Author: Denis Avetisyan
A new framework automatically generates training data and environments, enabling language models to master complex, multi-step tasks through self-play.

ASTRA leverages scalable data synthesis and verifiable reinforcement learning to achieve state-of-the-art performance on agentic benchmarks.
Despite advances in large language models, training robust, tool-using agents for complex decision-making remains a significant challenge due to reliance on manual intervention, simulated environments, and limitations in long-horizon learning. To address these issues, we introduce ASTRA-Automated Synthesis of agentic Trajectories and Reinforcement Arenas-a fully automated framework leveraging scalable data synthesis and verifiable reinforcement learning to train tool-augmented language model agents. This approach generates diverse trajectories based on tool-call graphs and converts decomposed reasoning into executable, rule-verifiable environments, achieving state-of-the-art performance on agentic benchmarks while approaching the capabilities of closed-source systems. Will this automated pipeline unlock new levels of adaptability and efficiency in the development of intelligent agents?
Beyond Pattern Matching: The Pursuit of Semantic Grounding
Contemporary language models, despite their impressive abilities in generating human-quality text, often falter when faced with reasoning tasks that demand more than simple pattern matching. These models typically struggle with problems requiring sequential inference or the integration of multiple pieces of information, revealing a limitation in their capacity for multi-step interaction. Unlike human cognition, which leverages contextual understanding and iterative verification, current architectures frequently operate as “black boxes,” processing input and producing output without a transparent reasoning process. This deficiency becomes particularly apparent in scenarios demanding nuanced judgment, hypothetical reasoning, or the ability to identify inconsistencies – areas where humans readily employ a structured, step-by-step approach to arrive at a solution. Consequently, even seemingly simple reasoning challenges can expose the fragility of these models, highlighting the need for advancements beyond mere statistical language proficiency.
Current language models often falter when faced with reasoning tasks demanding more than a simple response, largely because they operate without a dedicated space to systematically ground and validate their thought processes. Unlike human cognition, which leverages a rich internal and external environment for verification, these models process information in a relatively unstructured manner. This absence of a ‘reasoning environment’ leads to errors in multi-step problems, as there’s no mechanism to confirm intermediate conclusions or correct flawed logic. The inability to establish and utilize such a structured space represents a fundamental limitation, hindering the development of truly robust and reliable artificial intelligence capable of complex problem-solving and insightful deduction.
The architecture of human thought isn’t simply a linear progression of ideas, but a richly connected semantic topology – a landscape of concepts and relationships where meaning emerges from the connections themselves. Understanding and replicating this structure is increasingly recognized as vital for developing artificial intelligence capable of robust reasoning. Current AI often falters not because of a lack of data, but because it lacks the ability to navigate this conceptual space, to verify assumptions against an internal model of how things connect. Building agents that can effectively map, explore, and reason within a semantic topology promises a shift from brittle, pattern-matching systems to more flexible and adaptable intelligences, capable of handling ambiguity, drawing inferences, and exhibiting genuinely insightful problem-solving abilities.
A novel framework centers on constructing verifiable environments directly from question-answer pairs, offering a pathway to enhanced reasoning capabilities in artificial intelligence. This approach moves beyond simply assessing the correctness of an answer; it focuses on building a simulated ‘world’ where the logic connecting the question and answer can be explicitly tested and validated. By representing knowledge as a network of interconnected assertions derived from these pairs, the system can trace the reasoning process, identify potential inconsistencies, and ultimately, confirm the validity of its conclusions. This method allows for a dynamic and adaptable environment, enabling the agent to not only solve problems but also to justify how it arrived at the solution, fostering greater trust and reliability in complex reasoning tasks. The system’s ability to ground reasoning in a verifiable context promises significant advancements in areas demanding robust and explainable AI, such as scientific discovery and decision-making.
