. The core of the system is a Transformer network trained to model the distribution of these modular components, enabling the generation of diverse and complex 3D assets. This approach allows for greater control over the generation process and facilitates the creation of coherent scenes through the predictable arrangement of individual modules, differing from methods that generate complete assets in a single step.
AssetFormer utilizes autoregressive modeling to generate 3D assets by predicting the sequence of modular components. This approach treats the creation of each component as a conditional probability distribution dependent on previously generated elements, effectively modeling the dependencies between parts. By sequentially predicting and assembling these components, the framework constructs a coherent scene, ensuring structural and semantic consistency. The autoregressive process allows for the generation of complex assets by building upon a foundation of simpler, previously generated modules, and facilitates control over the scene’s composition through manipulation of the predicted sequence.
Token Reordering and SlowFast Decoding are implemented within AssetFormer to address the computational demands of autoregressive 3D asset generation. Token Reordering restructures the sequence of generated tokens, enabling parallel processing and reducing sequential dependencies during decoding. SlowFast Decoding utilizes two parallel decoders – a slow decoder for high-resolution details and a fast decoder for coarse structure – which operate at different rates and resolutions. This approach reduces the overall decoding steps and computational cost while maintaining output quality, resulting in a reported 25% increase in decoding speed compared to standard autoregressive methods.
Classifier-Free Guidance improves the quality and controllability of generated 3D assets by modulating the generation process based on conditional information without requiring a separate classifier network. This technique involves training a single diffusion model conditioned on both the input data and a null condition – effectively training the model to predict outputs both with and without guidance. During inference, the unconditional output is subtracted from the conditional output, scaling the difference by a guidance scale factor. Increasing this factor strengthens the adherence to the conditioning signal, resulting in higher fidelity and better alignment with desired attributes, while decreasing the factor relaxes the constraint and increases diversity in the generated assets.
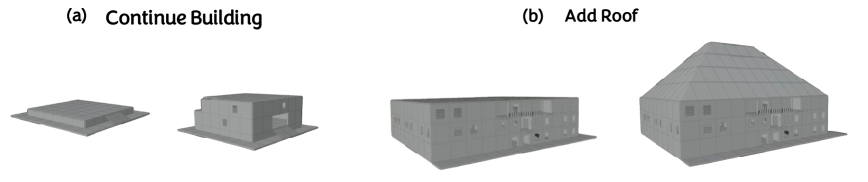
Data-Driven Synthesis: Scaling Asset Generation
The performance of AssetFormer, a model for 3D asset generation, is directly correlated with the quality of its training dataset. A high-quality dataset necessitates a substantial volume of geometrically accurate and texturally detailed 3D assets, alongside precise and comprehensive metadata describing each asset’s characteristics. Insufficient data, or data containing inaccuracies or inconsistencies, will negatively impact the model’s ability to learn the underlying distribution of 3D shapes and textures, resulting in generated assets with reduced realism and fidelity. Datasets must also represent a broad range of asset categories and variations to enable the model to generalize effectively and produce diverse outputs.
Data augmentation techniques are integral to the training process, artificially increasing the size and diversity of the 3D asset dataset. These techniques involve applying transformations to existing assets – including rotations, scaling, translations, and the addition of noise – to create modified versions. This process improves the model’s ability to generalize to unseen data and enhances its robustness against variations in input. Specifically, augmenting the dataset mitigates overfitting, allowing the model to learn more effectively from the available data and produce more reliable results across a wider range of asset types and conditions.
Procedural Content Generation (PCG) serves as a valuable supplement to real-world datasets for training 3D asset generation models by providing a virtually unlimited supply of diverse training examples. Unlike captured data, PCG allows for the systematic creation of assets with controlled variations in shape, texture, and material properties. This is particularly useful for scenarios where acquiring a sufficiently large and varied real-world dataset is impractical or costly. The generated data can augment existing datasets, improving the model’s generalization capabilities and reducing reliance on potentially biased or limited real-world examples. Combining PCG-derived data with real-world assets has demonstrated an FID score of 55.186, indicating improved realism and quality in the generated outputs.
LongLoRa, a parameter-efficient fine-tuning technique, was implemented to adapt large language models for 3D asset generation within constrained computational environments. This approach minimizes the number of trainable parameters, significantly reducing memory requirements and enabling effective training with limited resources. When utilizing a combined dataset of procedurally generated and real-world 3D assets, the resulting models achieved a Fréchet Inception Distance (FID) score of 55.186, indicating a substantial level of realism and quality in the generated outputs despite the resource limitations.
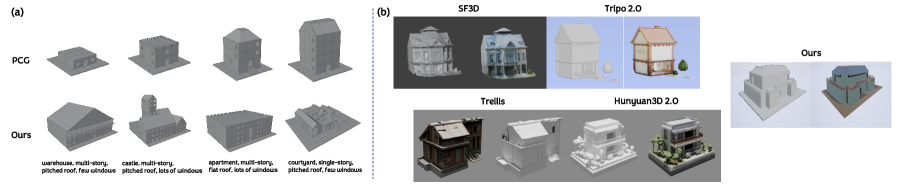
Revealing New Possibilities: Implications and Future Directions
The AssetFormer framework represents a significant advancement in 3D content creation by moving beyond the constraints of conventional techniques, such as mesh-based modeling or volumetric representations. Traditional methods often struggle with generating high-quality, detailed scenes efficiently, requiring extensive manual labor and specialized expertise. AssetFormer, however, leverages a novel approach to directly generate and assemble 3D assets, enabling the creation of complex environments with a level of detail previously unattainable. This is achieved through a transformer-based architecture that learns relationships between different asset components, allowing for the automatic generation of diverse and coherent scenes. Consequently, the framework not only streamlines the content creation pipeline but also unlocks the potential for generating entirely new and imaginative virtual worlds with greater ease and realism.
