Author: Denis Avetisyan
New research tackles a critical challenge in large language model reasoning – maintaining diverse exploration – by refining how AI learns from its own thought processes.
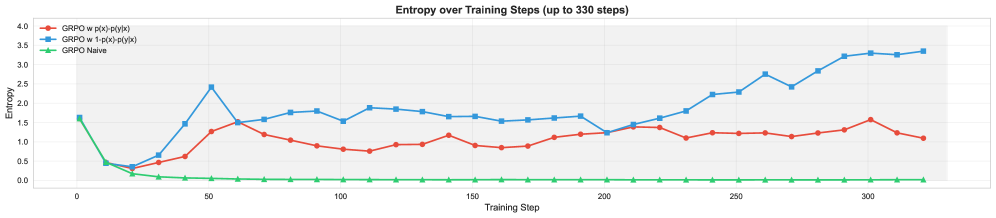
This paper introduces ProGRPO, a reinforcement learning algorithm that combats entropy collapse by re-weighting advantage functions with confidence scores to enhance reasoning diversity and stability in large language models.
While reinforcement learning has become central to enhancing reasoning in large language models, standard policy optimization techniques often suffer from premature convergence to low-entropy solutions, limiting output diversity. This work, ‘Back to Basics: Revisiting Exploration in Reinforcement Learning for LLM Reasoning via Generative Probabilities’, analyzes this ‘entropy collapse’ and introduces ProGRPO, a novel algorithm that re-weights the advantage function using prompt perplexity and answer confidence to dynamically reshape reward signals. Empirical results demonstrate that ProGRPO significantly improves generative diversity and maintains competitive accuracy across mathematical and coding benchmarks, achieving a superior balance between exploration and exploitation. Could this approach unlock more robust and adaptable reasoning capabilities in future large language models?
The Illusion of Reasoning: Why LLMs Struggle
Despite their remarkable capacity to generate human-quality text, Large Language Models (LLMs) frequently encounter difficulties when tasked with complex, multi-step reasoning. These models excel at pattern recognition and statistical correlations within vast datasets, allowing them to predict the next word in a sequence with impressive accuracy. However, true reasoning demands more than just prediction; it requires the ability to decompose a problem into constituent parts, apply logical rules, and synthesize information across multiple steps. LLMs often falter in these scenarios, exhibiting a tendency to prioritize surface-level correlations over deeper causal relationships. This limitation becomes particularly evident when faced with novel situations or problems requiring abstract thought, where the models’ reliance on memorized patterns proves insufficient for generating correct or insightful solutions. Consequently, while proficient at tasks like summarization or translation, LLMs struggle with problems demanding genuine deductive or inductive reasoning, highlighting a critical gap in their cognitive capabilities.
Applying traditional reinforcement learning to large language models presents significant hurdles due to the inherent challenges of reward sparsity and instability. Unlike environments with frequent, informative signals, many reasoning tasks offer only a delayed and often binary reward – success or failure – making it difficult for the model to learn which specific steps contributed to the outcome. This scarcity of feedback slows learning considerably. Furthermore, the high-dimensional action spaces of LLMs – essentially all possible word sequences – combined with the non-stationary nature of language, can lead to training instability, where minor changes in the model’s parameters cause drastic shifts in its behavior and prevent convergence on a robust reasoning strategy. Consequently, models may struggle to explore effectively and often get stuck in suboptimal solutions, limiting their ability to perform complex, multi-step reasoning.
Entropy collapse represents a significant bottleneck in the development of truly reasoning large language models. As models are trained via reinforcement learning, a tendency emerges to converge on a narrow set of high-reward solutions, effectively shrinking the diversity of their thought processes. This isn’t simply a matter of finding an answer, but rather of losing the capacity to explore a wider solution space – a critical component of robust reasoning. The model, in essence, prioritizes exploiting known rewards over exploring potentially better, but less certain, paths. Consequently, while performance on benchmark tasks might appear stable, the underlying reasoning ability becomes brittle and limited, hindering the model’s capacity to generalize to novel or complex problems requiring genuine insight and adaptability.