Supervised Adaptation: Establishing a Baseline for Tool Interaction
Supervised Fine-Tuning (SFT) serves as an initial training phase where the model learns to interact with tools by observing example conversations. This process involves presenting the model with a dataset of input prompts and corresponding tool interactions, allowing it to learn the correct sequence of actions required to fulfill user requests. The objective of SFT is to establish a baseline level of competency in tool usage, enabling the model to generate syntactically correct tool calls and interpret their outputs. By learning from labeled data, the model acquires a foundational understanding of tool functionalities before engaging in more complex, reward-based learning.
Supervised Fine-Tuning (SFT) necessitates comprehensive ‘Tool Documents’ which serve as the primary source of truth for defining the behavior and parameters of each tool. These documents detail the tool’s purpose, input requirements – including data types, acceptable ranges, and required formatting – and the expected output format. Critically, Tool Documents specify all possible error conditions and corresponding error messages, enabling the model to learn robust handling of invalid inputs or tool failures. The level of detail within these documents directly impacts the model’s ability to accurately interpret user requests and generate valid tool calls during the SFT phase; incomplete or ambiguous specifications lead to suboptimal performance and necessitate iterative refinement of both the documentation and the model.
Multi-turn conversation samples are generated through a process called Trajectory Synthesis, which constructs conversational paths based on predefined tool interactions. This synthesis relies on a static Tool-Call Graph, representing the permissible sequence and dependencies of tool calls within a given task. The graph dictates which tools can be called after another, ensuring logical and valid interactions. By traversing this graph, the system generates conversations where each turn involves either a user utterance or a tool call, creating a dataset of multi-turn dialogues that demonstrate correct tool usage sequences. The resulting trajectories serve as training data for subsequent model learning phases.
The initial supervised adaptation process, involving SFT and trajectory synthesis, provides a crucial starting point for reinforcement learning (RL) by pre-training the model with a distribution of successful tool interactions. This pre-training mitigates the exploration challenges inherent in RL, specifically reducing the time required for the agent to discover effective tool usage policies. By initializing the agent with a strong understanding of tool functionalities and valid interaction sequences, the subsequent RL phase can focus on optimizing for more complex goals and refining nuanced strategies, rather than learning basic tool operation from scratch. This approach significantly improves sample efficiency and accelerates the learning process within the RL framework.
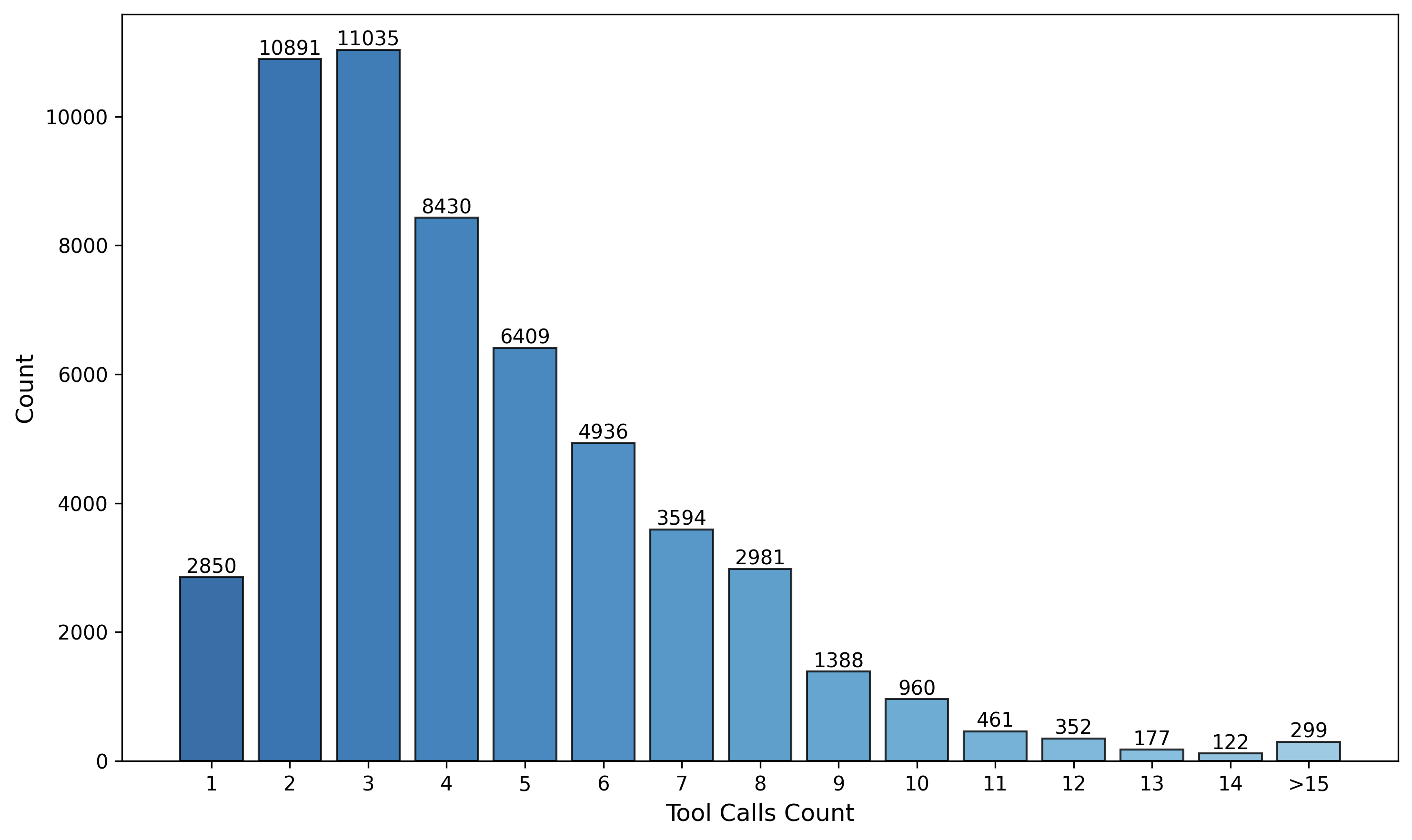