The AssetFormer framework promises to reshape workflows across multiple creative industries. In game development, it offers the potential to drastically reduce the time and resources required to build detailed and varied game worlds, moving beyond reliance on pre-made assets or lengthy manual creation processes. Virtual reality experiences stand to gain significantly from the ability to generate immersive and dynamic environments on demand, enhancing presence and interactivity. Beyond entertainment, digital content creation-spanning areas like advertising, architectural visualization, and film-can benefit from a tool capable of rapidly prototyping and refining 3D scenes, facilitating faster iteration and greater artistic freedom. The capacity to synthesize complex assets opens doors to personalized content and democratized creation tools, empowering a wider range of users to realize their visions in three dimensions.
Ongoing development of the AssetFormer framework prioritizes enhanced scalability and user control, aiming to facilitate the creation of even more expansive and intricate 3D environments. Researchers are actively investigating novel asset assembly techniques, moving beyond simple combination to intelligent arrangement and contextual adaptation. Simultaneously, new editing tools are being designed to give users finer-grained control over generated assets, allowing for precise modifications and customizations without compromising the underlying structural integrity. These advancements will not only broaden the scope of scenes that can be realistically rendered but also empower artists and designers with intuitive tools for creative expression, ultimately pushing the boundaries of what’s possible in virtual world-building.
Continued research prioritizes enhancing the variety and fidelity of assets produced by the framework. Qualitative user studies have already demonstrated promising results, with participants consistently scoring generated content highly in terms of its diversity, aesthetic appeal, and overall complexity. This positive feedback underscores the potential for further refinement, with ongoing efforts focused on incorporating more nuanced details and a wider range of stylistic variations. The goal is to move beyond simply creating plausible objects and environments toward generating assets that are indistinguishable from those created by skilled human artists, thereby unlocking even greater creative possibilities for users in fields like game development and virtual world design.
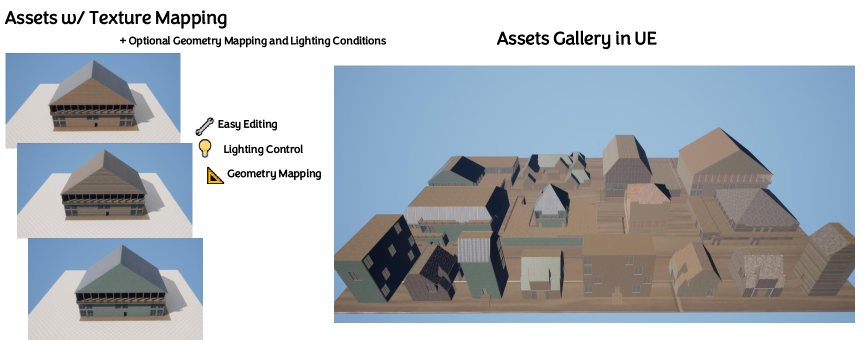
The development of AssetFormer underscores a fundamental principle in generative modeling: the power of sequential pattern recognition. This research builds upon the established strength of Transformer networks in language processing, adapting the autoregressive approach to the complexities of 3D asset creation. As Andrew Ng aptly stated, “AI is the new electricity.” This holds true for AssetFormer, as it offers a potentially transformative force in content creation pipelines. By decomposing asset generation into modular components and learning their sequential dependencies, the framework allows for a level of customization and control previously unattainable, demonstrating how understanding underlying structures-akin to discerning patterns-unlocks new possibilities in procedural content generation.
What Lies Ahead?
The AssetFormer model, viewed as a microscope focused on the latent space of 3D assets, reveals the inherent modularity within digital creation. However, the specimen – the complete realization of compelling, contextually appropriate content – remains partially obscured. While the autoregressive approach demonstrates a promising capacity for customization, the true test lies in scaling this control. Current limitations in maintaining global coherence across complex assemblies suggest future work must address the propagation of stylistic and semantic information throughout the generative process. The challenge isn’t simply generating parts, but orchestrating them into a believable whole.
A natural progression involves exploring the interplay between textual prompts and higher-level design directives. The model currently interprets language as a blueprint for component creation; future iterations could interpret it as a set of artistic constraints, guiding the overall aesthetic and narrative. This demands a more nuanced understanding of how human designers leverage abstraction and iteration-a shift from merely producing assets to composing experiences.
Ultimately, the success of this line of inquiry hinges on recognizing that generative models aren’t simply tools for automation. They are, instead, mirrors reflecting the complexity of creative thought itself. The unresolved questions aren’t merely technical hurdles, but fundamental inquiries into the nature of design, and the patterns that give form to our digital worlds.
Original article: https://arxiv.org/pdf/2602.12100.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-02-15 08:46