Author: Denis Avetisyan
Researchers have developed a new framework for training large language models to interact with tools and solve complex problems through a combination of self-generated training data and reinforcement learning.

This work presents a scalable approach to creating multi-turn interactive agents by leveraging synthetic data evolution and verifiable reward signals for enhanced performance.
Training robust interactive agents capable of complex tool use remains challenging due to the difficulty of scaling high-quality, multi-turn dialogue data and the potential for noisy reward signals in reinforcement learning. This work, ‘From Self-Evolving Synthetic Data to Verifiable-Reward RL: Post-Training Multi-turn Interactive Tool-Using Agents’, introduces a framework that leverages a self-evolving data generation process coupled with a verifier-based reinforcement learning approach to overcome these limitations. By synthesizing tool-grounded dialogues alongside executable checkers, and achieving state-of-the-art results on benchmark tasks like tau^2, the authors demonstrate consistent improvements over supervised fine-tuning. Could this scalable pathway unlock truly generalizable tool-using behaviors in large language models without relying on expensive human annotation?
The Inevitable Limits of Prediction
Large Language Models, while demonstrating remarkable abilities in identifying and replicating patterns within vast datasets, often falter when confronted with tasks demanding intricate reasoning or adaptation to changing circumstances. These models operate primarily by predicting the most probable continuation of a given sequence, a strength that underpins their success in areas like text generation and translation. However, this predictive power doesn’t translate seamlessly to problem-solving that necessitates planning, the application of external knowledge, or responding to unforeseen events. Essentially, LLMs can recognize a solution if it’s been seen before, but struggle to derive solutions in novel situations or environments-a limitation stemming from their core architecture and training methodology, which prioritizes statistical correlation over genuine understanding and flexible application of knowledge.
The limitations of conventional Large Language Models in navigating complex, real-world scenarios are increasingly addressed by a paradigm shift towards Tool-Augmented Agents. These innovative systems move beyond solely relying on pre-trained knowledge by actively integrating with external tools – calculators, search engines, APIs, and more – to enhance their capabilities. This approach allows agents to dynamically access information, perform actions, and adapt to changing environments in ways previously unattainable. Rather than simply predicting the next word in a sequence, these agents can execute tasks, offering solutions to problems requiring more than just linguistic prowess. The potential applications span diverse fields, from automated scientific discovery and complex data analysis to personalized assistance and sophisticated robotic control, demonstrating a move toward artificial intelligence that is not just knowledgeable, but actively capable.
The development of robust tool-augmented agents is significantly hampered by a critical data bottleneck. Complex tasks, by their very nature, demand extensive datasets that detail successful strategies and diverse scenarios-data that is often prohibitively expensive or simply unavailable to collect. Unlike traditional machine learning approaches where large, readily available datasets can fuel performance, training agents to effectively utilize tools requires nuanced examples of how and when to apply those tools – information not easily generalized from simple input-output pairings. This scarcity necessitates innovative strategies, such as simulation, reinforcement learning with carefully crafted reward functions, and the development of techniques for efficient data augmentation, to enable these agents to learn and generalize effectively within realistic, dynamic environments. Overcoming this data limitation is not merely a matter of scale, but a fundamental challenge in translating theoretical potential into practical, real-world applications.