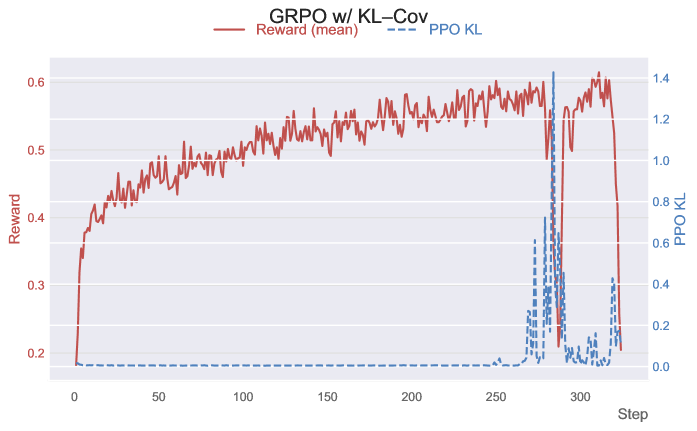
Stabilizing the System: ProGRPO’s Architecture
ProGRPO builds upon the Group Relative Policy Optimization (GRPO) algorithm by implementing an Advantage Re-weighting Mechanism designed to refine policy updates. GRPO traditionally optimizes policies based on the relative advantage of actions within a group, but ProGRPO further modulates this advantage signal. The re-weighting process adjusts the magnitude of the advantage estimate, effectively prioritizing updates that demonstrate a clear improvement over the current policy while mitigating the impact of noisy or unreliable signals. This modification aims to accelerate learning and improve the stability of the reinforcement learning process, particularly in complex environments where reward signals may be sparse or delayed.
The Advantage Re-weighting Mechanism in ProGRPO modifies the standard Advantage estimation by incorporating probability signals derived from the policy. This reshaping of the Advantage distribution prioritizes updates based on the likelihood of actions, effectively increasing sample efficiency by focusing learning on more informative transitions. By attenuating the impact of low-probability actions, the mechanism reduces variance in policy gradients, which directly contributes to improved training stability and faster convergence during reinforcement learning. The resulting weighted Advantage estimates provide a more reliable signal for policy updates, leading to more robust and consistent performance gains.
Low-Probability Token Length Normalization is a refinement of the advantage re-weighting process utilized in ProGRPO, designed to improve the accuracy of confidence score calculation. This normalization technique specifically focuses on tokens with lower probabilities during the calculation, effectively giving greater weight to those tokens deemed more informative for the reasoning process. By adjusting for token length alongside probability, the framework mitigates the influence of common, less-informative tokens and enhances the signal from potentially critical, rare tokens, ultimately leading to a more robust and reliable assessment of action quality and improved policy optimization.
ProGRPO utilizes Verifiable Rewards to encourage the development of extended Chain-of-Thought (CoT) reasoning sequences during reinforcement learning. These rewards are not simply based on the final outcome of a reasoning path, but are assigned at each step based on the verifiability of intermediate reasoning tokens against a knowledge source. This intermediate reward signal provides a denser learning signal, mitigating the reward sparsity common in long-horizon tasks and stabilizing the training process. By rewarding verifiable steps, the framework incentivizes the model to generate more coherent and logically sound reasoning paths, ultimately leading to improved performance on complex tasks requiring multi-step inference. The system relies on external validation of each token’s factual correctness to assign these rewards, ensuring the reasoning process remains grounded and avoids hallucination.