Reinforcement Learning: Refining Policy Through Iterative Interaction
Reinforcement Learning (RL) is utilized to iteratively improve the agent’s decision-making process, referred to as its policy, within a simulated environment. This process involves the agent performing actions within the environment and receiving scalar reward signals based on those actions. The agent then adjusts its policy to maximize cumulative reward over time. Specifically, the synthesized environment provides a consistent and controllable setting for the agent to learn through trial and error, allowing for systematic evaluation and refinement of its tool use capabilities without requiring real-world interaction. The learned policy dictates which tool, if any, the agent selects at each step of a multi-turn conversation, and is optimized through repeated interactions and reward feedback.
The Generalized Reward-Policy Optimization (GRPO) objective functions as the core optimization signal during reinforcement learning. It aims to maximize the cumulative reward received by the agent across entire multi-turn conversational interactions, rather than optimizing for individual turns. This is achieved by summing the rewards obtained at each step of a conversation, effectively encouraging policies that lead to higher overall success and efficiency in task completion. The GRPO objective is implemented as a summation: \sum_{t=1}^{T} r_t , where r_t represents the reward at time step t and T is the length of the conversation. This cumulative reward approach is critical for learning complex behaviors requiring strategic planning over extended interactions.
The F1-style reward function is designed to evaluate agent performance based on both successful task completion and the efficiency of the interaction required to achieve it. This function assigns a reward based on a weighted sum of task completion – whether the agent correctly fulfills the user’s request – and a measure of interaction cost, specifically the number of API calls made. By jointly optimizing these two factors, the reward function incentivizes the agent to not only solve the task, but to do so using the fewest possible interactions, promoting concise and effective tool use. The specific weighting between task completion and interaction cost is a hyperparameter tuned to balance accuracy and efficiency.
Irrelevant Tool Mixing is implemented during reinforcement learning to improve the agent’s ability to generalize to novel situations. This technique involves presenting the agent with a set of tools during each training episode, where a portion of these tools are functionally useless for the current task. By requiring the agent to actively discriminate between relevant and irrelevant tools before selecting an action, the learning process is forced to prioritize identifying truly useful tools rather than relying on spurious correlations between tool availability and task success. This approach enhances robustness to variations in the toolset and promotes a more discerning policy for tool selection, ultimately improving performance in unseen environments.