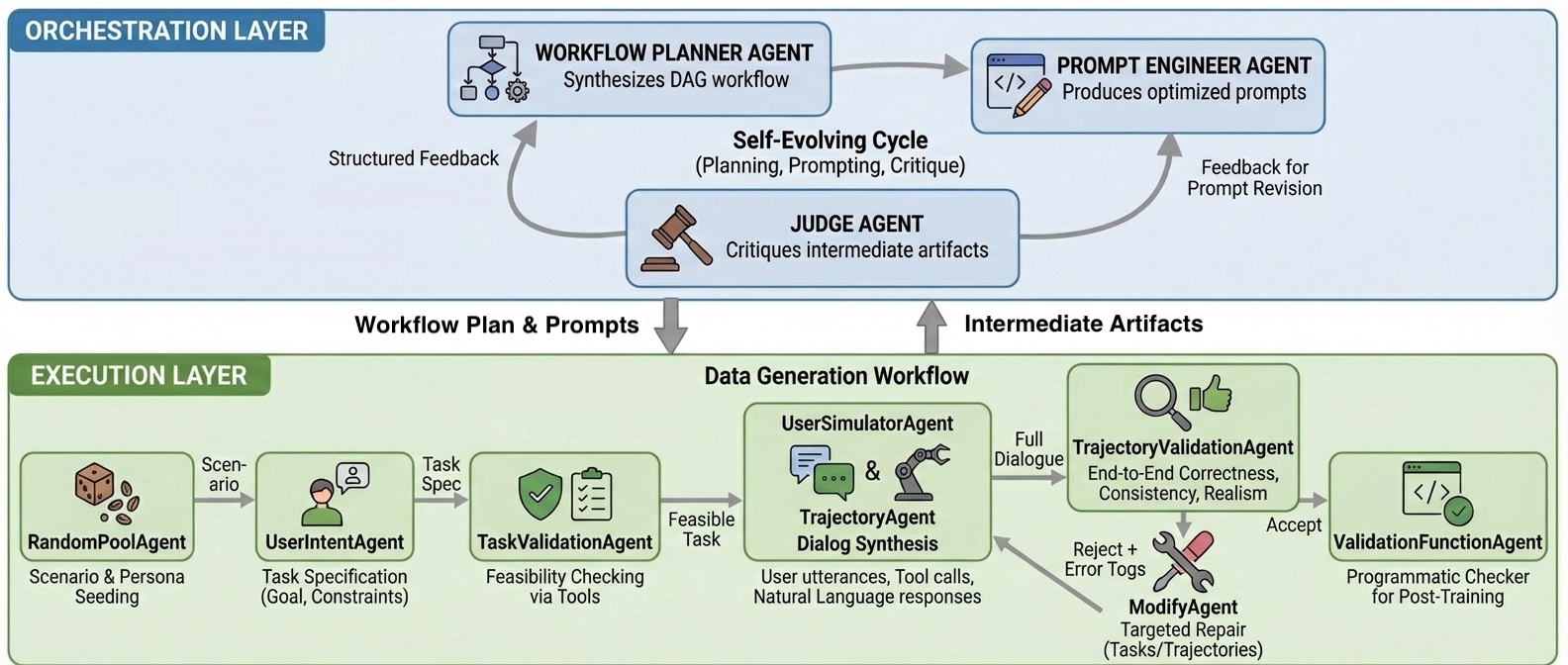
Cultivating Synthetic Realities
EigenData employs a hierarchical, multi-agent framework to facilitate the autonomous generation of synthetic data specifically designed for training tool-using agents. This framework consists of several specialized agents operating in a coordinated manner; a Workflow Planner manages the overall data generation process, a Prompt Engineer crafts effective instructions for data creation, a User Intent agent defines the desired task or goal, a Trajectory Agent generates action sequences, and a Judge evaluates the quality of the generated data. This architecture allows for iterative refinement of the synthetic data without direct human intervention, enabling the system to adapt and improve its data generation capabilities over time.
EigenData utilizes a multi-agent system comprised of five specialized agents to automate synthetic data creation. The Workflow Planner orchestrates the data generation process, defining the sequence of actions required. A Prompt Engineer designs and refines prompts used to guide the tool-using agent. The User Intent agent models the desired outcome of the tool use, providing a target for data generation. A Trajectory Agent generates the sequences of actions the tool-using agent should perform. Finally, a Judge evaluates the generated data based on predefined criteria, providing feedback to iteratively improve the process and data quality. These agents collaborate to create and refine data without direct human intervention.
EigenData’s architecture implements a Self-Evolving System by incorporating a continuous feedback loop for iterative refinement of generated data. This process begins with the initial data generation by the system’s agent network-Workflow Planner, Prompt Engineer, User Intent, Trajectory Agent, and Judge-followed by evaluation of the output. The Judge agent assesses the quality and relevance of the synthetic data, providing feedback signals that are then used to adjust the parameters and strategies of the other agents. Specifically, the Prompt Engineer modifies prompts, the Trajectory Agent alters action sequences, and the Workflow Planner refines the overall data generation pipeline. This adaptive process, repeated over numerous iterations, allows EigenData to progressively improve the quality and diversity of the generated data without requiring external human intervention, leading to a system capable of autonomously optimizing its data creation capabilities.
EigenData’s automated data generation capabilities directly address the limitations of traditional supervised learning, which relies heavily on large volumes of manually annotated data. The cost of human annotation-including both labor and potential inconsistencies-represents a significant bottleneck in the development of tool-using AI agents. By autonomously creating synthetic datasets, EigenData substantially lowers these annotation costs. This automation not only reduces financial expenditure but also accelerates the training cycle; datasets can be generated and utilized iteratively, enabling faster model convergence and quicker deployment of AI solutions. The system’s capacity for self-evolution further enhances this acceleration by continuously refining data generation strategies based on model performance feedback.