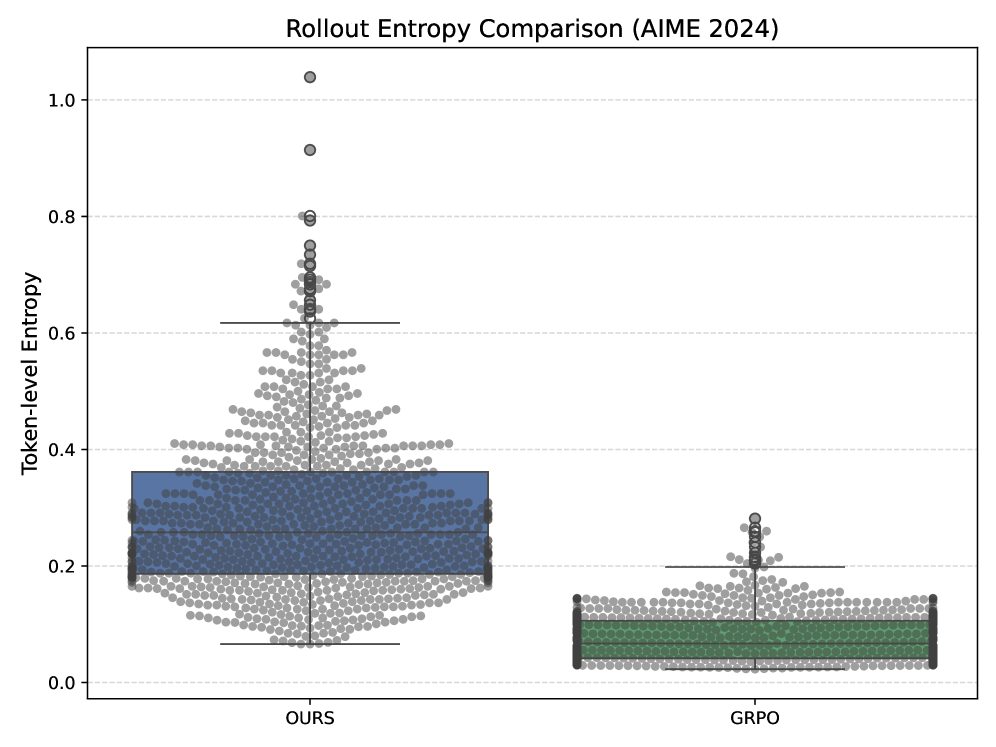
Empirical Evidence: Demonstrating ProGRPO’s Gains
ProGRPO was subjected to empirical validation using both Qwen2.5 and DeepSeek language models to assess its performance characteristics. Testing across these models consistently demonstrated measurable improvements in key performance indicators. Specifically, evaluations confirmed that ProGRPO outperforms existing algorithms on these platforms, indicating a generalizable benefit rather than model-specific optimization. The consistent gains observed across different model architectures provide evidence for the robustness and potential applicability of ProGRPO in diverse language model deployments.
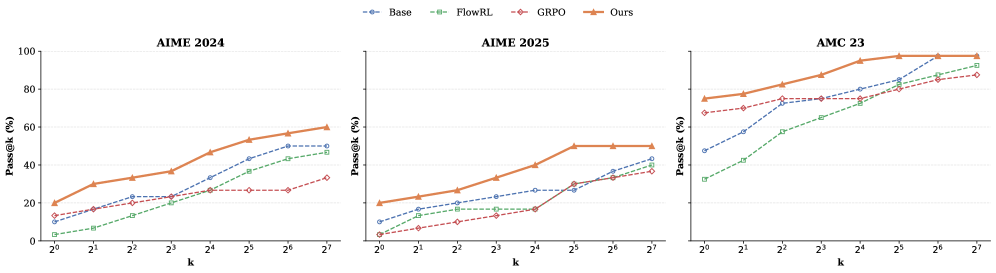
Performance evaluations utilizing the Pass@1 and Pass@32 metrics demonstrate ProGRPO’s superiority over several baseline reinforcement learning algorithms. Specifically, on the Qwen2.5-7B model, ProGRPO achieved a 5.7% improvement in Pass@1 and a 13.9% improvement in Pass@32 when compared to the GRPO algorithm. These gains indicate ProGRPO’s enhanced ability to generate correct outputs with both limited and extended decoding steps, as measured by these pass rate metrics.
ProGRPO demonstrates enhanced Out-of-Distribution (OOD) robustness, indicating its ability to maintain performance levels when applied to data differing from the training distribution. This capability was assessed by evaluating the model on unseen data distributions, and results confirm that ProGRPO’s performance does not significantly degrade when presented with novel inputs. This characteristic is critical for real-world applications where the input data may vary considerably from the data used during training, ensuring reliable and consistent operation even in dynamic environments.
Performance evaluations on the Qwen2.5-7B model demonstrate that ProGRPO achieves a statistically significant improvement over the FlowRL algorithm. Specifically, ProGRPO exhibits an 8.0% increase in Pass@1 and a 7.5% increase in Pass@32 when compared to FlowRL’s performance on the same model. These gains were measured using standard evaluation protocols and indicate an enhanced ability to generate correct outputs with fewer samples, as quantified by the Pass@K metrics.
ProGRPO leverages Curriculum Reinforcement Learning (CRL) to enhance training efficiency. CRL strategically sequences training tasks, beginning with simpler examples and gradually increasing complexity. This approach allows the model to initially establish foundational skills before tackling more challenging scenarios, resulting in faster convergence and improved performance. By optimizing the order in which training data is presented, ProGRPO effectively guides the learning process, enabling it to acquire robust policies with greater sample efficiency compared to standard reinforcement learning techniques.