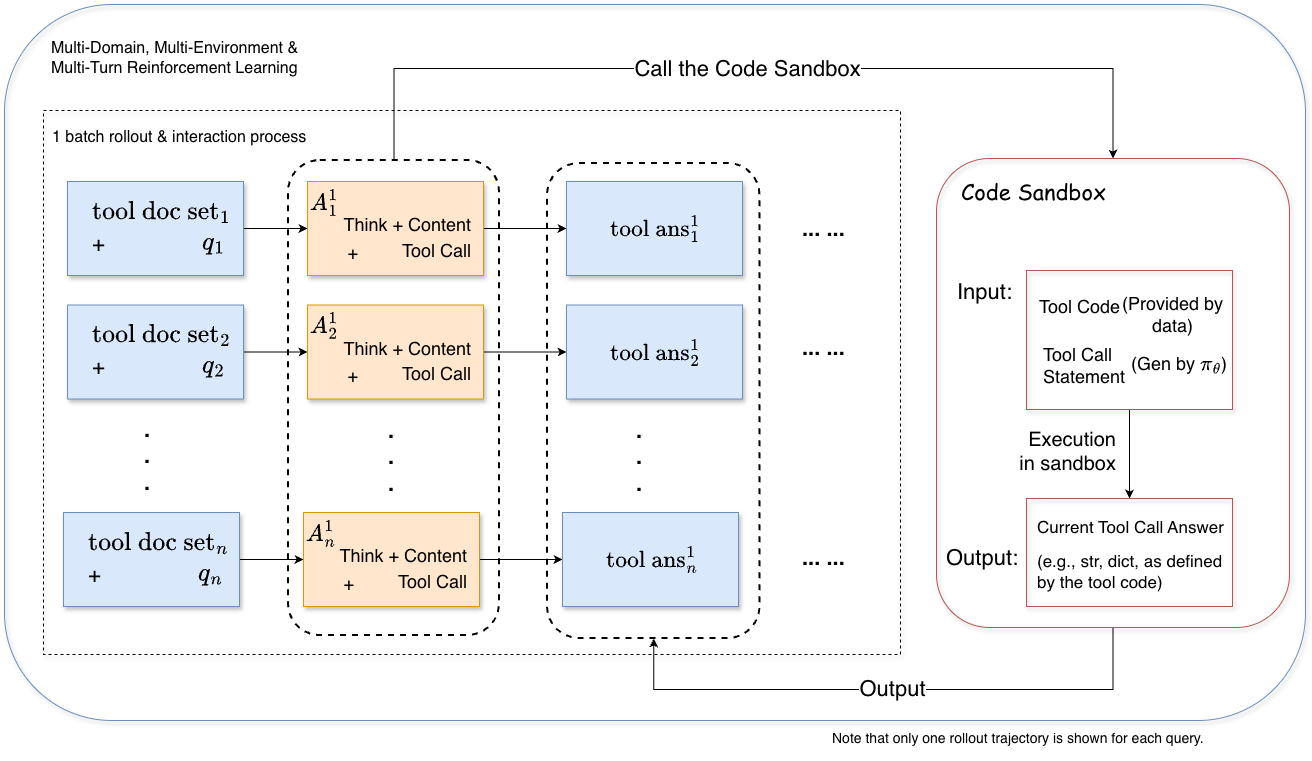
Scalable Synthesis and Online Learning: A Cycle of Continuous Improvement
Maintaining a consistent flow of useful information is crucial for efficient machine learning, and ‘Adaptive Batch Filling’ addresses this challenge directly. This technique dynamically adjusts the data selection process during training, prioritizing the most informative examples to ensure each batch is fully utilized. Rather than relying on randomly sampled data, the system assesses the potential impact of each example on the learning process, effectively ‘filling’ the batch with data that will yield the greatest improvement in performance. This intelligent approach not only maximizes training efficiency but also accelerates convergence, allowing the system to learn more effectively from a given dataset and achieve stronger results in complex tasks.