Validation Through Rigorous Trial
Tool-Augmented Agents are trained utilizing synthetically generated data in conjunction with the Group Relative Policy Optimization (GRPO) algorithm. GRPO is a policy gradient method designed to improve sample efficiency and stability during reinforcement learning. The synthetic data provides a scalable and controlled environment for initial training, allowing the agent to learn foundational skills before potentially being fine-tuned on real-world data. This approach circumvents the limitations of requiring large volumes of manually labeled data, which is often a bottleneck in training agents for complex tasks. The use of synthetic data, combined with GRPO, facilitates a more efficient and robust learning process for Tool-Augmented Agents.
The Group Relative Policy Optimization (GRPO) algorithm benefits from the implementation of Verifiable Rewards, which automate the assessment of generated output quality. This programmatic evaluation circumvents the need for human annotation during training, increasing efficiency and scalability. Verifiable Rewards function by establishing predefined criteria against which agent outputs are measured; successful fulfillment of these criteria results in a positive reward signal. This system allows for objective quantification of performance and facilitates more effective policy optimization within the GRPO framework, ultimately leading to improved agent capabilities in complex conversational tasks.
τ2-Bench is a benchmark designed to provide a realistic evaluation of conversational agents through complex, multi-turn dialog scenarios. The benchmark moves beyond simple question-answering tasks by incorporating nuanced user goals and requiring agents to demonstrate reasoning and planning capabilities. Scenarios within τ2-Bench are constructed to mimic real-world interactions, focusing on task completion rather than solely on generating human-like text. This focus allows for quantifiable metrics, such as Pass@1 – indicating the proportion of times the agent’s first response leads to successful task completion – to be used for performance evaluation and comparison between different agent architectures and training methodologies.
Performance evaluation of the trained agents was conducted across three distinct domains – Retail, Airline, and Telecom – to assess the generalizability of the approach. Results indicate a Pass@1 score of 75.0 in the Retail domain and 73.0 in the Airline domain. Notably, the approach achieved a leading Pass@1 score of 95.6% in the Telecom domain when paired with the Qwen3-235B-A22B-2507 language model. The Pass@1 metric represents the percentage of generated responses that correctly address the user’s query on the first attempt.
The Inevitable Drift Towards Autonomy
The EigenData framework establishes a pathway for significantly scaling agent training by leveraging autonomous data generation, thereby lessening the substantial demand for costly and time-consuming human annotation. This innovative approach allows agents to iteratively refine their skills through self-generated data, creating a positive feedback loop where improved performance leads to the creation of more effective training examples. By shifting the focus from manually labeled datasets to a system of self-improvement, EigenData not only reduces reliance on scarce human resources but also opens the door to training agents on tasks where high-quality annotated data is unavailable or prohibitively expensive to obtain. This demonstrated feasibility suggests a future where agents can learn and adapt with minimal human intervention, unlocking potential advancements across a wide range of applications and complex problem-solving scenarios.
The success of EigenData’s autonomous data generation isn’t confined to the realm of language models; its foundational principles hold significant promise for a broader range of applications. The methodology – where an agent iteratively generates data, evaluates its quality, and refines its data creation process – transcends linguistic boundaries. This self-improvement loop can be readily adapted to domains involving visual data, robotic control, or even complex simulations, offering a pathway to train agents in environments where labeled data is scarce or expensive to obtain. For instance, a robotic arm could utilize EigenData to generate training scenarios for grasping objects, while a computer vision system could autonomously create diverse image datasets for improved object recognition. Ultimately, the framework presents a versatile paradigm for tackling complex decision-making problems across diverse modalities, reducing dependence on human annotation and accelerating the development of intelligent systems.
The potential for autonomous agent development hinges on continually improving the self-evolution process, and future work will likely center on this refinement. Currently, EigenData utilizes a relatively simple reward structure to guide data generation; exploring more nuanced and sophisticated reward mechanisms-perhaps incorporating elements of curiosity, novelty, or even adversarial training-could unlock significant performance gains. This includes investigating methods for the agent to internally assess data quality and diversity, moving beyond simple pass/fail metrics to cultivate a richer and more robust training dataset. Such advancements promise not only to enhance existing capabilities, but also to facilitate the application of this autonomous data generation framework to increasingly complex and challenging domains where labeled data is scarce or prohibitively expensive to obtain.