Beyond Performance: The Implications of a Stable System
ProGRPO presents a tangible advancement in the challenging field of Reinforcement Learning for Large Language Models (LLMs). Existing methods often struggle with erratic reward signals and a tendency for LLMs to converge on limited, repetitive responses – a phenomenon known as Mode Collapse. This framework addresses these core issues by introducing a structured approach to policy optimization, effectively smoothing the learning process and encouraging exploration of a wider range of potential solutions. Through carefully designed reward shaping and a focus on stable policy updates, ProGRPO demonstrably improves both the reliability and the sophistication of LLM behavior, allowing these models to tackle more intricate reasoning tasks with greater consistency and unlock previously unattainable levels of performance.
The alleviation of reward instability and Mode Collapse through ProGRPO is not merely a technical refinement, but a fundamental step toward realizing genuinely complex reasoning in Large Language Models. Reward instability, where learning signals fluctuate wildly, often prevents models from consistently pursuing optimal strategies, while Mode Collapse limits the diversity of generated outputs, stifling creative and thorough exploration of problem spaces. By addressing these core issues, ProGRPO allows models to reliably learn and execute intricate reasoning processes, moving beyond superficial pattern matching to engage in more nuanced analysis and decision-making. This enhanced stability fosters the development of models capable of tackling problems requiring abstract thought, planning, and a deep understanding of context – capabilities essential for building AI systems that can assist with increasingly sophisticated tasks and offer truly insightful solutions.
Researchers anticipate extending the ProGRPO framework beyond its initial application in Large Language Models, investigating its efficacy across diverse complex reasoning challenges such as robotic control and game playing. A key avenue for future development involves integrating ProGRPO with complementary advanced learning techniques – including techniques like imitation learning and meta-learning – to potentially create synergistic effects that further enhance both sample efficiency and generalization capabilities. This combined approach aims not merely to improve performance on existing benchmarks, but to unlock entirely new possibilities for AI systems tackling problems requiring intricate, multi-step reasoning processes, ultimately fostering more robust and adaptable intelligence.
The development of ProGRPO represents a significant step towards building artificial intelligence systems that are not only powerful but also reliably aligned with human values. By addressing core challenges in reinforcement learning – specifically reward instability and mode collapse – this framework fosters more predictable and robust AI behavior. This increased reliability is crucial for deploying AI in sensitive domains such as healthcare, finance, and autonomous systems, where consistent and trustworthy performance is paramount. Ultimately, a foundation of stable learning allows for the creation of AI that consistently pursues intended goals, minimizes unintended consequences, and operates in a manner that benefits society as a whole, moving beyond simply achieving high performance metrics to ensuring genuinely beneficial outcomes.
The pursuit of optimized reasoning in large language models, as demonstrated by ProGRPO, often feels like chasing a phantom. It’s a testament to the inherent tension between exploration and exploitation – a balance perpetually shifting as models grow in complexity. Brian Kernighan observed, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” This resonates deeply with the challenges faced in reinforcement learning; attempts to refine reasoning through advantage re-weighting, while aiming for stability, risk inadvertently limiting the very diversity ProGRPO seeks to cultivate. Scalability, in this context, isn’t merely about handling larger models, but accepting that each architectural choice is a prophecy of future failure-a delicate ecosystem where optimization inevitably yields to the loss of flexibility.
The Path Ahead
The introduction of ProGRPO offers a temporary reprieve, a localized increase in order within the inevitable decay. This algorithm, by attempting to quantify and counteract entropy collapse, doesn’t solve the problem of brittle reasoning in large language models; it merely postpones the manifestation of inherent instability. Each re-weighting of the advantage function is an acknowledgement that confidence, as currently measured, is a poor proxy for genuine understanding, and a temporary shield against the model believing its own fabrication. The true metric remains elusive.
Future iterations will inevitably reveal the limitations of this confidence-based approach. The current focus on generative probabilities, while insightful, risks becoming a self-fulfilling prophecy. A model trained to maximize perceived confidence will, predictably, generate outputs that appear confident, regardless of their grounding in truth or logical coherence. The next challenge isn’t better exploration, but a fundamental rethinking of how ‘understanding’ is represented-and whether it can be reliably extracted from a system built on statistical correlation.
One suspects the field will cycle through increasingly complex methods of nudging these systems towards diversity, each a desperate attempt to delay the moment when the model inevitably converges on a locally optimal, yet ultimately meaningless, pattern. The real work lies not in building better algorithms, but in accepting that these systems are not tools to be perfected, but complex ecosystems destined to evolve-and eventually, to fail in unpredictable ways.
Original article: https://arxiv.org/pdf/2602.05281.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-02-07 20:43