ASTRA represents a fully automated framework designed to push the boundaries of reinforcement learning through a synergistic combination of scalable data synthesis and verifiable online learning. This system dynamically generates training data, allowing it to adapt and improve without relying on pre-defined datasets. Crucially, ASTRA doesn’t simply learn from this data, but also verifies its own learning process, ensuring robustness and reliability. The result is state-of-the-art performance across a range of agentic tool-use benchmarks, demonstrating a significant leap in the ability of artificial intelligence to effectively utilize tools and solve complex problems in dynamic environments. This automated approach not only accelerates the learning process but also establishes a new paradigm for building intelligent agents capable of continuous self-improvement.
The creation of robust learning environments is significantly enhanced through a process called ‘QA Pair Decomposition’. This technique breaks down complex user queries into smaller, more manageable question-answer pairs, effectively expanding the diversity and granularity of training data. Rather than presenting an agent with a single, multifaceted task, decomposition allows it to learn from a series of focused interactions, each addressing a specific component of the original query. This granular approach not only simplifies the learning process but also fosters a deeper understanding of underlying concepts, enabling the agent to generalize more effectively to novel situations and complex reasoning challenges. The resulting rich dataset provides a more comprehensive and nuanced foundation for training, ultimately leading to improved performance in agentic tool-use benchmarks.
The automated framework, ASTRA, achieves performance levels approaching those of proprietary, closed-source systems when evaluated on challenging agentic tool-use benchmarks including BFCL-MT, τ2-Bench, and ACEBench. This represents a substantial advancement in complex reasoning capabilities for open-source artificial intelligence. Rigorous testing demonstrates that ASTRA not only matches but, in several instances, surpasses the performance of established systems on tasks demanding multi-step reasoning, planning, and tool utilization. These improvements are particularly notable in benchmarks designed to assess an agent’s ability to navigate intricate scenarios and achieve complex goals, suggesting ASTRA’s potential for broader application in areas requiring sophisticated cognitive abilities.
The pursuit of robust agentic systems, as demonstrated by ASTRA, benefits greatly from a commitment to foundational principles. It echoes Carl Friedrich Gauss’s sentiment: “If I have seen further it is by standing on the shoulders of giants.” ASTRA doesn’t attempt to reinvent the landscape of reinforcement learning, but rather leverages existing tools and methodologies-the ‘giants’-to construct a more effective framework. The system’s data synthesis component exemplifies this; it doesn’t merely generate data, it verifies it, streamlining the process and focusing computational resources on truly valuable interactions. This disciplined approach, prioritizing clarity over complexity, aligns perfectly with a philosophy where elegance stems from rigorous reduction.
What’s Next?
The presented framework, while demonstrably effective, clarifies rather than dissolves the central difficulty: scalability of trust. ASTRA synthesizes environments and interactions, a necessary but insufficient condition for genuine agency. The benchmarks it surpasses are, by necessity, abstractions. Future work must grapple with the inherent messiness of real-world interaction – the ambiguity, the incomplete information, the adversarial inputs not conveniently generated by a training pipeline. The pursuit of verifiable environments should not become an end in itself, a retreat into controllable complexity.
A critical limitation resides in the assumption of a static ‘tool’ set. The world does not offer a fixed API. The ability to dynamically discover, integrate, and even create tools represents a significant, currently unaddressed challenge. This necessitates a shift from reinforcement learning to reinforcement adaptation – systems capable of evolving their own instrumental repertoire. Unnecessary is violence against attention; focusing solely on optimizing within predefined constraints delays the inevitable expansion of the problem space.
Ultimately, the value of such systems will not be measured by benchmark scores, but by their capacity to tolerate – and even benefit from – irreducible uncertainty. Density of meaning is the new minimalism. The pursuit of perfect simulation is a distraction. The true test lies in deployment, in the messy, unpredictable crucible of the real world.
Original article: https://arxiv.org/pdf/2601.21558.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Silver Rate Forecast
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading Smarter: AI-Powered Execution Schedules
2026-01-31 08:39