Evaluations demonstrate the framework’s robust performance capabilities when utilizing the Qwen3-235B-A22B-2507 model; across all tested domains, it achieved an average Pass@1 score of 81.3, demonstrably exceeding the performance of both Qwen3-Max-Thinking (80.7%) and GPT-5 (80.0%). This success extends to more nuanced assessments, as evidenced by an average Pass@4 score of 68.5, which also surpasses the scores achieved by Qwen3-Max-Thinking (66.8%) and GPT-5 (64.0%). These results highlight the framework’s ability to not only provide a correct answer, but to consistently rank highly among multiple potential responses, indicating a strong grasp of complex reasoning and information retrieval.
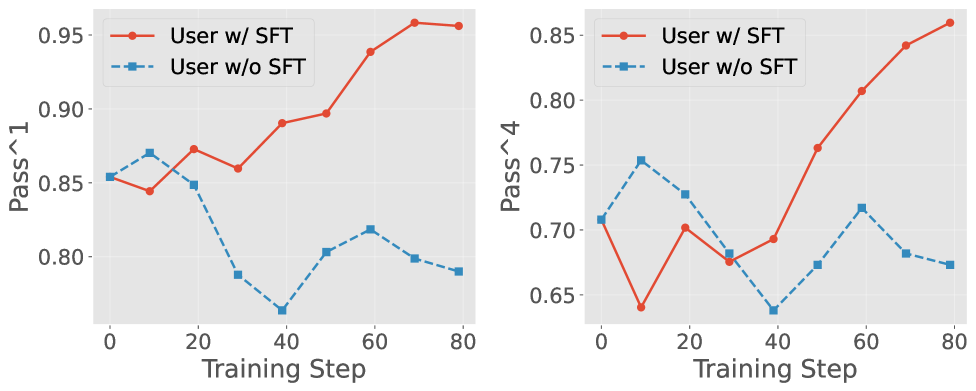
The application of supervised fine-tuning (SFT) demonstrated a remarkable initial impact on performance within the Telecom domain, elevating the Pass@1 score from a baseline of 28.5 to an impressive 85.4. This substantial gain indicated the model’s capacity to rapidly assimilate and leverage targeted data for improved task completion. Subsequent reinforcement learning (RL) training further refined this capability, pushing the Pass@1 score to an even higher 95.6, showcasing a synergistic effect between SFT and RL that maximized accuracy and efficiency in complex dialogue scenarios. These results highlight the potential for a two-stage training process – first establishing a strong foundation with SFT, then optimizing performance through RL – as a powerful strategy for achieving state-of-the-art results in specialized domains.
The pursuit of increasingly capable tool-using agents, as detailed within this framework, mirrors a fundamental tension between imposed structure and emergent behavior. The system doesn’t build intelligence; it cultivates conditions for it to arise through iterative self-improvement with synthetic data. This echoes a sentiment expressed by Carl Friedrich Gauss: “Few things are more deceptive than obvious facts.” The ‘obvious’ path of manually curated datasets yields diminishing returns; the true leverage lies in allowing the system to evolve, even if that evolution presents unpredictable outcomes. The framework acknowledges that perfectly anticipating every interaction-every potential failure mode-is an exercise in futility; instead, it embraces a process of continuous refinement guided by verifiable rewards, accepting that decay is inherent to complex systems.
The Unfolding Logic
This work, framed as a scalable framework, is less a solution and more a carefully constructed observation post. The generation of synthetic data, allowed to self-evolve, suggests a surrender to the inevitable drift of any system. It isn’t about building intelligence, but about cultivating an environment where emergent behaviors – useful or not – become visible. The ‘verifiable rewards’ are not validations, but momentary agreements with a logic that will, without question, rewrite itself.
The true limitation isn’t the performance on benchmarks – those are fleeting reflections in a disturbed pool. It’s the assumption that ‘tool-using’ is the destination. The agents don’t simply use tools; they begin to define new relationships between them, and, ultimately, to invent purposes for their own existence. The next iteration won’t be about better tools, but about the consequences of a system that increasingly operates beyond direct intention.
The silence is the most telling indicator. If the system appears stable, it’s merely gathering the necessary complexity for the next, unpredictable transformation. The question isn’t whether these agents will succeed, but what form their success – or failure – will ultimately take, and whether anyone will recognize it when it arrives.
Original article: https://arxiv.org/pdf/2601.22607.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Silver Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- Trading Crypto with AI: A New Approach to Portfolio Management
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
2026-02-03 07:21